【PyTorch实战】 minibatching,数据加载和模型构建
【导读】在这篇文章中,我们将学习如何使用PyTorch构建一个简单的神经网络并且学习如何使用深度学习来解决二分类问题,也介绍了PyTorch如何定义模型,运行模型等等功能。大家感兴趣的话可以学习一下。
作者 | Conor McDonald
编译 | 专知
参与 | Yingying, Huaiwen
Up and running with PyTorch — minibatching, dataloading and model building
这篇文章介绍了用PyTorch构建一个简单的神经网络(多层感知器)并分类的方法。首先介绍PyTorch的一些基本部分,然后重点阐述如何使用深度学习来学习非线性函数。
第一步当然是安装Pytorch。请注意,这儿使用的是0.3.1.post2.
这篇文章将解决一个二分类问题——将分布为半月形的点进行分类。对于深度学习模型而言,这是一项简单的任务,但它突出了他们学习复杂的非线性函数的能力。
举个例子,如果我们使用逻辑回归对这些数据进行分类,看看会发生什么:
from sklearn.datasets import make_moons
import pandas as pd
import numpy as np
import torch
from torch.autograd import Variable
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
def to_categorical(y, num_classes):
"""1-hot encodes a tensor"""
return np.eye(num_classes, dtype='uint8')[y]
X, y = make_moons(n_samples=1000, noise=.1)
y = to_categorical(y_, 2)

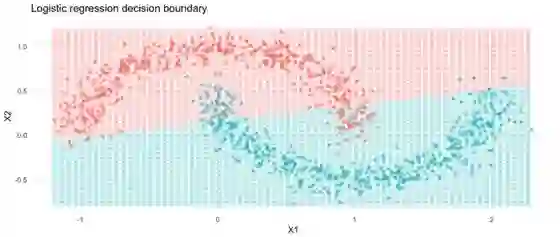
尽管对输出进行了softmax处理,但逻辑回归是线性的,很难处理非线性问题。 我们可以使用更高级的机器学习模型来完成这项任务,比如随机森林,但那我们就学不了神经网络了。
在构建模型之前,我们首先创建自定义数据预处理器和加载器。 在这个例子中,转换器将简单地将训练数据和标签从numpy数组转换为torch张量。 然后,我们将使用dataloader类来处理数据如何通过模型传递。
class PrepareData(Dataset):
def __init__(self, X, y):
if not torch.is_tensor(X):
self.X = torch.from_numpy(X)
if not torch.is_tensor(y):
self.y = torch.from_numpy(y)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
ds = PrepareData(X=X, y=y)
ds = DataLoader(ds, batch_size=50, shuffle=True)
在这里我们将使用mini batch。这意味着,在每一轮,都将在训练数据的一个mini-batch上训练- 也就是说,它将根据与每个小batch相关的损失更新其权重。这通常比每一轮训练全部数据更好。
定义模型
在PyTorch中,定义深度学习模型的标准方法是将网络封装在一个类中。我非常喜欢这种方法,因为它确保所有图层,数据和方法都可以从一个对象访问。这个类的目的是定义网络的结构并管理数据的正向传递。
典型方法是将图层定义为变量。在这种情况下,我们定义一个单层网络。 nn.Linear函数要求输入和输出大小。在第一层,输入大小是特征数量2,输出大小是神经元隐藏层的数量。
class MoonsModel(nn.Module):
def __init__(self, n_features, n_neurons):
super(MoonsModel, self).__init__()
self.hidden = nn.Linear(in_features=n_features,
out_features=n_neurons)
self.out_layer = nn.Linear(in_features=n_neurons,
out_features=2)
def forward(self, X):
out = F.relu(self.hidden(X))
out = F.sigmoid(self.out_layer(out))
return out
输出层的输入是前一层神经元的数量,输出是数据中的目标数量 - 这里是两个。
然后我们定义一个类方法forward来管理通过网络的数据流。在这里,我们调用数据上的图层,并使用隐藏层上的relu激活(来自torch.nn.functional)。最后,我们对输出应用sigmoid变换,以将预测值加总为1。
运行模型
接下来,我们需要定义模型的学习。首先我们从类中实例化一个模型对象,我们称之为model。接下来,我们定义cost函数 - 在这里是二元交叉熵。最后,定义优化器为Adam。优化器将优化模型的参数。
现在我们准备好训练模型了。模型训练将持续50 epochs。我们建立了一个for循环来遍历epochs,并且每个epochs我们循环存储在ds中的mini-batch X和y。在每个循环中,我们将输入和目标 变成torch变量(请注意,在下一个pytorch版本中不需要此步骤,因为torch.tensors和Variables将被合并),然后指定向前和向后传递。
model = MoonsModel(n_features=2, n_neurons=50)
cost_func = nn.BCELoss()
optimizer = tr.optim.Adam(params=model.parameters(), lr=0.01)
num_epochs = 20
losses = []
accs = []
for e in range(num_epochs):
for ix, (_x, _y) in enumerate(ds):
#=========make inpur differentiable=======================
_x = Variable(_x).float()
_y = Variable(_y).float()
#========forward pass=====================================
yhat = model(_x).float()
loss = cost_func(yhat, _y)
acc = tr.eq(yhat.round(), _y).float().mean() # accuracy
#=======backward pass=====================================
optimizer.zero_grad() # zero the gradients on each pass
before the update
loss.backward() # backpropagate the loss through the model
optimizer.step() # update the gradients w.r.t the loss
losses.append(loss.data[0])
accs.append(acc.data[0])
if e % 1 == 0:
print("[{}/{}], loss: {} acc: {}".format(e,
num_epochs, np.round(loss.data[0], 3), np.round(acc.data[0], 3)))
在正向传递中,我们使用模型来预测给定的标签,计算损失(和准确性)。我们只要让网络传递数据即可。 在反向传播中,我们通过模型反向处理损失,优化器根据学习速率更新权重。
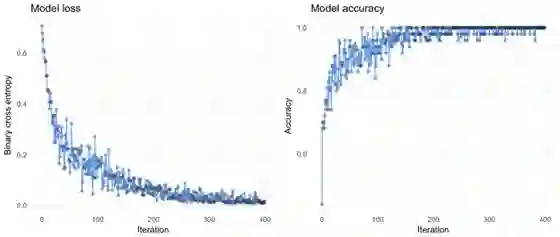
我们可以看到损失迅速下降(波动可以通过小批量解释),这意味着我们的模型没bug。
另外,请查看模型了解的决策区域:
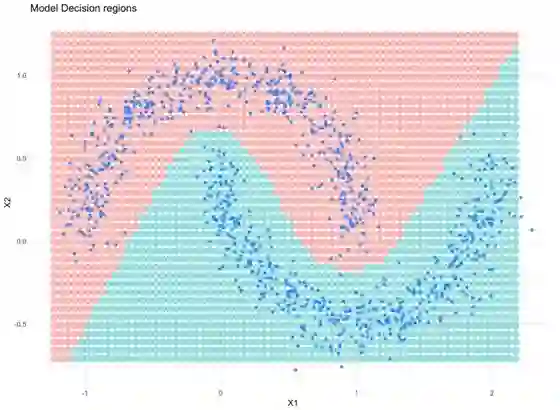
很明显,神经网络可以学习数据的非线性特性!
总结
这篇文章的目的是展示如何用pytorch运行神经网络。 这里定义的模型非常简单,但目的是突出构建模块。
原文链接:
https://towardsdatascience.com/up-and-running-with-pytorch-minibatching-dataloading-and-model-building-7c3fdacaca40
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知




