小于1MB的行人检测网络
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:松菇
https://zhuanlan.zhihu.com/p/76491446
来源:知乎,已获作者授权转载,禁止二次转载。
原始的RFBNet300参数量有36.5 MB,我采用重新设计,削减了channel数目以及卷积数目以及使用1x1卷积,然后对网络进行了从头训练。在模型参数量只有0.99MB时,AP也能达到78。在模型参数量为3.1MB时,AP能达到80,并且速度还可以达到200FPS。
设计原则
从头训练的话,网络设计就比较灵活了,可以自己方便的尝试各种方法,也可以很方便的把最新的论文方法加进去。网络设计主要还是多看论文,看看大佬们怎么做的。推荐的一些文章,自己看感觉很有启发:
《Momenta:让深度学习更高效运行的两个视角 | Paper Reading第二季第一期》
(文章链接:https://zhuanlan.zhihu.com/p/33693725)
《Michael Yuan:Roofline Model与深度学习模型的性能分析》
(文章链接:https://zhuanlan.zhihu.com/p/34204282)
《轻量卷积神经网络的设计》
(文章链接:https://zhuanlan.zhihu.com/p/64400678)
网络设计
主要追求GPU的速度更快,因此也没有去使用分组卷积深度可分离卷积,后面会尝试使用不同的网络设计。整体上与RFB300类似,不过有以下几点不同:
削减VGG的通道数目以及卷积数目,通道数目最多也只有128
原始VGG没有BN,这里加上BN,梯度更加稳定,学习率也可以加大些
使用1x1卷积
RFB模块只使用了一个,稍加修改,没有太多的变体设计,更加简单
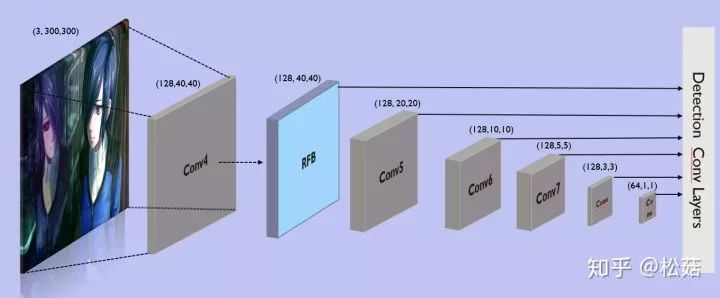
class Backbone(nn.Module):
def __init__(self, bn=True):
super(Backbone, self).__init__()
self.conv1_1 = BasicConv(3, 32, kernel_size=3, padding=1, bn=bn)
self.conv1_2 = BasicConv(32, 32, kernel_size=3, padding=1, bn=bn)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 2
self.conv2_1 = BasicConv(32, 64, kernel_size=3, padding=1, bn=bn)
self.conv2_2 = BasicConv(64, 64, kernel_size=3, padding=1, bn=bn)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 4
self.conv3_1 = BasicConv(64, 128, kernel_size=1, bn=bn)
self.conv3_2 = BasicConv(128, 128, kernel_size=3, padding=1, bn=bn)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=bn) # 8
self.conv4_1 = BasicConv(128, 128, kernel_size=1, bn=bn)
self.conv4_2 = BasicConv(128, 128, kernel_size=3, padding=1, bn=bn) #### f1 ####
self.conv4_3 = BasicRFB(128,128,stride = 1,scale=1.0)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2) # 16
self.conv5_1 = BasicConv(128, 64, kernel_size=1, relu=False, bn=bn)
self.conv5_2 = BasicConv(64, 128, kernel_size=3, padding=1, stride=1, bn=bn) #### f2 ####
self.conv6_1 = BasicConv(128, 64, kernel_size=1, relu=False)
self.conv6_2 = BasicConv(64, 128, kernel_size=3, padding=1, stride=2) #### f3 ####
self.conv7_1 = BasicConv(128, 64, kernel_size=1, relu=False)
self.conv7_2 = BasicConv(64, 128, kernel_size=3, padding=1, stride=2) #### f4 ####
self.conv8_1 = BasicConv(128,64,kernel_size=1, relu=False)
self.conv8_2 = BasicConv(64,128,kernel_size=3) #### f5 ####
self.conv9_1 = BasicConv(128,64,kernel_size=1, relu=False)
self.conv9_2 = BasicConv(64,64,kernel_size=3) #### f6 ####
def forward(self, x):
x = self.conv1_1(x)
x = self.conv1_2(x)
x = self.pool1(x)
x = self.conv2_1(x)
x = self.conv2_2(x)
x = self.pool2(x)
x = self.conv3_1(x)
x = self.conv3_2(x)
x = self.pool3(x)
x = self.conv4_1(x)
x = self.conv4_2(x)
x = self.conv4_3(x)
f1 = x # stride = 8
x = self.pool4(x)
x = self.conv5_1(x)
x = self.conv5_2(x)
f2 = x # stride = 16
x = self.conv6_1(x)
x = self.conv6_2(x)
f3 = x # stride = 32
x = self.conv7_1(x)
x = self.conv7_2(x)
f4 = x # stride = 64
x = self.conv8_1(x)
x = self.conv8_2(x)
f5 = x # -2
x = self.conv9_1(x)
x = self.conv9_2(x)
f6 = x # -2
return f1, f2, f3, f4, f5, f6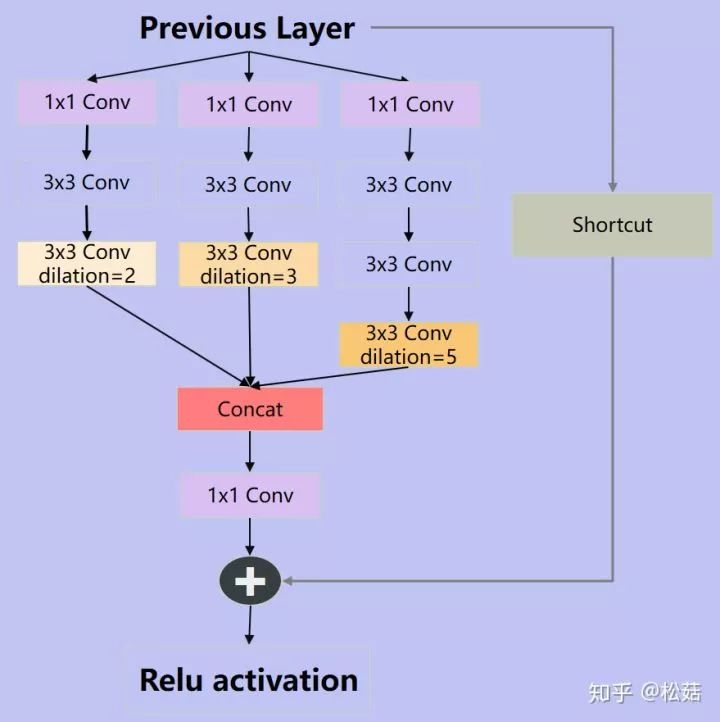
class BasicRFB(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, scale = 0.1, map_reduce=8, vision=1, groups=1):
super(BasicRFB, self).__init__()
self.scale = scale
self.out_channels = out_planes
inter_planes = in_planes // map_reduce
self.branch0 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2 * inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1), groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision+1, dilation=vision+1, relu=False, groups=groups)
)
self.branch1 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2*inter_planes, kernel_size=(3,3), stride=stride, padding=(1,1), groups=groups),
BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=vision + 2, dilation=vision + 2, relu=False, groups=groups)
)
self.branch2 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, (inter_planes//2)*3, kernel_size=3, stride=1, padding=1, groups=groups),
BasicConv((inter_planes//2)*3, 2*inter_planes, kernel_size=3, stride=stride, padding=1, groups=groups),
BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=vision + 4, dilation=vision + 4, relu=False, groups=groups)
)
self.ConvLinear = BasicConv(6*inter_planes, out_planes, kernel_size=1, stride=1, relu=False)
self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)
self.relu = nn.ReLU(inplace=False)
def forward(self,x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0,x1,x2),1)
out = self.ConvLinear(out)
short = self.shortcut(x)
out = out*self.scale + short
out = self.relu(out)
return out总结
如果对精度要求更高,可以将通道数提升到256,AP就可以达到了80,参数量也仅仅只有3.1MB。为了能在GPU运行更快,没有去使用分组卷积深度可分离卷积等等,因此GPU上AP80的情况下,速度可以达到200FPS。后面可能会尝试设计更适合移动端的网络,尝试借鉴使用mobilenet系列和shufflenet系列等等进行设计。大家也可以进行各种尝试,一起交流哈。
代码链接
0.99 MB版本:https://github.com/songwsx/RFSong-779
3.1MB版本:https://github.com/songwsx/RFSong-7993
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



