目标检测中图像增强,mixup 如何操作?
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者信息:同济大学计算机系硕士研究生 费敬敬
来源:知乎
https://www.zhihu.com/question/308572298/answer/585140274
mixup 是目前图像增强的一个小技巧,本文主要探讨了以下问题:
目标检测中图像增强,mixup 是如何操作的?
对于图像的 mixup 很好理解,那对于标签,mixup 是如何操作的?
以下是来自同济大学计算机系的知乎答主费敬敬(Pascal)的回答:
在讲检测之前,我们先看看mixup在图像分类是怎么用的。mixup 源于顶会ICLR的一篇论文 mixup: Beyond Empirical Risk Minimization
(https://arxiv.org/abs/1710.09412),可以在无额外计算开销的情况下稳定提升1个百分点的图像分类精度。

当前,mixup目前主要是用于图像分类,有两种主流的实现方式,我用的好像是GluonCV版本,参考的是这个版本的代码:
https://github.com/tengshaofeng/ResidualAttentionNetwork-pytorch/blob/master/Residual-Attention-Network/train_mixup.py
对于输入的一个batch的待测图片images,我们将其和随机抽取的图片进行融合,融合比例为lam,得到混合张量inputs;
第1步中图片融合的比例lam是[0,1]之间的随机实数,符合beta分布,相加时两张图对应的每个像素值直接相加,即 inputs = lam*images + (1-lam)*images_random;
将1中得到的混合张量inputs传递给model得到输出张量outpus,随后计算损失函数时,我们针对两个图片的标签分别计算损失函数,然后按照比例lam进行损失函数的加权求和,即loss = lam * criterion(outputs, targets_a) + (1 - lam) * criterion(outputs, targets_b);
我觉得这个过程不是很好讲清楚,我们直接看PyTorch版实现代码,代码很好理解:
for i,(images,target) in enumerate(train_loader):
# 1.input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
# 2.mixup
alpha=config.alpha
lam = np.random.beta(alpha,alpha)
index = torch.randperm(images.size(0)).cuda()
inputs = lam*images + (1-lam)*images[index,:]
targets_a, targets_b = target, target[index]
outputs = model(inputs)
loss = lam * criterion(outputs, targets_a) + (1 - lam) * criterion(outputs, targets_b)
# 3.backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step() # update parameters of net我们通过matplotlib来可视化mixup这个过程,二张图片的mixup结果随着lam的变化而发生渐变
for i in range(1,10):
lam= i*0.1
im_mixup = (im1*lam+im2*(1-lam)).astype(np.uint8)
plt.subplot(3,3,i)
plt.imshow(im_mixup)
plt.show()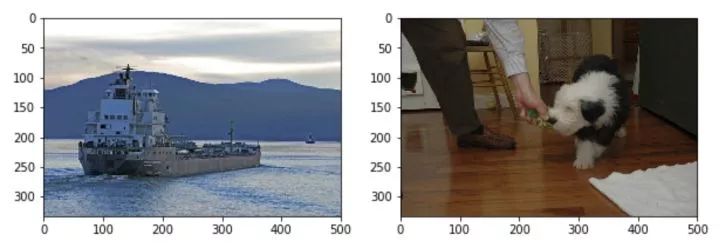

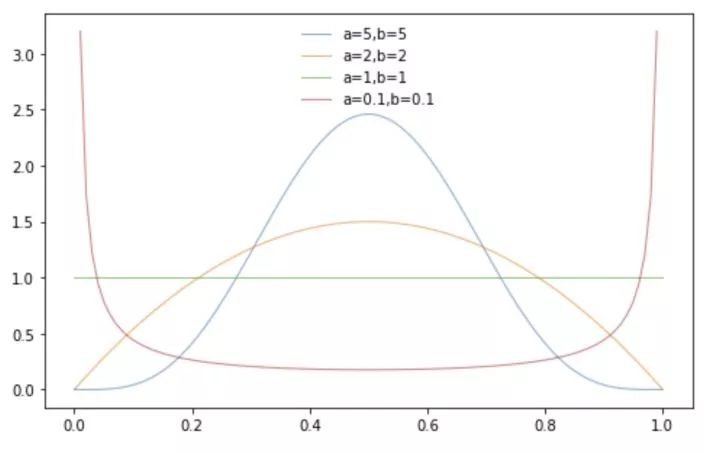
实际代码中的lam由随机数生成器控制,lam符合参数为(alpha,alpha)的beta分布,默认取alpha=1,这里的alpha是一个超参数,比如我遇到的一个情况就是alpha=2效果更好,alpha的值越大,生成的lam偏向0.5的可能性更高。
如上就是图像分类mixup的一个pytorch实现,说完这个我们来看看检测怎么用mixup
对于目标检测的话,如果用上面这种图像mixup融合,损失函数加权相加的方式,我想就不存在标签问题了:图1 和 图2 按照比例lam进行线性融合,然后送入model进行检测分别按标签计算损失函数,然后按照lam加权相加得到最终的损失函数。

实际上,GluonCV中目标检测的mixup实现是这样子的,以下为缩减拼接版本:
class MixupDetection(Dataset): # mixup two images height = max(img1.shape[0], img2.shape[0]) width = max(img1.shape[1], img2.shape[1]) mix_img = mx.nd.zeros(shape=(height, width, 3), dtype='float32') mix_img[:img1.shape[0], :img1.shape[1], :] = img1.astype('float32') * lambd mix_img[:img2.shape[0], :img2.shape[1], :] += img2.astype('float32') * (1. - lambd) mix_img = mix_img.astype('uint8') y1 = np.hstack((label1, np.full((label1.shape[0], 1), lambd))) y2 = np.hstack((label2, np.full((label2.shape[0], 1), 1. - lambd))) mix_label = np.vstack((y1, y2)) return mix_img, mix_labelfrom gluoncv.data.mixup import MixupDetectiontrain_dataset = MixupDetection(train_dataset)def train(net, train_data, val_data, eval_metric, ctx, args): for epoch in range(args.start_epoch, args.epochs): mix_ratio = 1.0 if args.mixup: # TODO(zhreshold) only support evenly mixup now, target generator needs to be modified otherwise train_data._dataset.set_mixup(np.random.uniform, 0.5, 0.5) mix_ratio = 0.5 if epoch >= args.epochs - args.no_mixup_epochs: train_data._dataset.set_mixup(None) mix_ratio = 1.0 for i, batch in enumerate(train_data): with autograd.record(): for data, label, rpn_cls_targets, rpn_box_targets, rpn_box_masks in zip(*batch): # overall losses losses.append(rpn_loss.sum() * mix_ratio + rcnn_loss.sum() * mix_ratio) metric_losses[0].append(rpn_loss1.sum() * mix_ratio) metric_losses[1].append(rpn_loss2.sum() * mix_ratio) metric_losses[2].append(rcnn_loss1.sum() * mix_ratio) metric_losses[3].append(rcnn_loss2.sum() * mix_ratio) add_losses[0].append([[rpn_cls_targets, rpn_cls_targets>=0], [rpn_score]]) add_losses[1].append([[rpn_box_targets, rpn_box_masks], [rpn_box]]) add_losses[2].append([[cls_targets], [cls_pred]]) add_losses[3].append([[box_targets, box_masks], [box_pred]]) autograd.backward(losses)train_data, val_data = get_dataloader( net, train_dataset, val_dataset, args.batch_size, args.num_workers)train(net, train_data, val_data, eval_metric, ctx, args)
我觉得跟我想的是一个意思,但是有些细节还没搞懂,因此没法下个定论。整个代码在图片融合那一块是没啥悬念的,但是标签的融合那一步的额外weights在代码上是怎么被用到的我没搞懂( https://github.com/dmlc/gluon-cv/blob/49be01910a8e8424b017ed3df65c4928fc918c67/gluoncv/data/mixup/detection.py#L74 )。
不管怎样,有几个点是明确的:
图片的融合是很明确的逐像素相加,融合得到的新图的尺寸是取两张图片的中的最大值,也就是说(600,800)和(900,700)两张图融合得到的新图大小是(900,800),新增的部分取零,这一步的意义是确保新图装得下原先的两张图,且不改变检测框的绝对位置;
源代码中的todo注释,表明mixup这一块还没更新完,目前代码中所采用的mixup系数是固定的,就是0.5,并没有随机生成,也就是两张图各占一半权重,从更新日期看这个坑好久没有填了。
mixup相关代码地址贴出来了,欢迎大佬们指正我的错误:
https://github.com/dmlc/gluon-cv/blob/49be01910a8e8424b017ed3df65c4928fc918c67/gluoncv/data/mixup/detection.py#L65
https://github.com/dmlc/gluon-cv/blob/428ee05d7ae4f2955ef00380a1b324b05e6bc80f/scripts/detection/faster_rcnn/train_faster_rcnn.py#L187
文中可视化代码:
https://github.com/pascal1129/CV_Notes/blob/master/codes/mixup.ipynb
*延伸阅读
Anime-InPainting: 基于Edge-Connect的图像修补工具(含大量动漫萌妹子图)
工具|ImagePy:一款基于Python的高扩展性开源图像处理框架
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~



