更深的编码器+更浅的解码器=更快的自回归模型

论文标题:
Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation
论文作者:
Jungo Kasai, Nikolaos Pappas, Hao Peng, James Cross, Noah A. Smith
论文链接:
https://arxiv.org/pdf/2006.10369.pdf
自回归模型一般认为在推理时效率比非自回归模型低得多,但是,简单改进自回归模型编码器和解码器的深度可以使其有更高的“效果-效率”平衡。
本文探究了让Transformer模型的编码器变深,让解码器变浅可以提高推理时的效率,并且丝毫不影响效果。并且,不同的衡量效率的标准也会有所影响。
自回归模型与非自回归模型的效率
自回归模型指在生成文本时,词是一个接一个生成的,所以要生成长度为N的文本,需要经过模型解码器N次。
而非自回归模型则可以一次生成多个甚至所有词,这就减少了经过解码器的次数,从而提高生成的效率。
但是,由于非自回归模型缺乏解码端的依赖性建模,所以一般来说,它们的效果要弱于自回归模型。
过去很多研究都关注设计更好的非自回归模型以提高效果,但鲜有工作研究如何提高自回归模型在推理时的效率。
无论是自回归模型还是非自回归模型,在推理时的效率大都来自于解码端:经过编码器的次数越多,生成同样一句话,效率就越低。
从另一个方面看,如果解码器更小(即层数更少),那么即使是自回归模型,是不是也可以显著提高生成效率呢?
这就是本文要回答的问题:当模型解码器变浅、编码器变深时,模型是否还能在保持原来效果的前提下,提升生成效率。这可以用下面的图表示:
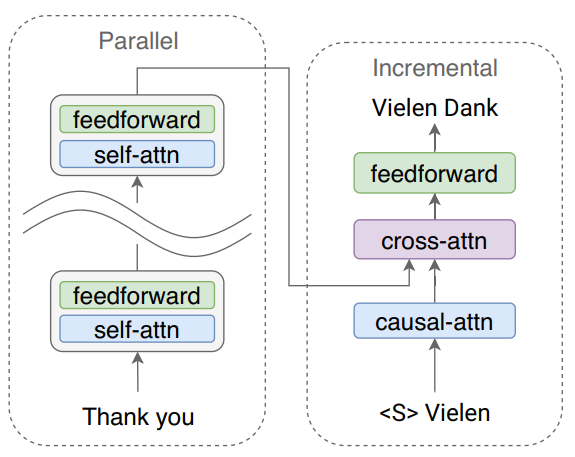
上图是解码器只有一层时的图示,可以看到,由于Transformer模型的解码器每一层都是由三个部分组成,所以多层解码器很显然会降低生成速度。
本文探究了模型效果、效率随编码器和解码器层数变化的情况。
结果发现,对自回归模型而言,令编码器更深、解码器更浅,可以显著提高生成效率且丝毫不影响最终的效果;但对非回归模型而言,更深的解码器则是更好效果的前提。
这个发现启发我们进一步思考自回归模型和非自回归模型如何保持“效果-效率”上的平衡。
计算延时(Latency)的两种方法
在开始实验之前,还需要指出当前比较模型“效率”的方法,即计算延时(Latency)——从数据输入到数据输出经历的时间。
然而,当前也有两种方法计算延时,记为S1和S(max)。S1计算的是生成一个句子所用的平均时间,而S(max)计算的是内存一次所能容纳的最大量句子的平均时间。
对不同的模型而言,这两个标准所得的结果会所有差异,和会在实验部分得到展现。
下面先来从理论上分析自回归和非自回归模型的复杂度。这里非自回归模型采用迭代修改式。
约定N是句子长度(源句子和目标句子都是N),T是非自回归模型的迭代次数,且T < N,E是编码器的层数,D是解码器的层数。下表是不同模型的复杂度:
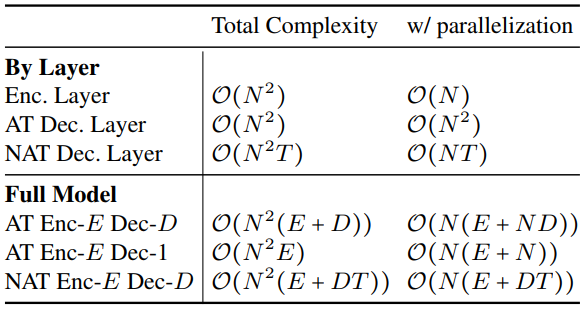
直接看并行化(w/ parallelization)一列。可以看到,自回归(AT)解码器仍然需要平方级的复杂度,而非自回归模型(NAT)解码器的复杂度仅是O(NT),低于N^2。
在可以并行化的条件下,S1更多地被并行化支配。那么在有D层解码器的情况下,非自回归模型就比自回归模型有显著的复杂度优势(前者是NDT,后者是NND)。
如果二者都只有一层解码器,即D=1,那么二者的复杂度差异就会缩小(前者是NT,后者是NN)。
而S(max)更多和Total Complexity相关,这时候,每个词,无论是自回归还是非自回归,都要和已经生成的词进行计算,非自回归的优势就无法体现。
实验
下面我们重点看一下实验部分,探究解码器深度对两种模型效果、效率以及它们之间平衡的影响。
自回归模型是Transoformer-Base,非自回归模型有CMLM、DisCo。
数据集有WMT14 EN-DE (4.5M pairs), WMT16 EN-RO (610K), WMT17 EN-ZH (20M)和WMT14 ENFR (36M, EN→FR only),而计算效率则用S1和S(max)两种。
首先来看这几个模型在不同编码器深度(E)和解码器深度(D)上的效果和效率,如下图所示:
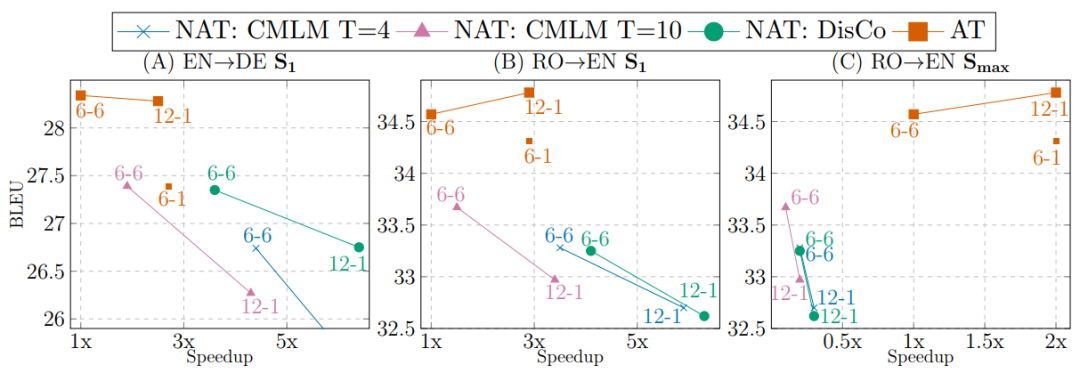
从图(A)和图(B)来看,加深自回归模型编码器、变浅其解码器可以在不损失效果的情况下获得显著的加速(2x-3x),但是如果不加深编码器只变浅解码器会让效果变差(图中6-1)。
另一方面,对非自回归模型而言,加深编码器变浅解码器也会提高效率,但是同时也会显著降低效果。
从图(C)来看,S(max)的效率评价指标对自回归模型更有利,但是加深编码器变浅解码器后的趋势变化和前两个图是相同的。
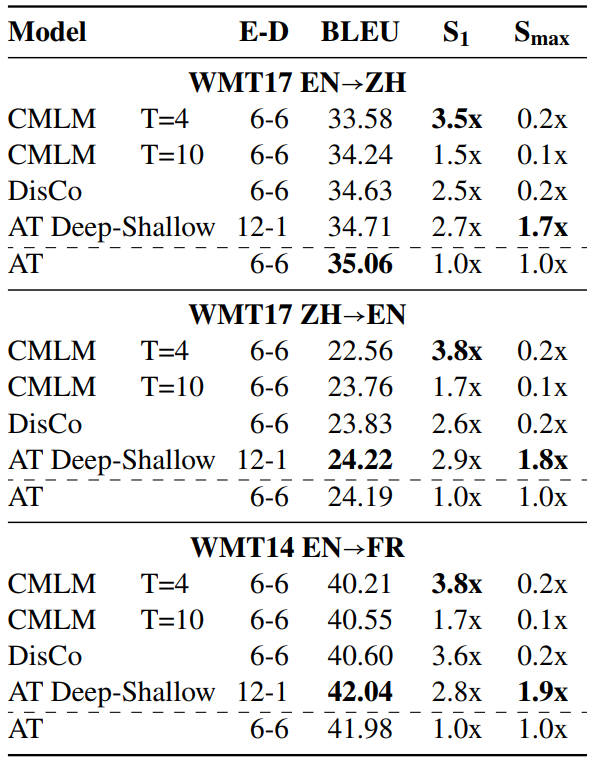
下表是详细的结果数据,可以看到,AT Deep-Shallow在效果上和AT没有差别,但是在S1上速度提高了3倍,在S(max)上提高了近2倍。即使是在S1上,改进后的AT模型已经很接近非自回归模型CMLM了。
那么在同样的latency下,进一步增大非自回归模型能否超过AT模型的效果呢?答案是否定的,如下图所示。
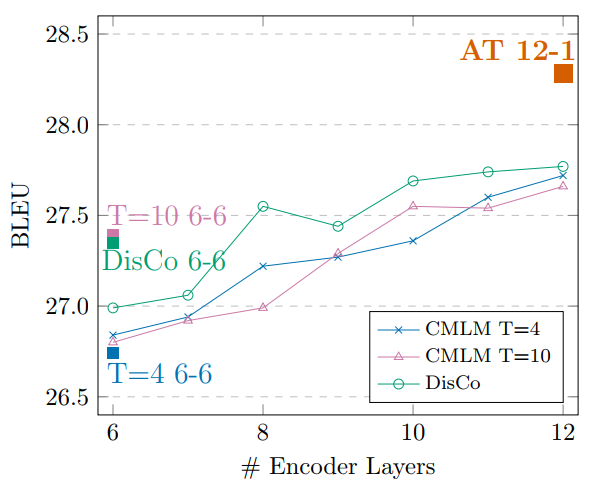
下图是以AT 12-1的Latency为基准,考察不同非自回归模型不同深度的编码器的效果(尽可能多地加深解码器以达到Latency约束)。
可以看到,加深编码器可以提高非自回归模型的效果,但是始终不能达到AT 12-1的结果,这也说明了当前非自回归模型在本质上和自回归模型的差异。
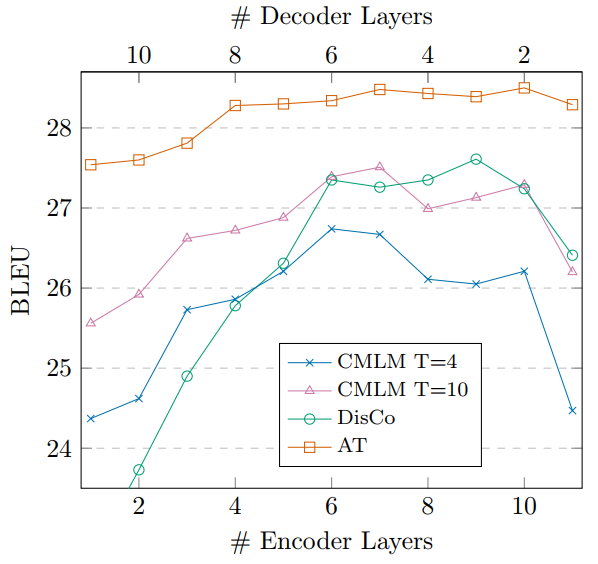
另一个问题是,在E+D为常数的情况下,怎样分配E和D才能使得效果最好。结果如下图所示。
对自回归模型而言,当编码器大于4层的时候效果就已经很好了,而对非自回归模型而言,E和D保持平衡可以取得最好的结果。
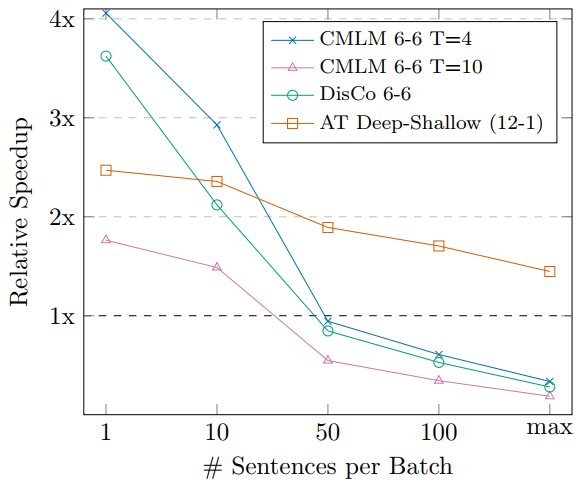
最后来看看批量大小和效率之间的关系,结果如下图所示。可以看到,当一个batch中句子越多的时候,AT 12-1相比非自回归模型就更有优势,这在我们的第二节已经分析过了,这是因为Batch越大,模型复杂度就和total complexity越接近,因而非自回归模型就相对更慢。
小结
本文详细探究了自回归模型、非自回归模型不同深度的编码器和解码器对最终效果和效率的影响,发现仅用一层解码器和更深的编码器就可以大大提高自回归模型的效率,并且保持效果不变。
同时,本文还比较了两种计算Latency方法对不同模型的影响。如何分配层数、如何更科学地计算延时,都需要进一步讨论和研究。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






