干货 | 如何从编码器和解码器两方面改进生成式句子摘要?

编者按:文本自动摘要是自然语言处理研究中重要的组成部分之一,如何才能获得高质量的摘要文本是许多研究者非常关心的问题。本文中,哈尔滨工业大学—微软亚洲研究院联合培养博士生周青宇向大家讲述了他是如何从编码器和解码器两方面改进生成式句子摘要的。一起来学习一下吧!
线上分享视频回顾
(以下为周青宇分享的文字整理)
我们本次的主题是从编码器端和解码器端来改进生成式句子摘要,我将主要从以下三个部分来向大家进行讲解:
一、对背景知识、句子摘要和一些相关工作的介绍。
二、介绍一下如何从编码器端改进生成式句子摘要。
三、介绍一下如何从解码器端改进生成式句子摘要。

背景介绍
文本自动摘要是指给出一段文本,我们从中提取出要点,然后再形成一个短的概括性的文本。
文本自动摘要可以分成不同的种类。按照输入文本的类别来分,输入最短的是句子摘要,输入稍微长一点的是单文档级的摘要,在单文档级别摘要之上还有多文档的摘要。
除了按照输入文档的类别来分,文本自动摘要还可以按照产生摘要的方式划分为抽取式摘要和生成式摘要。抽取式摘要,顾名思义就是从原始文本中原封不动地抽取单词或句子,来形成一个摘要。而生成式摘要比较接近于我们先理解文本内容,然后再自己写出一段话来对给定的文本进行概括的一种方式。除此之外,我们还可以从其它角度来划分,比如有query focused的摘要,它给定一个查询,系统给出这个文档针对这个查询的摘要。针对不同的查询,系统可以给出不同的摘要。

接下来,我分别简单介绍一下抽取式和生成式摘要。
抽取式摘要主要是做一个序列标注的任务,相当于我们对句子中的每个词进行0、1的分类。比如标1就是把这个词选下来,这样就可以用抽取式的方法从句子中抽一些重点的词,再将这些重点词作为句子的摘要。句子摘要过去常被叫做句子压缩,用于文档摘要中。
那要怎么用呢?在抽取文档摘要时,我们可能会抽取出一个比较长的句子,然后采用句子压缩的方法把这个句子“剪短”。把句子“剪短”有什么好处呢?在过去的DUC任务中,文档对于输出摘要的长度有所限制,如果选一个特别长的句子达到了它的长度限制,后面就无法选更多的句子了。通过使用句子压缩的办法,就可以为接下来选择更多句子留下更多空间。
生成式摘要基本上都是基于序列到序列(Sequence-to-Sequence)模型的。带注意力模型的Sequence-to-Sequence的编码器就是一个双向的GRU,或者是双向的LSTM,可以将输入的句子进行编码。在解码的时候,它也是由一个GRU或者是LSTM作为一个解码器。这个注意力机制实际上是一个匹配的算法,它可以将当前解码器的状态和输入句子中隐藏的状态进行匹配。

随着深度学习的发展,近几年生成式摘要的研究获得了较多关注,今天我们也主要关注生成式的方法。
如何从编码器端改进生成式的句子摘要
首先介绍一下我们如何从编码器端改进生成式句子摘要。这是我们2017年在ACL上的一个工作,今天介绍的工作也都是我在微软亚洲研究院实习期间完成的。
如此前所说,生成式句子摘要是一个序列到序列的模型。之前很多人的相关工作都采用了注意力机制,这个注意力机制实际上提供了一个词对齐的信息,就是从输出端的词到输入端的词中间有一个对齐的表,比如说“我们”就对齐到“we”。但是我们认为在摘要这个过程中,除了被抽取出来的那些原封不动的拷贝词,剩下的词不存在这样一个词对齐的关系,因为对于这些词并没有可以对齐的地方

另外,之前一些模型其实都没有对摘要这个任务进行一些建模。我们可以考虑一下为什么要做摘要?做摘要的目的是要抽取出输入中比较重要的部分。基于这一点,我们提出了一个模型,它能决定输入中哪个词是重要的。
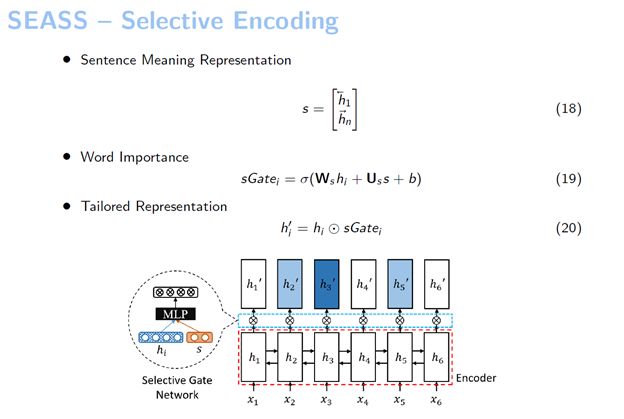
我们提出的这个模型叫“选择性编码模型”,它对输入句子中的每个词都会进行建模,这个建模的方法是基于一个已经编码好的句子,我们利用这个句子的信息来判断句中的词是否重要,由此来构建一个输入句子中词的新的表示。我们把这样一个选择的过程称之为选择性编码,而这个模型就叫做“选择性编码模型”。

首先,我们看一下这个模型的框架,它还是一个基于序列到序列的模型。区别在于我们提出了选择性门网络,它选择输入句子当中哪一部分是重要的。例如我们的模型示例图中画了6个词。读了一遍句子之后,我们可以感觉到这个句子中的哪些词比较重要,然后就由这个网络来判定句子中哪些词比较重要,由此我们对这6个词分别构建出来一个新的表示。接下来我们使用了一个解码器,但不是基于它原始的表示,而是基于我们新构建的这一层表示来进行解码的。
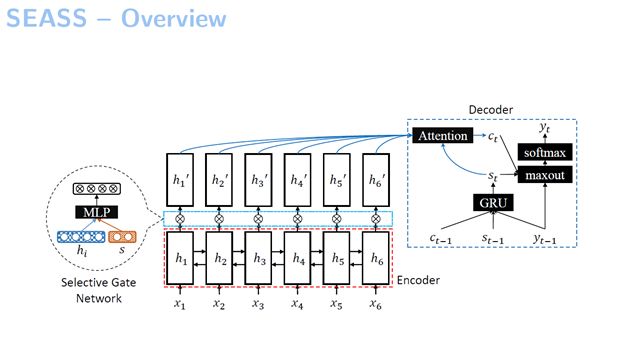
这个模型当中的第一层的基础编码器实际上跟之前序列到序列的模型一样,使用一个GRU来作为我们的RNN。这个解码器跟机器翻译当中的解码器差不多,但不同的点在于它用来解码的这些向量表示不是我们解码器直接给出来的,而是通过选择性编码给出来的。我们先读完一个句子,知道它的意思,然后构造出来这个句子含义的表示。在这里我们采取了一种最简单的方法——将双向GRU的正向最后一个隐藏和反向最后一个隐藏给拼起来,也就是h1和hn它的正向和反向拼起来,把这个作为整个句子含义的表示。有了这个句子的含义表示,我们就可以根据这个句子的含义表示来选择输入的词,从而判断这个句子中的哪个词更重要。
如何从解码器端改进生成式的句子摘要
那我们从解码器端该怎么改进呢?这个是我们发表在今年AAAI上的一篇文章,叫做“Sequential Copying Networks”,改进了一下现在的CopyNet。如果大家感兴趣的话可以在这个网址上下载poster:
https://res.qyzhou.me/AAAI2018_poster.pdf
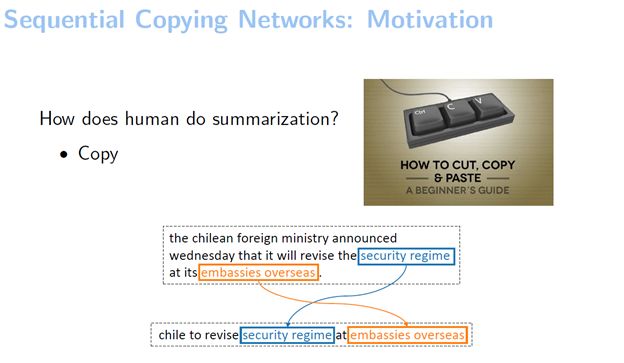
人在做句子摘要的时候会先读句子,然后选重点词,然后把它写下来。人在写的时候是怎么样写的呢?其实可以用一个记号笔把重要的部分直接copy过来。我们给了一个在Gigaword这个数据集上找的例子,可以看到它拷贝的部分是比较多的,比如说把“安全机制”、“海外大使馆”两个词都拷贝了过来。
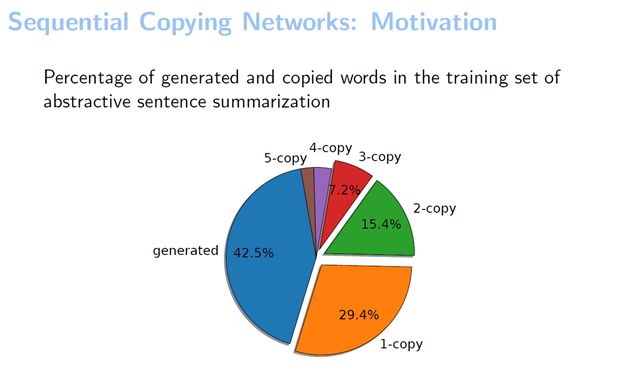
我们推测在生成句子摘要的时候拷贝的地方会比较多。然后想在数据集上统计一下这个推测是否是正确的,所以就在Gigaword这个训练集上统计了一下生成词和拷贝词的百分比。可以看到生成的词占了42.5%,剩下的词全都是拷贝出来的。我们还分别统计了拷贝一个词、拷贝两个词和拷贝三个词的情况。可以看到,拷贝两个词以上的拷贝大概能占到三分之一。这其实也验证了我们的观点,序列拷贝在很多任务中都是存在的。
基于这个观察,我们就提出了一个序列拷贝模型。序列拷贝模型要做的事情比较简单,它是在序列到序列模型当中将序列化的拷贝结合进来。
这是我们模型整个的总览。可以看到它也是由一个编码器和解码器构成的,在解码器的阶段会有一个拷贝的操作。在之前的拷贝模型中,由于每次拷贝都要有一个决策的过程——拷贝还是不拷贝,如果要拷贝三个词,机器就要做三个决策,有可能在中间的某一次决策中它犯错了,或者它这次没有选择拷贝,它选择了生成,或者它拷贝错了,这种情况下就可能导致这三个连续的词没有被拷贝过来。而我们的方法是如果机器决定要拷贝了,则直接拷贝一段。比如说三个词,直接把这三个词整个拷贝过来,这样就省去了要做三次决策的过程。
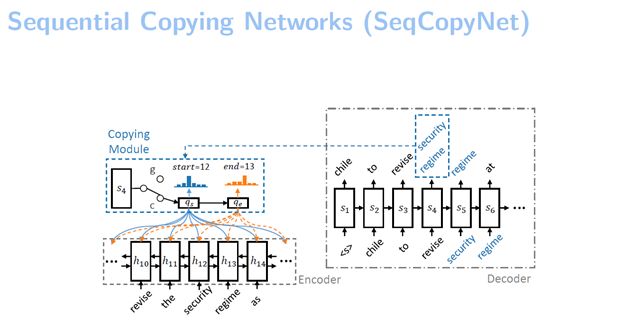
细致一点来介绍,我们的模型主要是做一个片断的选择,用三个模块来做这个片断的预测。
第一,我们做了一个门,这个门是用来控制是否要拷贝的,它会产生一个在0、1之间的概率值来决定当前是拷贝还是不拷贝。
第二,我们做了一个pointer network,我们用这个pointer network来选择要拷贝的这个词组的起始位置和结束位置。
第三,我们设计了一个copy state transducer。它的主要作用是帮助pointer network来进行一个片断的选择。

首先我们定义了一个解码器的状态。这个状态包含很多信息,比如前一时刻的词、当前时刻的上下文等。利用这个状态,我们来预测拷贝的概率。这个G是一个MLP,我们用一个MLP来把这个mt映射到一个实数,在MLP后面加了一个sigmoid函数,来预测当前拷贝的概率。生成的概率很自然的就是1减去这个拷贝的概率。
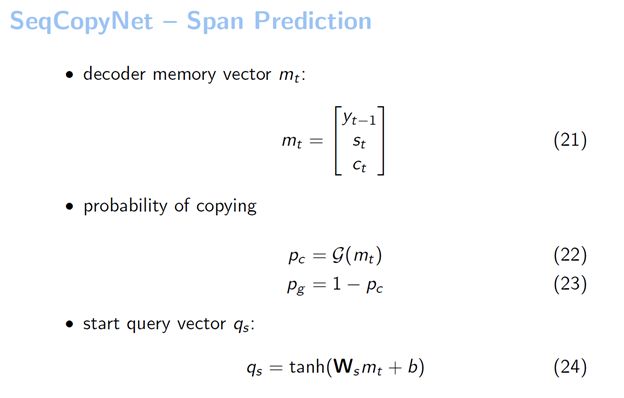
有了概率之后,我们就可以进行预测了。假如说模型目前是拷贝模式,我们就要预测到底拷贝了哪个片断出来。第一步就是要选择拷贝片断的起始位置,我们是通过下面这个方式算的。先构建了一个起始位置查询的向量,叫qs。qs就是把解码器当前定义的状态过了一个MLP,我们获得了这样一个起始位置的查询向量qs。
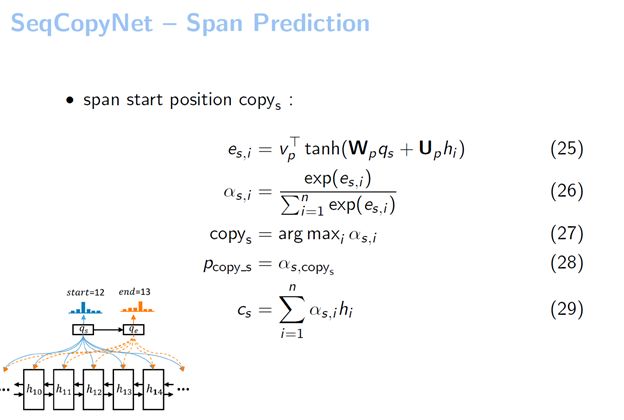
有了qs之后,我们直接把它作为一个pointer network的输入。在整个句子中做了一个Attention,可以看到COPYs是取概率最大的位置。从这个图例中我们看到系统用qs在输入当中进行了一个Attention,最大的位置我们假设是12,它就选择出来COPY的起始位置是12。
接下来要预测这个片断结尾的位置。我们构建了一个结尾位置的查询向量叫qe。这个qe的构建方法就用到了刚才提到的copy state transducer。它的作用实际上是把qs转到qe。为什么要把qs转到qe呢?因为它在预测起始位置和预测结束位置的时候,结束位置肯定是要考虑到初始位置的一些信息以及当前解码器的信息,它才能根据当前解码器的状态以及选择的起始位置来选择一个正确的结束位置,进而把这个正确的片断选择出来。
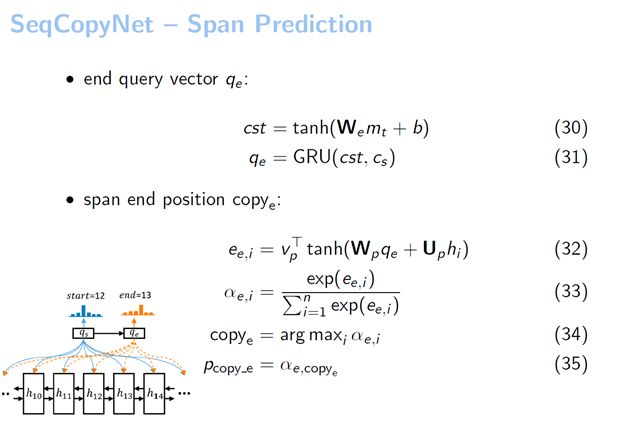
我们在这个地方使用了一个GRU来实现copy state transducer。将预测开始位置的上下文向量cs,作为GRU的输入。这个GRU的起始状态是用一个MLP进行初始化的,这个初始化的输入是解码器的状态mt。通过这两种方式,我们就获得了结束位置的查询向量qe。得到结束位置的查询向量之后,再采用与预测开始位置相同的方法即可得到结束位置。
总结一下,我们在序列到序列的模型基础上引入了序列拷贝机制。与之前的CopyNet相比,我们提出的SeqCopyNet则可以进行多个词的拷贝。在这个过程中并不需要多步拷贝,而是一步拷贝,这样可以减少一些在拷贝过程中由于进行多次决策来引入的错误。除此之外,我们还发现一些比较有趣的现象,就是我们的SeqCopyNet模型在检测边界方面也有着很好的表现。
关于生成式句子摘要,你有不同的想法或者问题么?欢迎在评论区跟我们留言互动!
你也许还想看:
● 干货 | NIPS 2017线上分享:利用价值网络改进神经机器翻译

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。





