DeepMind提图像生成的递归神经网络DRAW,158行Python代码复现

【导读】最近,谷歌 DeepMInd 发表论文( DRAW: A Recurrent Neural Network For Image Generation),提出了一个用于图像生成的递归神经网络,该系统大大提高了 MNIST 上生成模型的质量。为更加深入了解 DRAW,本文作者基于 Eric Jang 用 158 行 Python 代码实现该系统的思路,详细阐述了 DRAW 的概念、架构和优势等。
首先我们先解释一下 DRAW 的概念吧
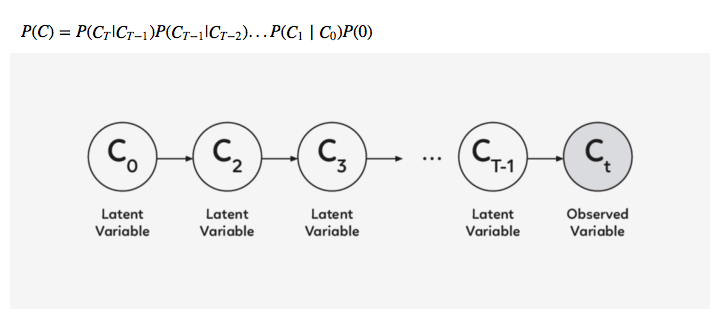
DRAW 的架构
DRAW 与其他自动解码器的三大区别
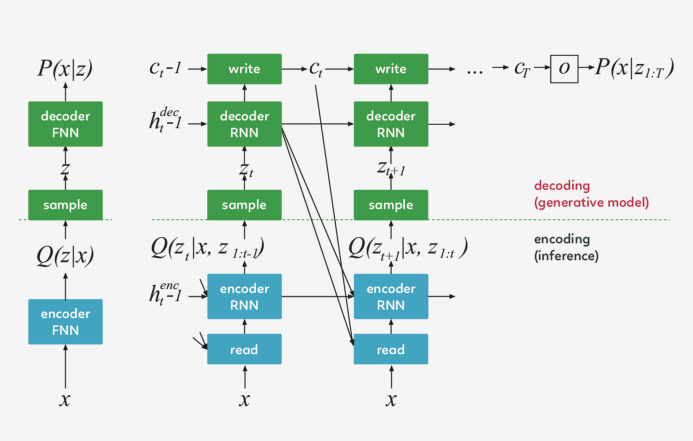
左:传统变分自动编码器
右:DRAW网络
损失函数
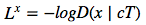
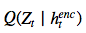 的潜在损失
的潜在损失
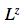 被定义为源自
被定义为源自
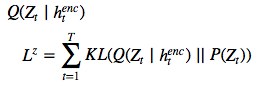 的潜在先验 P(Z_t)的简要 KL散度。
的潜在先验 P(Z_t)的简要 KL散度。
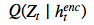 绘制的潜在样本 z_t ,因此其反过来又决定了输入 x。如果潜在 distribution是一个
绘制的潜在样本 z_t ,因此其反过来又决定了输入 x。如果潜在 distribution是一个
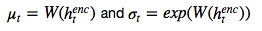 这样的 diagonal Gaussian ,P(Z_t) 便是一个均值为 0,且具有标准离差的标准 Gaussian,这种情况下方程则变为
这样的 diagonal Gaussian ,P(Z_t) 便是一个均值为 0,且具有标准离差的标准 Gaussian,这种情况下方程则变为
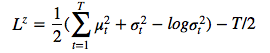 。
。
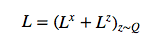
改善图片
DRAW模型的实际应用
好吧,那么它是如何工作的呢?
选择图像的重要部分
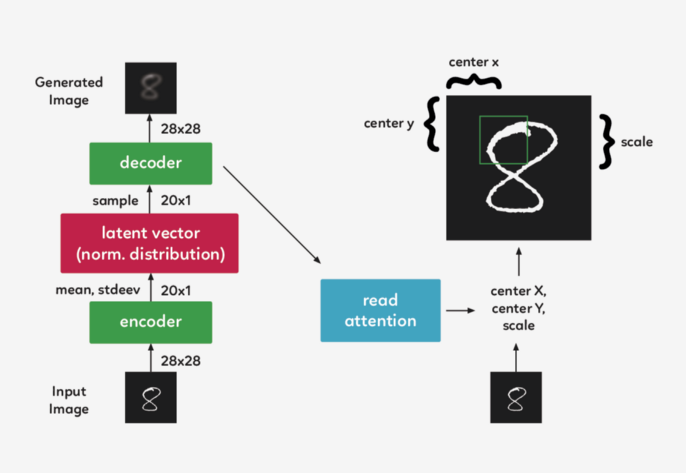
裁剪图像
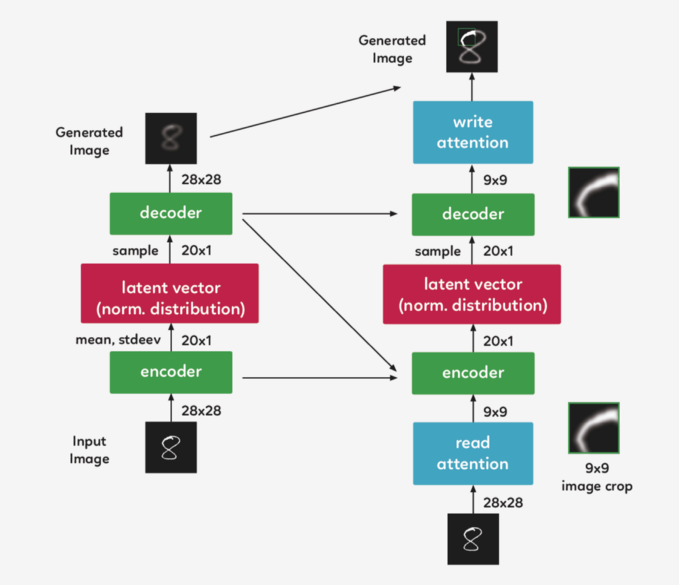
实际应用便是如此吗?
代码一览
# first we import our librariesimport tensorflow as tffrom tensorflow.examples.tutorials import mnistfrom tensorflow.examples.tutorials.mnist import input_dataimport numpy as npimport scipy.miscimport os
# fully-conected layerdef dense(x, inputFeatures, outputFeatures, scope=None, with_w=False): with tf.variable_scope(scope or "Linear"): matrix = tf.get_variable("Matrix", [inputFeatures, outputFeatures], tf.float32, tf.random_normal_initializer(stddev=0.02)) bias = tf.get_variable("bias", [outputFeatures], initializer=tf.constant_initializer(0.0)) if with_w: return tf.matmul(x, matrix) + bias, matrix, bias else: return tf.matmul(x, matrix) + bias
# merge imagesdef merge(images, size): h, w = images.shape[1], images.shape[2] img = np.zeros((h * size[0], w * size[1])) for idx, image in enumerate(images): i = idx % size[1] j = idx / size[1] img[j*h:j*h+h, i*w:i*w+w] = image return img
# save image on local machine def ims(name, img): # print img[:10][:10] scipy.misc.toimage(img, cmin=0, cmax=1).save(name)
# DRAW implementationclass draw_model(): def __init__(self): # First we download the MNIST dataset into our local machine. self.mnist = input_data.read_data_sets("data/", one_hot=True) print "------------------------------------" print "MNIST Dataset Succesufully Imported" print "------------------------------------" self.n_samples = self.mnist.train.num_examples
# We set up the model parameters # ------------------------------ # image width,height self.img_size = 28 # read glimpse grid width/height self.attention_n = 5 # number of hidden units / output size in LSTM self.n_hidden = 256 # QSampler output size self.n_z = 10 # MNIST generation sequence length self.sequence_length = 10 # training minibatch size self.batch_size = 64 # workaround for variable_scope(reuse=True) self.share_parameters = False # Build our model self.images = tf.placeholder(tf.float32, [None, 784]) # input (batch_size * img_size) self.e = tf.random_normal((self.batch_size, self.n_z), mean=0, stddev=1) # Qsampler noise self.lstm_enc = tf.nn.rnn_cell.LSTMCell(self.n_hidden, state_is_tuple=True) # encoder Op self.lstm_dec = tf.nn.rnn_cell.LSTMCell(self.n_hidden, state_is_tuple=True) # decoder Op
# Define our state variables self.cs = [0] * self.sequence_length # sequence of canvases self.mu, self.logsigma, self.sigma = [0] * self.sequence_length, [0] * self.sequence_length, [0] * self.sequence_length
# Initial states h_dec_prev = tf.zeros((self.batch_size, self.n_hidden)) enc_state = self.lstm_enc.zero_state(self.batch_size, tf.float32) dec_state = self.lstm_dec.zero_state(self.batch_size, tf.float32)
# Construct the unrolled computational graph x = self.images for t in range(self.sequence_length): # error image + original image c_prev = tf.zeros((self.batch_size, self.img_size**2)) if t == 0 else self.cs[t-1] x_hat = x - tf.sigmoid(c_prev) # read the image r = self.read_basic(x,x_hat,h_dec_prev) #sanity check print r.get_shape() # encode to guass distribution self.mu[t], self.logsigma[t], self.sigma[t], enc_state = self.encode(enc_state, tf.concat(1, [r, h_dec_prev])) # sample from the distribution to get z z = self.sampleQ(self.mu[t],self.sigma[t]) #sanity check print z.get_shape() # retrieve the hidden layer of RNN h_dec, dec_state = self.decode_layer(dec_state, z) #sanity check print h_dec.get_shape() # map from hidden layer self.cs[t] = c_prev + self.write_basic(h_dec) h_dec_prev = h_dec self.share_parameters = True # from now on, share variables
# Loss function self.generated_images = tf.nn.sigmoid(self.cs[-1]) self.generation_loss = tf.reduce_mean(-tf.reduce_sum(self.images * tf.log(1e-10 + self.generated_images) + (1-self.images) * tf.log(1e-10 + 1 - self.generated_images),1))
kl_terms = [0]*self.sequence_length for t in xrange(self.sequence_length): mu2 = tf.square(self.mu[t]) sigma2 = tf.square(self.sigma[t]) logsigma = self.logsigma[t] kl_terms[t] = 0.5 * tf.reduce_sum(mu2 + sigma2 - 2*logsigma, 1) - self.sequence_length*0.5 # each kl term is (1xminibatch) self.latent_loss = tf.reduce_mean(tf.add_n(kl_terms)) self.cost = self.generation_loss + self.latent_loss # Optimization optimizer = tf.train.AdamOptimizer(1e-3, beta1=0.5) grads = optimizer.compute_gradients(self.cost) for i,(g,v) in enumerate(grads): if g is not None: grads[i] = (tf.clip_by_norm(g,5),v) self.train_op = optimizer.apply_gradients(grads)
self.sess = tf.Session() self.sess.run(tf.initialize_all_variables()) # Our training function def train(self): for i in xrange(20000): xtrain, _ = self.mnist.train.next_batch(self.batch_size) cs, gen_loss, lat_loss, _ = self.sess.run([self.cs, self.generation_loss, self.latent_loss, self.train_op], feed_dict={self.images: xtrain}) print "iter %d genloss %f latloss %f" % (i, gen_loss, lat_loss) if i % 500 == 0:
cs = 1.0/(1.0+np.exp(-np.array(cs))) # x_recons=sigmoid(canvas)
for cs_iter in xrange(10): results = cs[cs_iter] results_square = np.reshape(results, [-1, 28, 28]) print results_square.shape ims("results/"+str(i)+"-step-"+str(cs_iter)+".jpg",merge(results_square,[8,8])) # Eric Jang's main functions # -------------------------- # locate where to put attention filters on hidden layers def attn_window(self, scope, h_dec): with tf.variable_scope(scope, reuse=self.share_parameters): parameters = dense(h_dec, self.n_hidden, 5) # center of 2d gaussian on a scale of -1 to 1 gx_, gy_, log_sigma2, log_delta, log_gamma = tf.split(1,5,parameters)
# move gx/gy to be a scale of -imgsize to +imgsize gx = (self.img_size+1)/2 * (gx_ + 1) gy = (self.img_size+1)/2 * (gy_ + 1)
sigma2 = tf.exp(log_sigma2) # distance between patches delta = (self.img_size - 1) / ((self.attention_n-1) * tf.exp(log_delta)) # returns [Fx, Fy, gamma] return self.filterbank(gx,gy,sigma2,delta) + (tf.exp(log_gamma),) # Construct patches of gaussian filters def filterbank(self, gx, gy, sigma2, delta): # 1 x N, look like [[0,1,2,3,4]] grid_i = tf.reshape(tf.cast(tf.range(self.attention_n), tf.float32),[1, -1]) # individual patches centers mu_x = gx + (grid_i - self.attention_n/2 - 0.5) * delta mu_y = gy + (grid_i - self.attention_n/2 - 0.5) * delta mu_x = tf.reshape(mu_x, [-1, self.attention_n, 1]) mu_y = tf.reshape(mu_y, [-1, self.attention_n, 1]) # 1 x 1 x imgsize, looks like [[[0,1,2,3,4,...,27]]] im = tf.reshape(tf.cast(tf.range(self.img_size), tf.float32), [1, 1, -1]) # list of gaussian curves for x and y sigma2 = tf.reshape(sigma2, [-1, 1, 1]) Fx = tf.exp(-tf.square((im - mu_x) / (2*sigma2))) Fy = tf.exp(-tf.square((im - mu_x) / (2*sigma2))) # normalize area-under-curve Fx = Fx / tf.maximum(tf.reduce_sum(Fx,2,keep_dims=True),1e-8) Fy = Fy / tf.maximum(tf.reduce_sum(Fy,2,keep_dims=True),1e-8) return Fx, Fy
# read operation without attention def read_basic(self, x, x_hat, h_dec_prev): return tf.concat(1,[x,x_hat])
# read operation with attention def read_attention(self, x, x_hat, h_dec_prev): Fx, Fy, gamma = self.attn_window("read", h_dec_prev) # apply parameters for patch of gaussian filters def filter_img(img, Fx, Fy, gamma): Fxt = tf.transpose(Fx, perm=[0,2,1]) img = tf.reshape(img, [-1, self.img_size, self.img_size]) # apply the gaussian patches glimpse = tf.batch_matmul(Fy, tf.batch_matmul(img, Fxt)) glimpse = tf.reshape(glimpse, [-1, self.attention_n**2]) # scale using the gamma parameter return glimpse * tf.reshape(gamma, [-1, 1]) x = filter_img(x, Fx, Fy, gamma) x_hat = filter_img(x_hat, Fx, Fy, gamma) return tf.concat(1, [x, x_hat])
# encoder function for attention patch def encode(self, prev_state, image): # update the RNN with our image with tf.variable_scope("encoder",reuse=self.share_parameters): hidden_layer, next_state = self.lstm_enc(image, prev_state)
# map the RNN hidden state to latent variables with tf.variable_scope("mu", reuse=self.share_parameters): mu = dense(hidden_layer, self.n_hidden, self.n_z) with tf.variable_scope("sigma", reuse=self.share_parameters): logsigma = dense(hidden_layer, self.n_hidden, self.n_z) sigma = tf.exp(logsigma) return mu, logsigma, sigma, next_state def sampleQ(self, mu, sigma): return mu + sigma*self.e # decoder function def decode_layer(self, prev_state, latent): # update decoder RNN using our latent variable with tf.variable_scope("decoder", reuse=self.share_parameters): hidden_layer, next_state = self.lstm_dec(latent, prev_state)
return hidden_layer, next_state
# write operation without attention def write_basic(self, hidden_layer): # map RNN hidden state to image with tf.variable_scope("write", reuse=self.share_parameters): decoded_image_portion = dense(hidden_layer, self.n_hidden, self.img_size**2) return decoded_image_portion # write operation with attention def write_attention(self, hidden_layer): with tf.variable_scope("writeW", reuse=self.share_parameters): w = dense(hidden_layer, self.n_hidden, self.attention_n**2) w = tf.reshape(w, [self.batch_size, self.attention_n, self.attention_n]) Fx, Fy, gamma = self.attn_window("write", hidden_layer) Fyt = tf.transpose(Fy, perm=[0,2,1]) wr = tf.batch_matmul(Fyt, tf.batch_matmul(w, Fx)) wr = tf.reshape(wr, [self.batch_size, self.img_size**2]) return wr * tf.reshape(1.0/gamma, [-1, 1])
model = draw_mod
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

CSDN年度Top应用案例重磅评选活动正在火热报名中。我们希望找到在汽车、金融、医疗、教育等各大行业的AI Top 30+案例,相信挖掘出优秀先行者会给不同行业领域带来启迪,进而推动整个AI行业的发展进程。欢迎参选:https://aiprocon.csdn.net/m/topic/ai_procon/top30

推荐阅读
IBM重磅开源Power芯片指令集?国产芯迎来新机遇?
KDD 2019高维稀疏数据上的深度学习Workshop论文汇总
说出来你可能不信,现在酒厂都在招算法工程师
姚班三兄弟3万块创业八年,旷视终冲刺港股
2019 AI ProCon日程出炉:Amazon首席科学家李沐亲授「深度学习」
AI Top 30+案例评选等你来秀!
福利 | 马上为你安排和大咖面对面交流的机会,不可错过
92年小哥绞尽脑汁骗得价值800万比特币, 破案后警方决定还给受害者
他是叶问制片人也是红色通缉犯, 他让泰森卷入ICO, 却最终演变成了一场狗血的罗生门……

登录查看更多
相关内容
Arxiv
6+阅读 · 2018年4月7日



相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年4月7日