一种基于Sequence-to-Sequence的高质量对话生成方法
论文:
Generating High-Quality and Informative Conversation Responses with Sequence-to-Sequence Models(EMNLP 2017)
作者:
Louis Shao , Stephan Gouws , Denny Britz , Anna Goldie , Brian Strope , Ray Kurzweil
原文链接:http://www.aclweb.org/anthology/D17-1234
问题
在对话生成的过程中,如何产生具有一定信息量的高质量回复依然是一个很难解决的问题。
传统的Sequence-to-Sequence模型,容易产生较短的泛泛的回复,并且缺少多样性。如果加入明确的机制保证生成长句子,也很可能使句子出现支离破碎(如“The sun is in the center ofthe sun.”)、冗余(如“i like cake and cake”)、矛盾(如(“I don’t own a gun, but I do own agun.”)的状况。
本文中提出了“glimpse model”和“segment-based stochastic decoding technique”,相比于之前的传统模型,能够生成出更具信息量更具多样性的句子。
例如:
Query: what do you have planned tonight
Response(Baseline): I have no idea what I want to do with my life. I have no idea what I want to
Response(Our model): I was planning on doing a few of these, but I’m not sure what to choose. I need to find a place to camp, and I don’t have a lotof time to make a plan.
方法
“glimpse model”: 本质上是对注意力机制模型的改装,原本的注意力机制模型,在Sequence-to-Sequence模型中,是对encoder端进行加权,而在这里,需要对decoder端也进行相应加权(参看原文图1)。
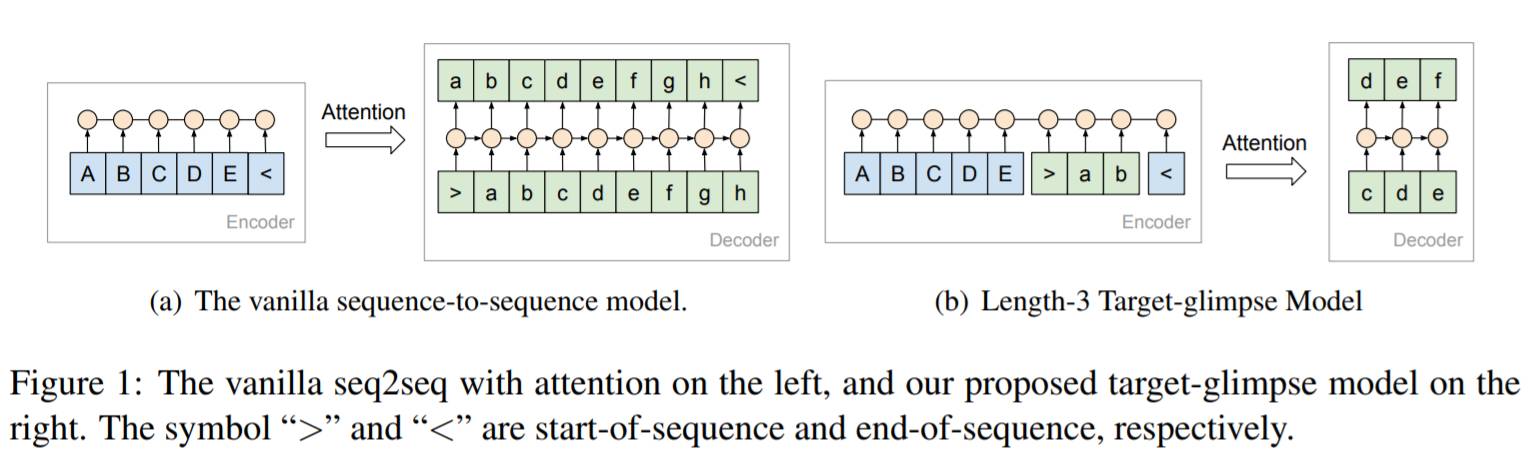
具体来说,训练时将decoder端分成固定长度为K的连续无重合片段,每训练一个片段时,将该片段之前的本该是decoder端的内容加入encoder端。例如:如果encoder端为序列x,decoder端为序列y,y被分为y1和y2,那么需要分别训练两个样例,即(x->y1)和(x,y1->y2)。
“segment-based stochastic decoding technique”: 在实际生成过程中,由于训练时是一个部分一个部分训练的,生成时也要这样生成,即先生成一个部分,然后将该部分加入到encoder端,再生成下一个部分。生成每个部分时,采用stochastic beam search算法,产生若干候选部分,在根据分数重排序(参见原文公式3)。
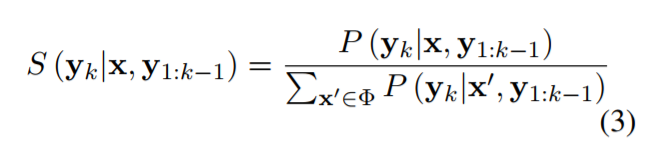
实验
数据源:
(1)The full Reddit data,2.21亿对话数据;
(2)The 2009 Open Subtitles data,50万对话数据;
(3)The Stack Exchange data ,80万对话数据;
(4)网络上抽取的对话文本,1700万。
评估指标:
(1)N-choose-1 accuracy:将正确回复和N-1条随机选取的句子放在一起排序,计算p@1;
(2)5-scale sideby-sidehuman evaluation: 分为5个等级的人工标注。
结论
本文中提出了“glimpse model”和“segment-based stochastic decoding technique”两种机制,实验证明在对话生成中,能够使回复更具信息量更具多样性。




