
【导读】自回归模型时生成模型的一种,本文介绍了其代表作PixelCNN的原理、代码实现以及应用。
介绍
生成模型最近备受关注,是无监督学习中的一类重要模型。 它的目标是学习生成新样本,使得这些样本看起来与训练数据相似。一旦模型成功训练,它就可以用于从图像修复,着色,超分辨率等。自回归是生成模型的一种,它构建一个显式密度模型,该模型学习训练数据的最大似然。
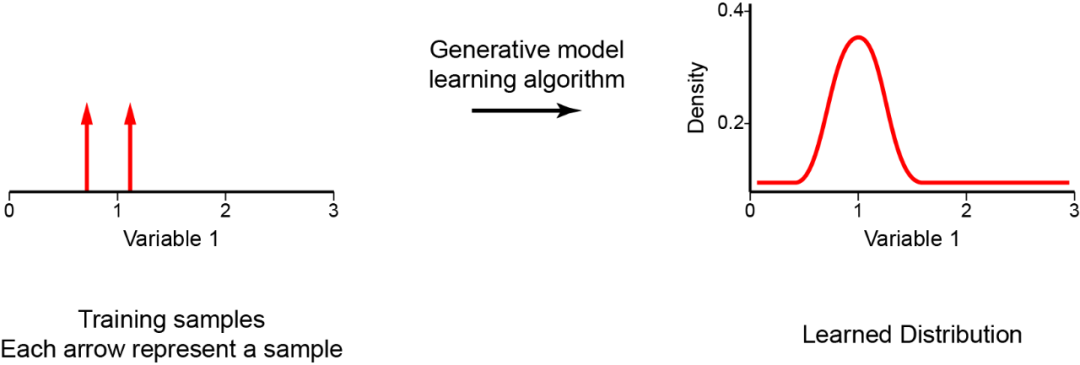
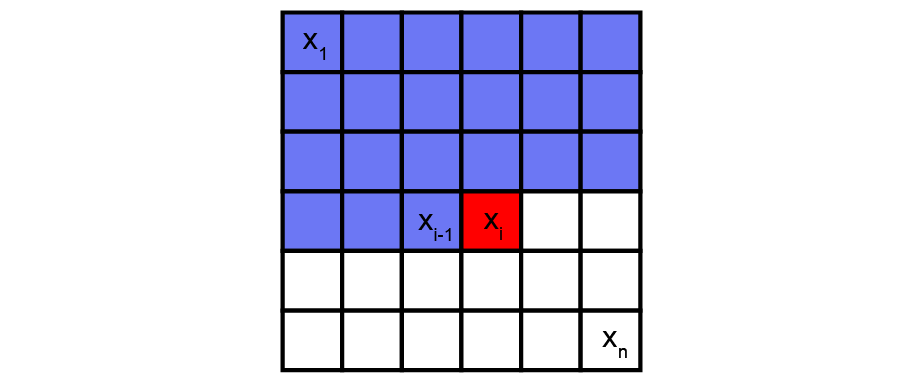
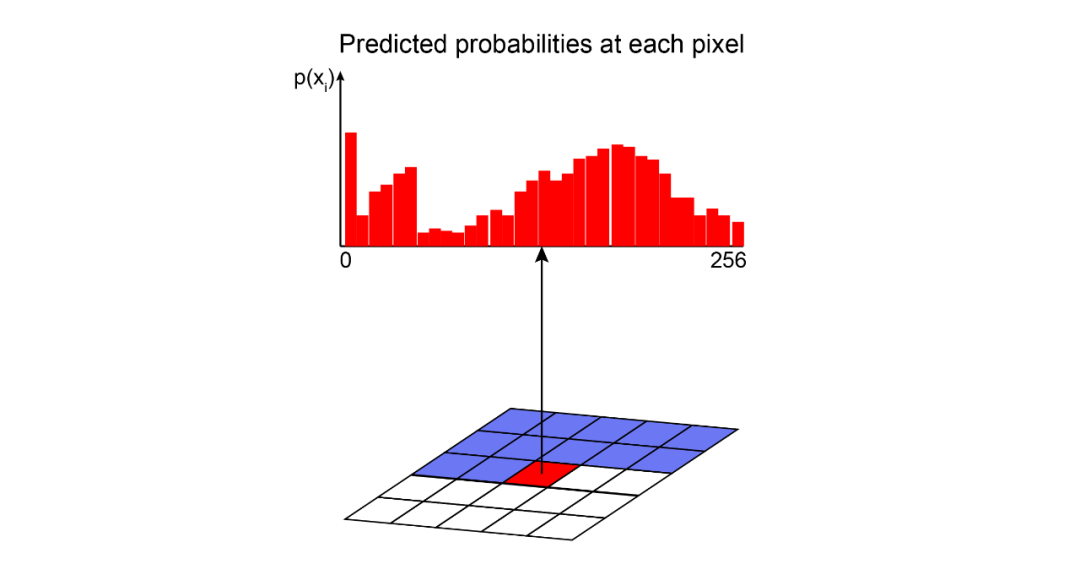
自回归是一种实用的方法,它提供了似然函数的显式建模。但是,要对具有多个维度/特征的数据进行建模,自回归模型需要更多条件。首先,输入空间X需要为其特征确定顺序。这就是为什么自回归模型通常用于具有固有时间步长序列的时间序列。但是,可以通过定义(例如)左侧的像素在右侧的像素之前,顶部的像素在底部的像素之前来将它们用于图像。其次,为了对数据观察中的特征的联合分布(p(x))进行精确建模,自回归方法将p(x)转换为条件分布的乘积。给定先前特征的值,自回归模型使用每个特征的条件定义联合分布。比如,图像中某个像素具有特定强度值的概率由所有先前像素的值决定;图像的概率(所有像素的联合分布)是其所有像素的概率的组合。因此,自回归模型使用链式规则将数据样本x的可能性分解为一维分布的乘积。分解将联合建模问题变成了序列问题,学习了在给定所有先前生成的像素的情况下预测下一个像素的过程。

现在,最大的挑战是计算这些条件似然p(xᵢ|x₁,…,xᵢ₁)。我们如何在易于处理和可扩展的表达模型中定义这些复杂的分布?一种解决方案是使用通用近似器,例如深度神经网络。 PixelCNN
DeepMind在2016年推出了PixelCNN,该模型开启了自回归生成模型系列之一。它已被用于生成语音,视频和高分辨率图片。

PixelCNN是一个深层神经网络,可捕获其参数中像素之间的依存关系分布。它沿着两个空间维度在图像中一次顺序生成一个像素。
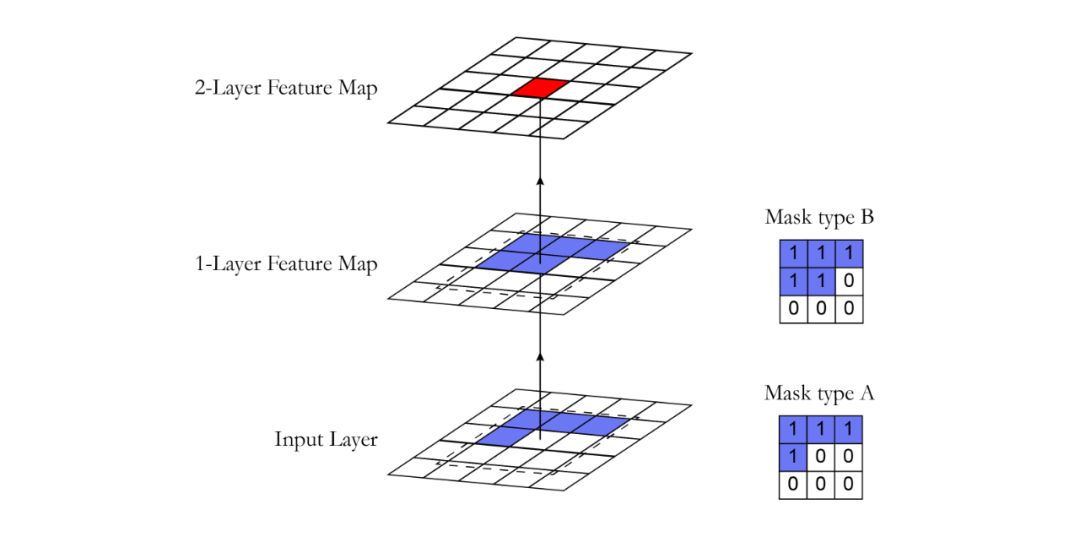
使用卷积运算,PixelCNN可以并行学习图像中所有像素的分布。但是,当确定特定像素的概率时,标准卷积层的接收场违反了自回归模型的顺序预测。当处理中心像素的信息时,卷积滤波器会考虑其周围的所有像素以计算输出特征图,而不仅仅是先前的像素。然后采用掩码来阻止来自尚未预测的像素的信息流。 掩码卷积层
可以通过将不应该考虑的所有像素清零来完成屏蔽。在我们的实现中,创建了具有与卷积过滤器相同大小且值为1和0的蒙版。在进行卷积运算之前,将此掩码乘以权重张量。在PixelCNN中,有两种掩码类型: 掩码类型A:此掩码仅应用于第一卷积层。它通过将遮罩中的中心像素置零来限制对感兴趣像素的访问。这样,我们保证模型不会访问要预测的像素(下图中的红色)。 掩码类型B:此掩码应用于所有后续的卷积层,并通过允许从像素到其自身的连接来放宽掩码A的限制。
在这里,我们提供一段代码,使用Tensorflow 2.0框架实现掩码。 * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
class MaskedConv2D(keras.layers.Layer):` """Convolutional layers with masks.``
`` Convolutional layers with simple implementation of masks type A and B for`` autoregressive models.``
`` Arguments:`` mask_type: one of `"A"` or `"B".``` filters: Integer, the dimensionality of the output space`` (i.e. the number of output filters in the convolution).`` kernel_size: An integer or tuple/list of 2 integers, specifying the`` height and width of the 2D convolution window.`` Can be a single integer to specify the same value for``all spatial dimensions.`` strides: An integer or tuple/list of 2 integers,`` specifying the strides of the convolution along the height and width.`` Can be a single integer to specify the same value for``all spatial dimensions.`` Specifying any stride value != 1 is incompatible with specifying``any `dilation_rate` value != 1.`` padding: one of `"valid"` or `"same"` (case-insensitive).`` kernel_initializer: Initializer for the `kernel` weights matrix.`` bias_initializer: Initializer for the bias vector.``"""``
`` def __init__(self,`` mask_type,`` filters,`` kernel_size,`` strides=1,`` padding='same',`` kernel_initializer='glorot_uniform',`` bias_initializer='zeros'):`` super(MaskedConv2D, self).__init__()``
`` assert mask_type in {'A', 'B'}`` self.mask_type = mask_type``
`` self.filters = filters`` self.kernel_size = kernel_size`` self.strides = strides`` self.padding = padding.upper()`` self.kernel_initializer = initializers.get(kernel_initializer)`` self.bias_initializer = initializers.get(bias_initializer)``
`` def build(self, input_shape):`` self.kernel = self.add_weight('kernel',`` shape=(self.kernel_size,`` self.kernel_size,`` int(input_shape[-1]),`` self.filters),`` initializer=self.kernel_initializer,`` trainable=True)``
`` self.bias = self.add_weight('bias',`` shape=(self.filters,),`` initializer=self.bias_initializer,`` trainable=True)``
`` center = self.kernel_size // 2``
`` mask = np.ones(self.kernel.shape, dtype=np.float32)`` mask[center, center + (self.mask_type == 'B'):, :, :] = 0.`` mask[center + 1:, :, :, :] = 0.``
`` self.mask = tf.constant(mask, dtype=tf.float32, name='mask')``
`` def call(self, input):`` masked_kernel = tf.math.multiply(self.mask, self.kernel)`` x = nn.conv2d(input,`` masked_kernel,`` strides=[1, self.strides, self.strides, 1],`` padding=self.padding)`` x = nn.bias_add(x, self.bias)`` return x`
模型结构
PixelCNN使用以下架构:第一层是具有7x7滤镜的掩码卷积(A型)。然后,使用了15个残差块。每个块使用3x3卷积层B和标准1x1卷积层的组合来处理数据。在每个卷积层之间,存在一个非线性ReLU。最后,残余块还包括残余连接。
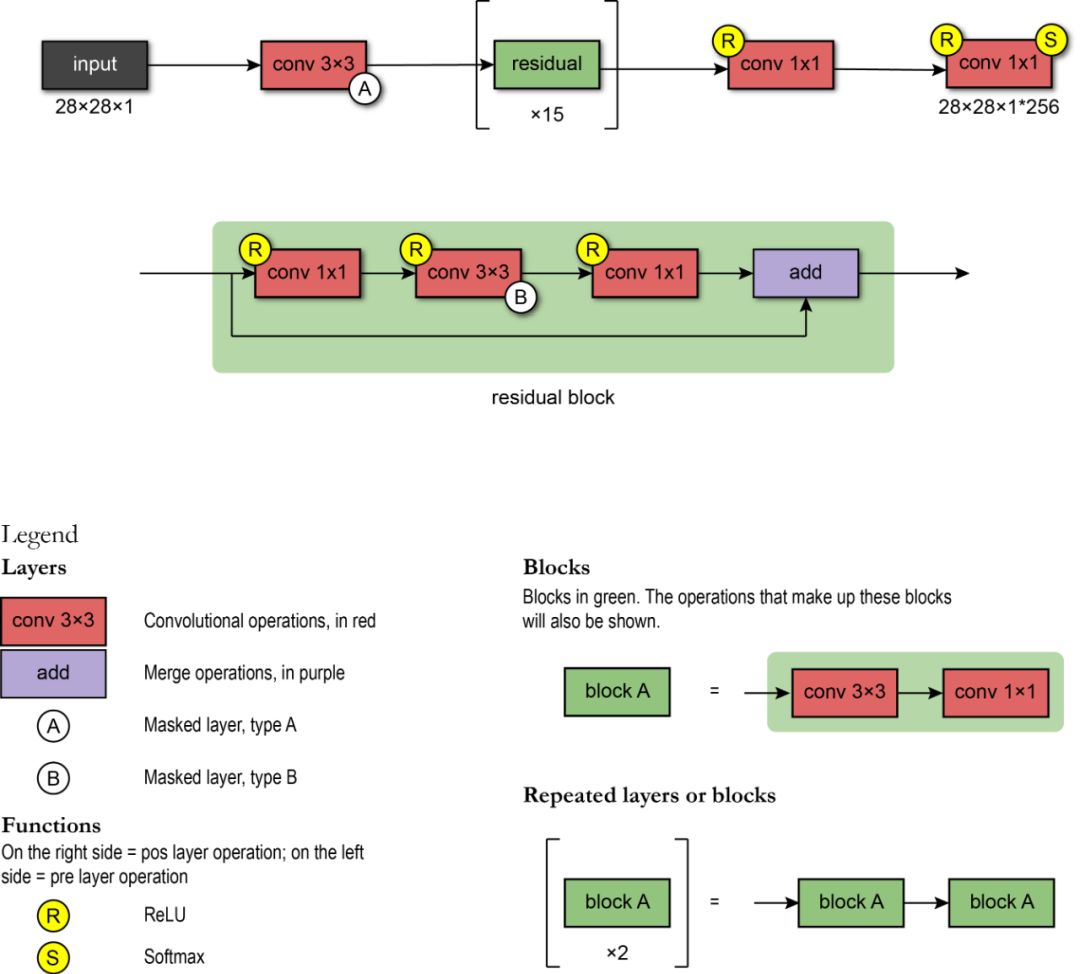
网络将使用标准卷积层和1x1滤波器,形成一连串RELU-CONV-RELU-CONV层。然后,输出层是softmax层,可预测像素所有可能值中的值。模型的输出具有与输入图像相同的空间格式(因为我们需要每个像素的输出值)乘以可能值的数量(例如256个强度级别)。 在这里,我们提供一段代码,使用Tensorflow 2.0框架实现网络体系结构。 * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
class ResidualBlock(keras.Model):`"""Residual blocks that compose pixelCNN``
`` Blocks of layers with 3 convolutional layers and one residual connection.`` Based on Figure 5 from [1] where h indicates number of filters.``
`` Refs:`` [1] - Oord, A. V. D., Kalchbrenner, N., & Kavukcuoglu, K. (2016). Pixel`` recurrent neural networks. arXiv preprint arXiv:1601.06759.`` """``
``def __init__(self, h):``super(ResidualBlock, self).__init__(name='')``
``self.conv2a = keras.layers.Conv2D(filters=h, kernel_size=1, strides=1)``self.conv2b = MaskedConv2D(mask_type='B', filters=h, kernel_size=3, strides=1)``self.conv2c = keras.layers.Conv2D(filters=2 * h, kernel_size=1, strides=1)``
``def call(self, input_tensor):`` x = nn.relu(input_tensor)`` x = self.conv2a(x)``
`` x = nn.relu(x)`` x = self.conv2b(x)``
`` x = nn.relu(x)`` x = self.conv2c(x)``
`` x += input_tensor``return x``
``# Create PixelCNN model``inputs = keras.layers.Input(shape=(height, width, n_channel))``x = MaskedConv2D(mask_type='A', filters=128, kernel_size=7, strides=1)(inputs)``
``for i in range(15):`` x = ResidualBlock(h=64)(x)``
``x = keras.layers.Activation(activation='relu')(x)``x = keras.layers.Conv2D(filters=128, kernel_size=1, strides=1)(x)``x = keras.layers.Activation(activation='relu')(x)``x = keras.layers.Conv2D(filters=128, kernel_size=1, strides=1)(x)``x = keras.layers.Conv2D(filters=q_levels, kernel_size=1, strides=1)(x)``
``pixelcnn = keras.Model(inputs=inputs, outputs=x)`
预处理
PixelCNN的输入值缩放到[0,1]区间。
模型训练
PixelCNN有一个简单的训练方法。该模型通过最大化训练数据的似然估计来学习其参数。
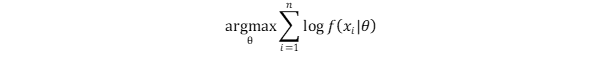
推断
由于PixelCNN是自回归模型,因此推断恰好是顺序的-我们必须逐个像素地生成。首先,我们通过将零传递给我们的模型来生成图像。它不应影响第一个像素,因为其值被建模为独立于所有其他像素。因此,我们执行前向通过并获得其分布。给定分布,我们首先进行采样。然后,我们使用采样的像素值更新图像,然后重复此过程,直到生成所有像素值为止。在这里,使用MNIST数据集使用PixelCNN在150个epoch之后生成样本。每个生成的图像具有四个级别的像素强度。

原文链接:
https://towardsdatascience.com/autoregressive-models-pixelcnn-e30734ede0c1




