可视化循环神经网络的注意力机制
编者按:Datalogue的Zafarali Ahmed介绍了RNN和seq2seq的概念,基于Keras实现了一个双向LSTM,并可视化了它的注意力机制。
循环神经网络(RNN)在翻译(谷歌翻译)、语音识别(Cortana)和语言生成领域取得了巨大的成功。在Datalogue,我们处理大量的文本数据,我们很有兴趣帮助社区理解这一技术。
在这篇教程中,我们将基于Keras编写一个RNN,将“November 5, 2016”、“5th November 2016”这样的日期表达转换为标准格式(“2016–11–05”)。具体来说,我们希望获得一些神经网络是如何做到这些的直觉。我们将利用注意力概念生成一份类似下图的映射,揭示哪些输入字符在预测输出字符上起着重要作用。
教程概览
我们将从一些技术背景材料开始,接着编程模型!在教程中,我会提供指向更高级内容的链接。
如果你想要直接查看代码:
请访问GitHub:datalogue/keras-attention
你需要了解
如果你想直接跳到本教程的代码部分,你最好熟悉Python和Keras。你应该熟悉下线性代数,毕竟神经网络不过是应用了非线性的一些权重矩阵。
下面我们将解释RNN和seq2seq(序列到序列)模型的直觉。
循环神经网络(RNN)
RNN是一个应用同一变换(称为RNN单元或步骤)至一个序列的每个元素的函数。RNN层的输出是RNN单元应用至序列的每个元素后的输出。在文本情形下,这些通常是后续的单词或字符。此外,RNN单元维护内部记忆,总结了目前为止所见序列的历史。
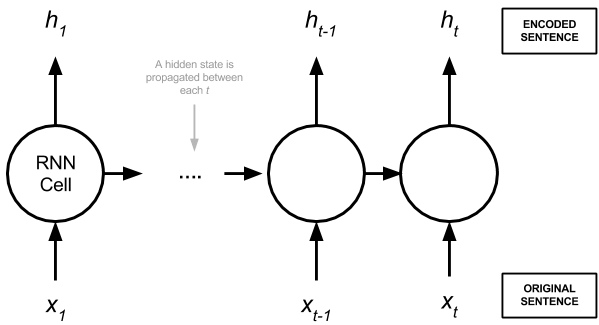
RNN层的输出是一个编码序列h,可以处理该序列,也可以将它传给另一个网络。RNN的输入和输出极为灵活:
多对一:使用完整的输入序列做出单个预测h。
一对多:转换单个输入以生成序列h。
多对多:转换整个输入序列至另一个序列。
理论上,训练数据的序列长度不用一样。在实践中,我们补齐或截断序列得到相同长度,以利用TensorFlow的静态计算图的优势。
我们将重点关注第三种RNN,“多对多”,也称为序列到序列(seq2seq)。
由于训练中梯度计算的不稳定性,RNN很难学习长序列。为了解决这一问题,可以将RNN单元替换为门控单元,比如门控循环单元(GRU)或长短时记忆网络(LSTM)。如果你想了解更多LSTM和门控单元,我强烈推荐Christopher Olah的博客(我就是从这篇开始理解RNN单元的)。从现在开始,当我们谈论RNN的时候,我们指的是门控单元。
seq2seq一般框架:编码器-解码器设定
几乎所有处理seq2seq问题的神经网络都涉及:
编码输入序列为某种抽象表示。
处理这一编码。
解码至目标序列。
编码器和解码器可以是任意种类的神经网络组合。在实践中,大多数人编码器和解码器都使用RNN。
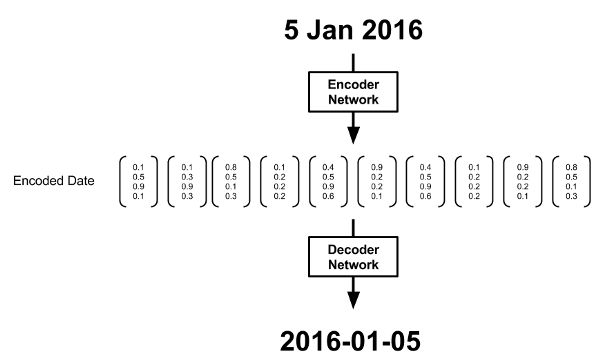
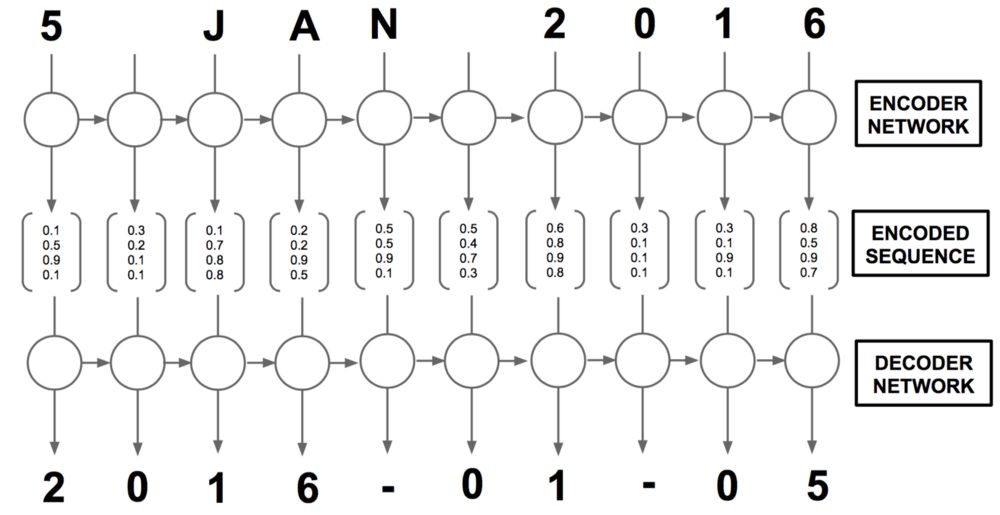
上图显示了一个简单的编码器-解码器设定。编码步骤通常生成向量序列h,对应输入数据中的字符序列x。在一个RNN编码器中,通过纳入之前向量序列的信息生成每个向量。
在将h传给解码器之前,我们可以先处理一番。例如,我们也许选择只使用最后的编码(如下图所示),因为理论上它是整个序列的总结。
直观地说,这类似总结整个输入数据为单个表示,接着尝试加以解码。尽管对于情绪检测这样的分类问题(多对一),总结状态可能已经具备足够信息,对于翻译之类的问题,仅仅使用总结状态可能不够,需要考虑隐藏状态的完整序列。
然而,人类不是这么翻译日期的:我们并不读取整个文本,然后单独写下每个字符的翻译。从直觉上说,一个人会整体理解一组字符“Jan”对应一月,“5”对应日期,“2016”对应年。如前所述,这一想法是RNN可以捕捉的注意,并且成功用于图像说明生成(Xu等. 2015),语音识别(Chan等. 2015),还有机器翻译(Bahdanau等. 2014)。最重要的是,它们生成可解释的模型。
上面提到的图像说明生成论文展示了一个注意力机制如何工作的可视化例子。在女孩和泰迪熊的复杂例子中,我们看到,生成单词“girl”(女孩)时,注意力机制成功地聚焦女孩,而不是泰迪熊!相当聪明。这不仅可以生成效果很好的可视化图像,同时便于作者诊断模型中的问题。

SpaCy的创造者写了一篇编码器-注意-解码器范式的深度概览:Embed, encode, attend, predict: The new deep learning formula for state-of-the-art NLP models。如果你想了解其他改动RNN的方式,可以参考Distill上的Attention and Augmented Recurrent Neural Networks。
这篇教程将介绍使用单个双向LSTM作为编码器和注意解码器。更具体地说,我们将实现Bahdanau等在2014年发表的Neural machine translation by jointly learning to align and translate论文中提出的模型的简化版本。我会讲解部分数学,但如果你想了解细节,我邀请你阅读论文的附录。
现在我们已经了解了RNN这一概念,以及注意力机制背后的直觉,让我们开始学习如何实现这一模型,接着取得一些漂亮的可视化结果。后续小节所有的代码都可以在本文开头给出的GitHub仓库(datalogue/keras-attention)中找到,/models/NMT.py为模型的完整实现。
编码器
Keras自带了RNN(LSTM)实现,可以通过以下方式调用:
BLSTM = Bidirectional(LSTM(encoder_units, return_sequences=True))
encoder_units参数是权重矩阵的大小。return_sequences=True表示我们需要完整的编码序列,而不仅仅是最终总结状态。
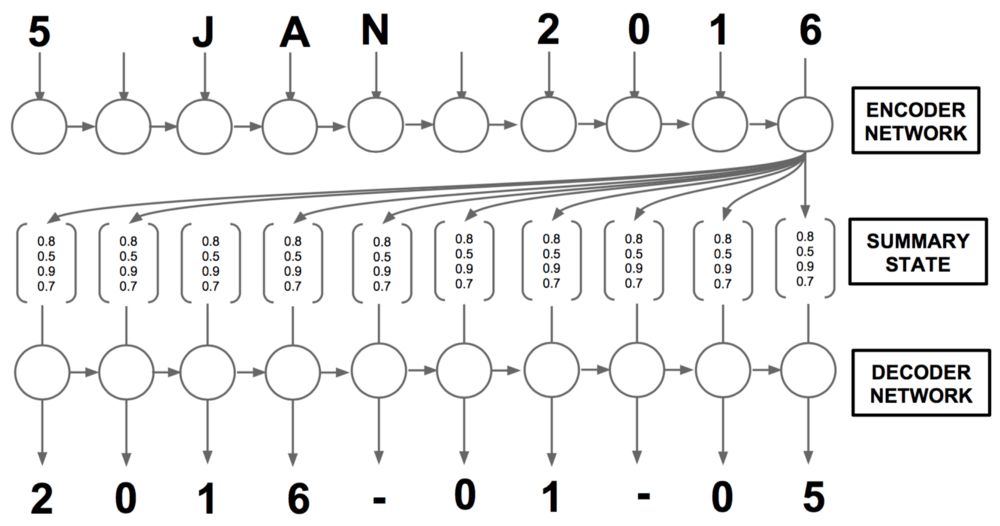
我们的BLSTM将接受输入序列x=(x1,...,xT)中的字符作为输入,并输出编码序列h=(h1,...,hT),其中T为日期的字符数。注意这和Bahdanau等论文有点不一样,原论文中句子以单词而不是字符为单位。我们也不像原论文那样把编码序列叫做注释(annotations)。
解码器
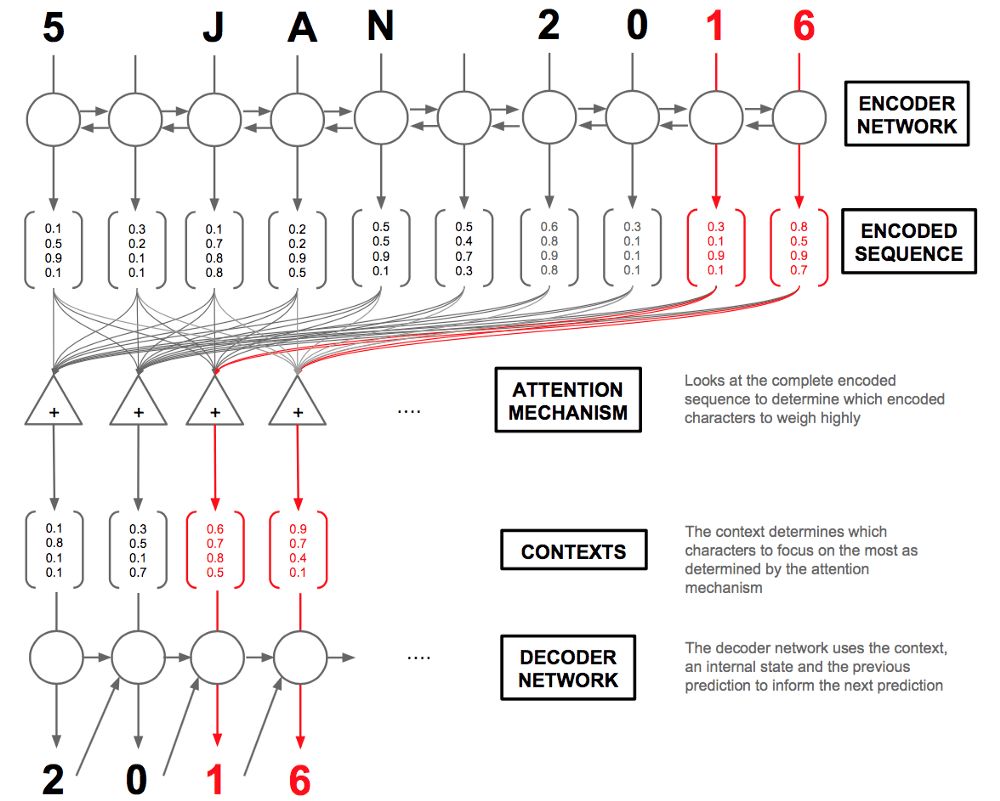
下面到了有趣的部分:解码器。对序列t处的任意给定字符,解码器接受编码序列h=(h1,...,hT)、之前的隐藏状态st-1(和解码器单元共享)、字符yt-1。我们的解码器层将输出y=(y1,...,yT)(标准化日期中的字符)。上图总结了我们的整体架构。
等式
如前所示,解码器相当复杂。所以让我们将它分解为尝试预测字符t的解码器单元执行的步骤。在下式中,大写字母变量表示可训练参数(注意,为了简明,我省去了偏置项)。
根据编码序列和解码器单元的内部隐藏状态st-1,计算注意概率
α=(α1,…,αT)。计算上下文向量,即带关注概率的编码序列加权和。直观地说,这一向量总结了不同编码字符在预测第t个字符上的作用。
我们接着更新隐藏状态。如果你熟悉LSTM单元的等式,这些也许会唤起你的回忆,重置门
r,更新门z,以及提议状态。st-1用于创建提议隐藏状态。更新门控制在新的隐藏状态st中包括多少提议。(没有头绪?看这篇逐步讲解LSTM的文章)根据上下文向量、隐藏状态、之前字符,使用一个简单的单层神经网络计算第
t个字符。相比原论文,这里做了一点改动,原论文用了一个maxout层。这一改动是因为我们想要让模型尽可能地简单。
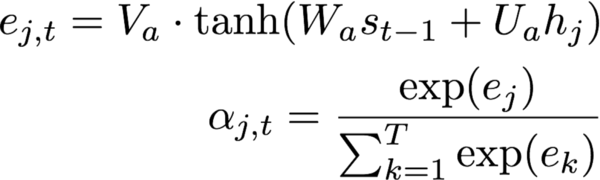
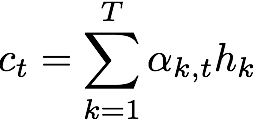
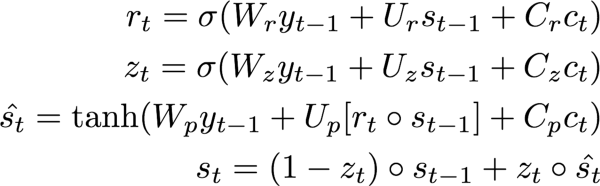
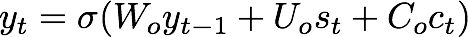
上面的这些等式应用于编码序列中的每个字符,以生成解码序列y,该序列表示每个位置出现某个转译字符的概率。
代码
models/custom_recurrent.py实现了我们的定制层。这一部分比较复杂,因为我们需要对整个编码序列进行处理。多思考一下能帮助你看懂代码。我保证,如果你一边看等式,一边看代码,会容易不少。
最低限度的定制Keras层需要实现这些方法:__init__,compute_output_shape,build,call。出于完整性考虑,我们也实现了get_config,这让我们可以很容易地重新加载模型到内存之中。此外,Keras循环层实现了step方法,包括单元中的所有计算。
下面我们首先分步讲解下样板代码:
__init__是在初始化层时调用的方法。它设定将逐渐用于初始化权重、正则化、限制的函数。由于我们的层输出是序列,我们硬编码了self.return_sequences=True。build是在运行Model.compile(…)时调用的方法。由于我们的模型相当复杂,你可以看到这里初始化了一大堆权重。self.add_weight调用自动处理初始化权重,并将权重设为模型的可训练参数。下标为a的权重用于计算上下文向量(第1步和第2步)。下标为r、z、p的权重用于计算第3步的新隐藏状态。最后,下标为o的权重将计算层输出。我们还实现了一些辅助函数:
compute_output_shape为任意给定输入计算输出形状;get_config让我们从保存文件中加载模型(完成训练之后)。
现在让我们来看单元逻辑:
默认情况下,单元的每次执行只具备上一时步的信息。由于我们需要访问单元内的完整编码序列,我们需要将它保存在某处。
def call(self, x):
# 储存完整序列
self.x_seq = x
# 对序列的时间维度应用一个密集层。
# 由于它不依赖任何之前的步骤,
# 我们可以在这里应用,以节省计算时间:
self._uxpb = _time_distributed_dense(self.x_seq, self.U_a, b=self.b_a,
input_dim=self.input_dim,
timesteps=self.timesteps,
output_dim=self.units)
return super(AttentionDecoder, self).call(x)
下面我们将讲解代码最重要的部分,执行单元逻辑的step函数。回忆一下,step应用于输入序列的每个元素。
def step(self, x, states):
# 获取上一时步的元素
ytm, stm = states
## ## ## ## ## ## ## ## ##
# 等式 1
# > 重复隐藏状态至序列长度
_stm = K.repeat(stm, self.timesteps)
# > 权重矩阵乘以
# 重复隐藏状态
_Wxstm = K.dot(_stm, self.W_a)
# > 计算未归一化的概率
et = K.dot(activations.tanh(_Wxstm + self._uxpb),
K.expand_dims(self.V_a))
## ## ## ## ## ## ## ## ##
# 等式 2
at = K.exp(et)
at_sum = K.sum(at, axis=1)
at_sum_repeated = K.repeat(at_sum, self.timesteps)
# 向量 (batch大小, 时步, 1)
at /= at_sum_repeated
## ## ## ## ## ## ## ## ##
# 等式 3
context = K.squeeze(
K.batch_dot(at,
self.x_seq,
axes=1),
axis=1)
# ~~~> 计算新隐藏状态
# 等式 4 (重置门)
rt = activations.sigmoid(
K.dot(ytm, self.W_r)
+ K.dot(stm, self.U_r)
+ K.dot(context, self.C_r)
+ self.b_r)
# 等式 5 (更新门)
zt = activations.sigmoid(
K.dot(ytm, self.W_z)
+ K.dot(stm, self.U_z)
+ K.dot(context, self.C_z)
+ self.b_z)
# 等式 6 (提议状态)
s_tp = activations.tanh(
K.dot(ytm, self.W_p)
+ K.dot((rt * stm), self.U_p)
+ K.dot(context, self.C_p)
+ self.b_p)
# 等式 7 (新隐藏状态)
st = (1-zt)*stm + zt * s_tp
# 等式 8
# 出现每个字符的概率
yt = activations.softmax(
K.dot(ytm, self.W_o)
+ K.dot(st, self.U_o)
+ K.dot(context, self.C_o)
+ self.b_o)
# 方便我们返回
# 可视化注意的开关
if self.return_probabilities:
return at, [yt, st]
else:
return yt, [yt, st]
在这个单元中,我们想要访问从states获得的之前字符ytm和隐藏状态stm(代码第4行)。
我们在第11-18行实现了等式1的一个版本,一次性计算序列中的所有字符。
在第24-28行我们以向量形式为整个序列实现了等式2. 使用repeat让我们可以根据各自的总和划分每个时步。
为了计算上下文向量,我们要记得self.x_seq和at有一个“batch维度”,因此我们需要使用batch_dot以免在那个维度上相乘。squeeze操作不过是移除残留维度。(代码第33-37行。)
之后的代码是等式4-8的比较直接的实现。
现在我们需要一点先见之明,我们想要计算文章开头那样酷炫的注意映射,所以需要一个切换开关。
训练
数据
Faker库可以生成虚假日期,我用这个库生成了日期,并用Babel库生成不同语言和格式的日期(借鉴了rasmusbergpalm/normalization的做法)。如果你想要了解细节,我邀请你直接去看data/generate.py中的代码(欢迎改进)。
这个脚本同时生成了转换字符至整数的词汇表,以便神经网络理解字符。data/reader.py脚本可以读取数据,并为神经网络准备数据。
模型
如前所述,我们实现的模型见models/NMT.py。你可以通过python run.py运行这个模型(我设定了一些默认参数,详见Readme)。我建议在GPU上训练模型,因为在CPU上训练会比较慢。
如果你想要跳过训练部分,那我在weights/中提供了一些权重。
可视化
visualizer.py是可视化部分的代码,两次加载权重:一次用于预测模型,一次用于获取概率。
from models.NMT import simpleNMT
predictive_model = simpleNMT(...)
predictive_model.load_weights(..., return_probabilities=False)
probability_model = simpleNMT(..., return_probabilities=True)
probability_model.load_weights(...)
运行以下命令可以查看提供的命令行选项:
python visualizer.py -h
可视化例子
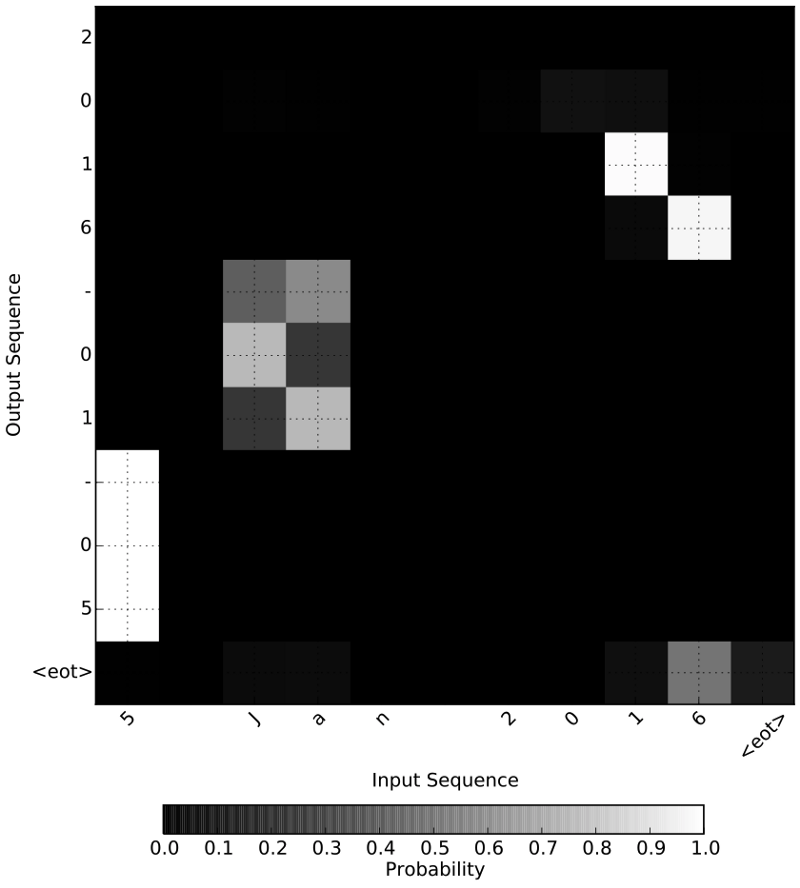
现在让我们检视下probability_model生成的关注。我们可以在y轴上看到上面的probability_model返回的转换后日期。在x轴上则是我们的输入日期。下图显示了在预测y轴上的输出字符时用到了哪些x轴上的输入字符。颜色越淡,字符的权重越高。
下面是一些我觉得相当有趣的例子。
毫不在意星期几这样的无关信息:
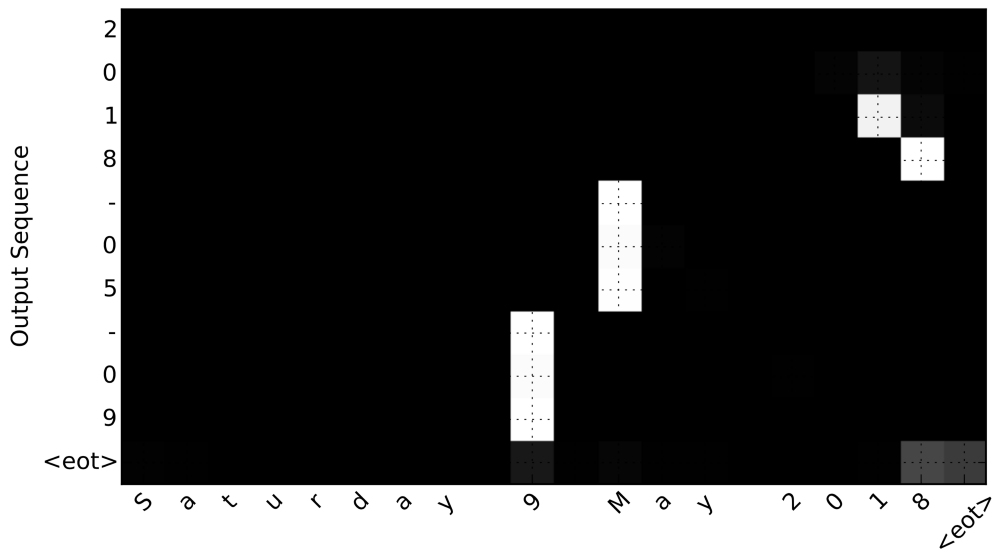
下面则是一个转换错误的例子,因为我们提交的样本的顺序不合常规:“January 2016 05”被转换成“2016–01–02”,而不是“2016–01–05”。
我们可以看到,模型将2016的“20”错误地解读为几号,不过这一激活很薄弱,部分甚至和实际日期“5”的激活相当。这给我们提供了如何更好地训练模型的洞见。
结语
我希望这篇教程能让你了解如何从头到尾求解一个机器学习问题。此外,我也希望它有助于你尝试可视化用于seq2seq问题的循环神经网络。如果我遗漏了什么,或者你发现了什么可以改进的地方,欢迎在twitter上联系我(zafarali),或者在本文的配套代码仓库上提交工单。
致谢
我在Datalogue的工作部分由NSERC Experience Award支持。Datalogue团队审阅了代码,校读了本文。
感谢Johanan Ottensooser、Nicolas Joseph、Sonia Sen对本文草稿的意见。
原文地址:https://medium.com/datalogue/attention-in-keras-1892773a4f22







