十分钟掌握Keras实现RNN的seq2seq学习
seq2seq是一种把序列从一个域(例如英语中的句子)转换为另一个域中的序列(例如把相同的句子翻译成法语)的模型训练方法。目前有多种方法可以用来处理这个任务,可以使用RNN,也可以使用一维卷积网络。
很多人问这个问题:如何在Keras中实现RNN序列到序列(seq2seq)学习?本文将对此做一个简单的介绍。
什么是seq2seq学习
序列到序列学习(seq2seq)是一种把序列从一个域(例如英语中的句子)转换为另一个域中的序列(例如把相同的句子翻译成法语)的模型训练方法。
"the cat sat on the mat" -> [Seq2Seq model] -> "le chat etait assis sur le tapis"
这可以用于机器翻译或免费问答(对于自然语言的问题,产生自然语言的答案)。一般来说,它适用于任何需要生成文本的场景。
目前有多种方法可以用来处理这个任务,可以使用RNN,也可以使用一维卷积网络。这里,我们将重点介绍RNN。
当输入和输出序列的长度相同时
当输入序列和输出序列具有相同长度的时候,你可以使用Keras LSTM或GRU层(或其堆叠)很轻松地实现这样地模型。这个示例脚本就是一个例子,它展示了如何教RNN计算加法,并编码为字符串:
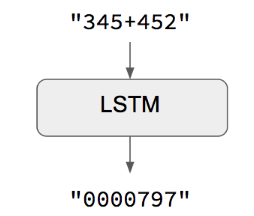
对于这个方法有一点要注意:我们假定了对于给定的input[...t]是可以生成target[...t]的。这在某些情况下有效(例如,数字字符串的加法),但在大多数情况下都无效。在一般情况下,要生成目标序列,必须要有输入序列的完整信息。
标准的序列到序列
一般来说,输入序列和输出序列的长度是不同的(例如机器翻译),并且需要有完整的输入序列才能开始预测目标。这需要一个更高级的设置,这就是人们在“序列到序列模型”时经常提及的没有上下文。下面是它的工作原理:
有一个RNN层(或其堆叠)作为“编码器”:它负责处理输入序列并返回其自身的内部状态。注意,我们将丢弃编码器RNN的输出,只恢复状态。该状态将在下一步骤中用作解码器的“上下文”或“环境”。
另外还有一个RNN层(或其堆叠)作为“解码器”:在给定目标序列前一个字符的情况下,对其进行训练以预测目标序列的下一个字符。具体来说,就是训练该层使其能够将目标序列转换成向将来偏移了一个时间步长的同一个序列,这种训练过程被称为“teacher forcing(老师强迫)”。有一点很重要,解码器将来自编码器的状态向量作为初始状态,这样,解码器就知道了它应该产生什么样的信息。实际上就是解码器以输入序列为条件,对于给定的targets[...t]学习生成targets[t+1...],。
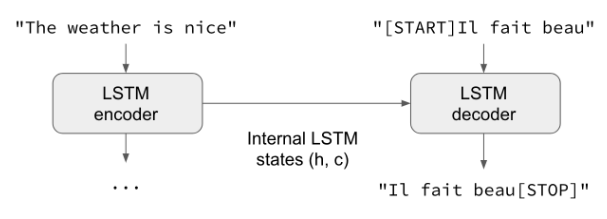
在推理模式下,即当我们要解码未知输入序列时,过程稍稍会有些不同:
将输入序列编码为状态向量。
以大小为1的目标序列开始。
将状态向量和一个字符的目标序列提供给解码器,以产生下一个字符的预测。
使用这些预测对下一个字符进行采样(我们简单地使用argmax)。
将采样的字符添加到目标序列上
重复上述步骤,直到生成序列结束字符,或者达到字符数限制。
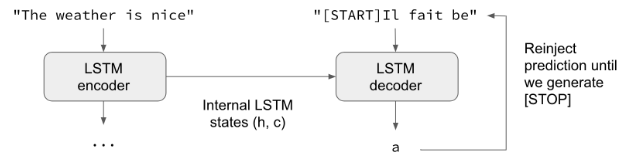
也可以在没有“teacher forcing”的情况下使用相同的过程来训练Seq2Seq网络,例如,通过将解码器的预测重新注入到解码器中。
一个Keras的例子
下面我们用代码来实现上面那些想法。
对于这个例程,我们将使用英文句子和对应的法语翻译数据集,可以从manythings.org/anki下载。下载的文件名为fra-eng.zip。我们将实现一个字符级别的序列到序列模型,处理逐个字符输入并逐个字符的生成输出。我们也可以实现一个单词级别的模型,这对于机器翻译而言更常见。在本文的最后,你能找到一些使用Embedding层把字符级别的模型变成单词级别模型的信息。
完整例程可以在GitHub上找到https://github.com/fchollet/keras/blob/master/examples/lstm_seq2seq.py。
下面简单介绍一下处理过程:
将句子转换为3个Numpy数组,encoder_input_data,decode_input_data,decode_target_data:
encoder_input_data是一个三维数组(num_pairs, max_english_sentence_length, num_english_characters),包含英文句子的独热向量化。
decoder_input_data是一个三维数组(num_pairs, max_french_sentence_length, num_french_characters),包含法语句子的独热向量化。
decoder_target_data与decoder_input_data相同但偏移一个时间步长。 decoder_target_data[:, t, :]将与decoder_input_data[:, t + 1, :]相同
训练一个基于LSTM的基本的Seq2Seq模型来预测encoder_input_data和decode_input_data的decode_target_data。模型使用了“teacher forcing”。
解码一些句子以检查模型是否正常工作(即将encoder_input_data中的样本从decoder_target_data转换为相应的样本)。
由于训练过程和推理过程(译码句)是完全不同的,所以我们要使用不同的模型,尽管它们都是利用相同的内部层。
这是我们的训练模型。它利用了Keras RNN的三个主要功能:
return_state contructor参数,配置一个RNN层返回第一个条目是输出,下一个条目是内部RNN状态的列表。用于恢复编码器的状态。
inital_state参数,指定RNN的初始状态。用于将编码器状态传递到解码器作为初始状态。
return_sequences构造函数参数,配置RNN返回其完整的输出序列。在解码器中使用。
转自:人工智能头条
完整内容请点击“阅读原文”




