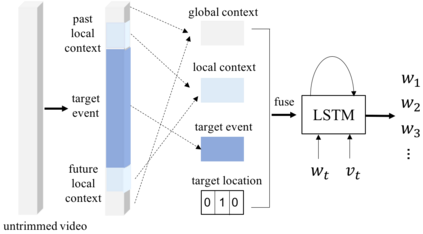
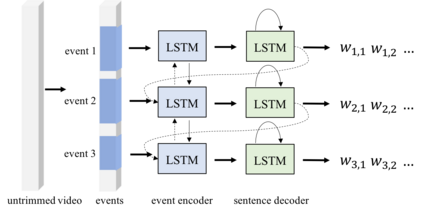
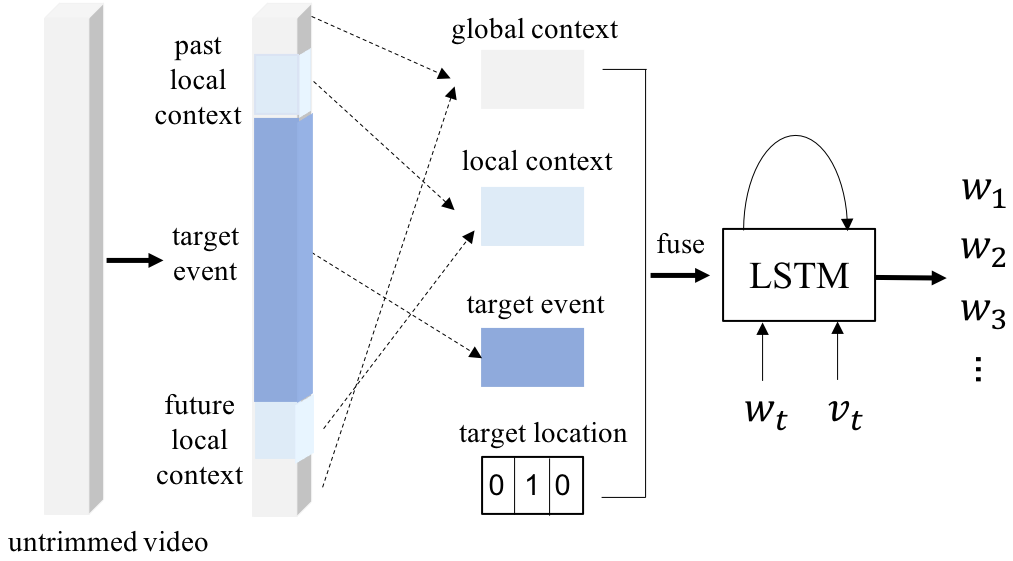
Contextual reasoning is essential to understand events in long untrimmed videos. In this work, we systematically explore different captioning models with various contexts for the dense-captioning events in video task, which aims to generate captions for different events in the untrimmed video. We propose five types of contexts as well as two categories of event captioning models, and evaluate their contributions for event captioning from both accuracy and diversity aspects. The proposed captioning models are plugged into our pipeline system for the dense video captioning challenge. The overall system achieves the state-of-the-art performance on the dense-captioning events in video task with 9.91 METEOR score on the challenge testing set.
翻译:在这项工作中,我们系统地探索各种字幕模型,其中涉及视频任务中密集字幕活动的各种背景,目的是在未剪辑的视频中为不同事件制作字幕。我们提出了五类背景以及两类事件字幕模型,并评价其对从准确性和多样性两个方面说明事件的贡献。拟议字幕模型被插入我们的管道系统,以应对密集视频字幕挑战。整个系统在视频任务中实现了密集字幕活动的最新性能,在挑战测试组中获得了9.91 METEOR分数。