一文读懂LSTM和循环神经网络

由于循环网络拥有一种特定的记忆模式,而记忆也是人类的基本能力之一,所以下文会时常将循环网络与人脑的记忆活动进行类比。
前馈网络回顾
要理解循环网络,首先需要了解前馈网络的基础知识。这两种网络的名字都来自于它们通过一系列网络节点数学运算来传递信息的方式。前馈网络将信息径直向前递送(从不返回已经过的节点),而循环网络则将信息循环传递。在前馈网络中,样例输入网络后被转换为一项输出;在进行有监督学习时,输出为一个标签。也就是说,前馈网络将原始数据映射到类别,识别出信号的模式,例如一张输入图像应当给予“猫”还是“大象”的标签。
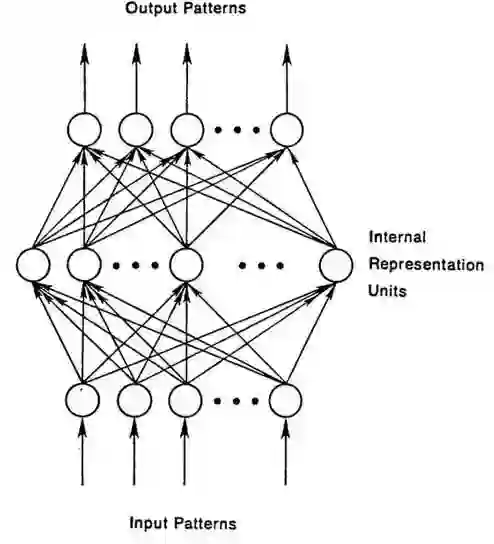
用带有标签的图像定型一个前馈网络,直到网络在猜测图像类别时的错误达到最少。将参数,即权重定型后,网络就可以对从未见过的数据进行分类。已定型的前馈网络可以接受任何随机的图片组合,而输入的第一张照片并不会影响网络对第二张照片的分类。看到一张猫的照片不会导致网络预期下一张照片是大象。这是因为网络并没有时间顺序的概念,它所考虑的唯一输入是当前所接受的样例。前馈网络仿佛患有短期失忆症;它们只有早先被定型时的记忆。
循环网络
循环网络与前馈网络不同,其输入不仅包括当前所见的输入样例,还包括网络在上一个时刻所感知到信息。以下是[由Elman提出的早期循环网络]的示意图,图中最下行的 BTSXPE 代表当前的输入样例,而 CONTEXT UNIT 则表示前一时刻的输出。
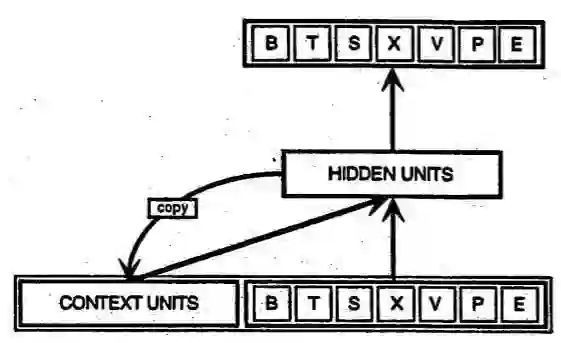
循环网络在第 t-1 个时间步的判定会影响其在随后第t个时间步的判定。所以循环网络有来自当下和不久之前的两种输入,此二者的结合决定了网络对于新数据如何反应,与人类日常生活中的情形颇为相似。
循环网络与前馈网络的区别便在于这种不断将自身上一刻输出当作输入的反馈循环。人们常说循环网络是有记忆的。为神经网络添加记忆的目的在于:序列本身即带有信息,而循环网络能利用这种信息完成前馈网络无法完成的任务。
这些顺序信息保存在循环网络隐藏状态中,不断向前层层传递,跨越许多个时间步,影响每一个新样例的处理。人类记忆会在体内不断进行不可见的循环,对我们的行为产生影响而不显现出完整样貌,而信息也同样会在循环网络的隐藏状态中循环。英语中有许多描述记忆反馈循环的说法。例如,我们会说“一个人被往日所为之事纠缠”,这其实就是在讲过去的输出对当前造成了影响。法国人称之为“Le passé qui ne passe pas”,即 “过去之事不曾过去”。
让我们用数学语言来描述将记忆向前传递的过程:

第 t 个时间步的隐藏状态是 h_t。它是同一时间步的输入 x_t 的函数,由一个权重矩阵W(和我们在前馈网络中使用的一样)修正,加上前一时间步的隐藏状态 h_t-1 乘以它自己的隐藏状态-隐藏状态矩阵的 U(或称过渡矩阵,与马尔可夫链近似)。权重矩阵是决定赋予当前输入及过去隐藏状态多少重要性的筛选器。它们所产生的误差将会通过反向传播返回,用于调整权重,直到误差不能再降低为止。
权重输入与隐藏状态之和用函数 φ 进行挤压-可能是逻辑S形函数(sigmoid函数)或双曲正切函数,视具体情况而定-这是将很大或很小的值压缩至一个逻辑空间内的标准工具,同时也用于产生反向传播所能接受的梯度。
由于这一反馈循环会在系列的每一个时间步发生,每一个隐藏状态不仅仅跟踪前一个隐藏状态,还包括了记忆能力范围内所有在h_t-1之前的状态。
若输入一系列字母,则循环网络必定会根据第一个字符来决定对第二个字符的感知, 例如,第一个字母如果是 q,网络就可能推断下一个字母是 u,而第一个字母如果是 t,则网络可能推断下一个字母是 h。
由于循环网络具有时间维度,所以可能用动画示意最为清楚(最先出现的节点垂直线可被视为一个前馈网络,随时间展开后变为循环网络)。
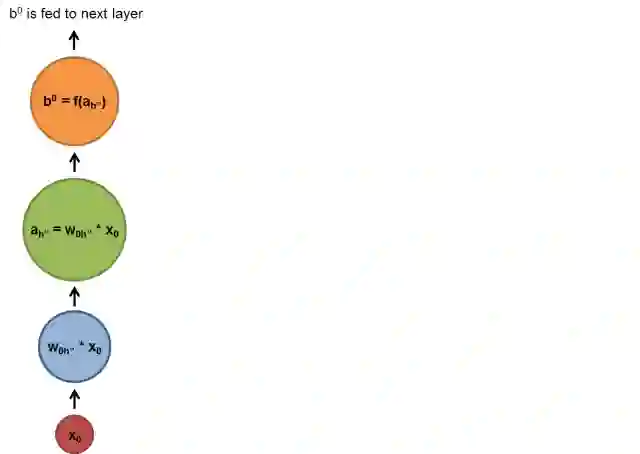
在上图中,每一个x都是一个输入样例,w 是用于筛选输入的权重,a 是隐藏层的激活状态(附加权重后的输入与上一个隐藏状态之和),而b则是隐藏层用修正线性或sigmoid单元进行变换(或称“挤压”)后的输出。
时间反向传播BPTT
前文提到,循环网络的目的是准确地对序列输入进行分类。我们依靠误差反向传播和梯度下降来达成这一目标。前馈网络的反向传播从最后的误差开始,经每个隐藏层的输出、权重和输入反向移动,将一定比例的误差分配给每个权重,方法是计算权重与误差的偏导数-∂E/∂w,即两者变化速度的比例。随后,梯度下降的学习算法会用这些偏导数对权重进行上下调整以减少误差。
循环网络则使用反向传播的一种扩展方法,名为沿时间反向传播,或称BPTT。在这里,时间其实就表示为一系列定义完备的有序计算,将时间步依次连接,而这些计算就是反向传播的全部内容。
无论循环与否,神经网络其实都只是形如 f(g(h(x))) 的嵌套复合函数。增加时间要素仅仅是扩展了函数系列,我们用链式法则计算这些函数的导数。
截断式BPTT
截断式BPTT是完整BPTT的近似方法,也是处理较长序列时的优先选择,因为时间步数量较多时,完整BPTT每次参数更新的正向/反向运算量会变的非常高。该方法的缺点是,由于截断操作,梯度反向移动的距离有限,因此网络能够学习的依赖长度要短于完整的BPTT。
梯度消失与梯度爆炸
像大多数神经网络一样,循环网络并非新事物。在上世纪九十年代早期,梯度消失问题成为影响循环网络表现的重大障碍。正如直线表示x如何随着y的变化而改变,梯度表示所有权重随误差变化而发生的改变。如果梯度未知,则无法朝减少误差的方向调整权重,网络就会停止学习。
循环网络在寻找最终输出与许多时间步以前的事件之间的联系时遇到了重大障碍,因为很难判断应当为远距离的输入赋予多少重要性。(这些输入就像曾曾…曾祖父母一样,不断向前追溯时会迅速增多,而留下的印象通常很模糊。)原因之一是, 神经网络中流动的信息会经过许多级的乘法运算。
凡是学过复合利率的人都知道,任何数值,只要频繁乘以略大于一的数,就会增大到无法衡量的地步(经济学中的网络效应和难以避免的社会不平等背后正是这一简单的数学真理)。反之亦然:将一个数反复乘以小于一的数,也就会有相反的效果。赌徒要是每下一美元注都输掉97美分,那片刻就会倾家荡产。
由于深度神经网络的层和时间步通过乘法彼此联系,导数有可能消失或膨胀。梯度膨胀时,每个权重就仿佛是一只谚语中提到的蝴蝶,所有的蝴蝶一齐扇动翅膀,就会在遥远的地方引发一场飓风。这些权重的梯度增大至饱和,亦即它们的重要性被设得过高。但梯度膨胀的问题相对比较容易解决,因为可以将其截断或挤压。而消失的梯度则有可能变得过小,以至于计算机无法处理,网络无法学习-这个问题更难解决。
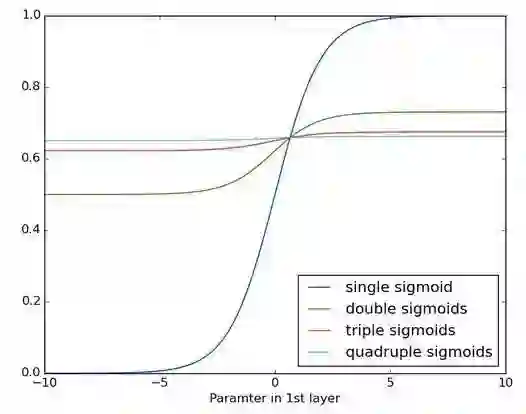
反复应用sigmoid函数的结果如下图所示。数据曲线越来越平缓,直至在较长的距离上无法检测到斜度。梯度在经过许多个层后消失的情况与此相似。
长短时记忆单元LSTM
九十年代中期,德国学者Sepp Hochreiter和Juergen Schmidhuber提出了循环网络的一种变体,带有所谓长短期记忆单元,或称LSTM,可以解决梯度消失的问题。
LSTM可保留误差,用于沿时间和层进行反向传递。LSTM将误差保持在更为恒定的水平,让循环网络能够进行许多个时间步的学习(超过1000个时间步),从而打开了建立远距离因果联系的通道。
LSTM将信息存放在循环网络正常信息流之外的门控单元中。这些单元可以存储、写入或读取信息,就像计算机内存中的数据一样。单元通过门的开关判定存储哪些信息,以及何时允许读取、写入或清除信息。但与计算机中的数字式存储器不同的是,这些门是模拟的,包含输出范围全部在0~1之间的sigmoid函数的逐元素相乘操作。相比数字式存储,模拟值的优点是可微分,因此适合反向传播。
这些门依据接收到的信号而开关,而且与神经网络的节点类似,它们会用自有的权重集对信息进行筛选,根据其强度和导入内容决定是否允许信息通过。这些权重就像调制输入和隐藏状态的权重一样,会通过循环网络的学习过程进行调整。也就是说,记忆单元会通过猜测、误差反向传播、用梯度下降调整权重的迭代过程学习何时允许数据进入、离开或被删除。下图显示了数据在记忆单元中如何流动,以及单元中的门如何控制数据流动。
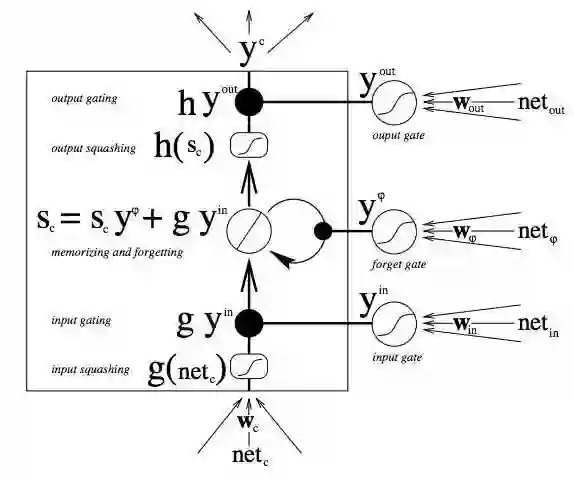
上图中的内容很多,如果读者刚开始学习LSTM,别急着向下阅读-请先花一些时间思考一下这张图。只要几分钟,你就会明白其中的秘密。
首先,最底部的三个箭头表示信息从多个点流入记忆单元。当前输入与过去的单元状态不只被送入记忆单元本身,同时也进入单元的三个门,而这些门将决定如何处理输入。图中的黑点即是门,分别决定何时允许新输入进入,何时清除当前的单元状态,以及/或何时让单元状态对当前时间步的网络输出产生影响。S_c 是记忆单元的当前状态,而 g_y_in 是当前的输入。记住,每个门都可开可关,而且门在每个时间步都会重新组合开关状态。记忆单元在每个时间步都可以决定是否遗忘其状态,是否允许写入,是否允许读取,相应的信息流如图所示。图中较大的黑体字母即是每项操作的结果。
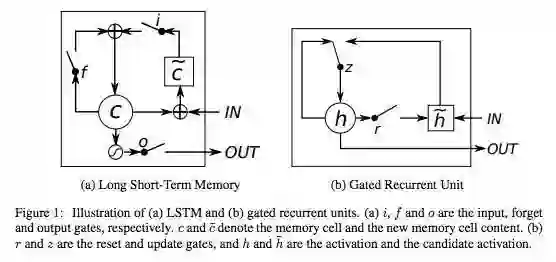
下面是另一张图,将简单循环网络(左)与LSTM单元(右)进行对比。蓝线可忽略;图例有助理解。

应当注意的是,LSTM的记忆单元在输入转换中给予加法和乘法不同的角色。两张图中央的加号其实就是LSTM的秘密。虽然看起来异常简单,这一基本的改变能帮助LSTM在必须进行深度反向传播时维持恒定的误差。LSTM确定后续单元状态的方式并非将当前状态与新输入相乘,而是将两者相加,这正是LSTM的特别之处。(当然,遗忘门依旧使用乘法。)
不同的权重集对输入信息进行筛选,决定是否输入、输出或遗忘。遗忘门的形式是一个线性恒等函数,因为如果门打开,则记忆单元的当前状态就只会与1相乘,正向传播一个时间步。
此外,讲到简单的窍门,将每个LSTM单元遗忘门的偏差设定为1,经证明可以提升网络表现。(但Sutskever建议将偏差设定5。)
你可能会问,如果LSTM的目的是将远距离事件与最终的输出联系起来,那为什么需要有遗忘门?因为有时候遗忘是件好事。以分析一个文本语料库为例,在到达文档的末尾时,你可能会认为下一个文档与这个文档肯定没有任何联系,所以记忆单元在开始吸收下一个文档的第一项元素前应当先归零。
在下图中可以看到门的运作方式,其中横线代表关闭的门,而空心小圆圈则代表打开的门。在隐藏层下方水平一行的横线和圆圈就是遗忘门。
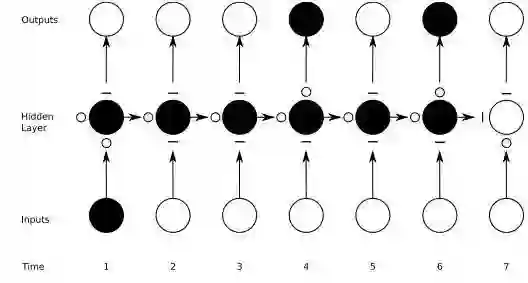
应当注意的是,前馈网络只能将一个输入映射至一个输出,而循环网络则可以像上图那样将一个输入映射至多个输出(从一张图像到标题中的许多词),也可以进行多对多(翻译)或多对一(语音分类)的映射。
多时间尺度与远距离依赖
你可能还会问,输入门阻止新数据进入记忆单元,输出门阻止记忆单元影响RNN特定输出,此时这两种门确切的值如何呢?可以认为LSTM相当于允许一个神经网络同时在不同时间尺度上运行。
以一个人的人生为例,想象一下我们如何以一个时间序列的形式接收有关的这一人生不同数据流。就地理位置而言,每个时间步的位置对下一个时间步都相当重要, 所以地理位置的时间尺度就是始终对最新的信息保持开放。
假设这个人是位模范公民,每隔几年就会投票。就民主生活的时间尺度而言,我们希望特别注意这个人在选举前后所做的事,关注这个人在搁下重大议题、回归日常生活之前的所作所为。我们不希望我们的政治分析被持续更新的地理位置信息所干扰。
如果这人还是个模范女儿,那我们或许可以增加家庭生活的时间尺度,了解到她打电话的模式是每周日一次,而每年过节期间电话量会大幅增加。这与政治活动周期和地理位置无关。
其他数据也是如此。音乐有复合节拍。文本包含按不同间隔反复出现的主题。股票市场和经济体在长期波动之余还会经历短期震荡。这些事件同时在不同的时间尺度上进行,而LSTM可以涵盖所有这些时间尺度。
门控循环单元GRU
门控循环单元(GRU)本质上就是一个没有输出门的LSTM,因此它在每个时间步都会将记忆单元中的所有内容写入整体网络。
LSTM超参数调试
以下是手动优化RNN超参数时需要注意的一些事:
小心出现过拟合,这通常是因为神经网络在“死记”定型数据。过拟合意味着定型数据的表现会很好,但网络的模型对于样例以外的预测则完全无用。
正则化有好处:正则化的方法包括l1、l2和丢弃法等。
保留一个神经网络不作定型的单独测试集。
网络越大,功能越强,但也更容易过拟合。不要尝试用10,000个样例来学习一百万个参数 参数 > 样例数 = 问题。
数据基本上总是越多越好,因为有助于防止过拟合。
定型应当包括多个epoch(使用整个数据集定型一次)。
每个epoch之后,评估测试集表现,判断何时停止(提前停止)。
学习速率是最为重要的超参数。可用deeplearning4j-ui调试;参见此图
总体而言,堆叠层是有好处的。
对于LSTM,可使用softsign(而非softmax)激活函数替代tanh(更快且更不容易出现饱和(约0梯度))。
更新器:RMSProp、AdaGrad或momentum(Nesterovs)通常都是较好的选择。AdaGrad还能衰减学习速率,有时会有帮助。
-
最后,记住数据标准化、MSE损失函数 + 恒等激活函数用于回归、Xavier权重初始化
原文链接: https://deeplearning4j.org/cn/lstm
如果在学习人工智能方面,你还有任何的疑惑,比如基础、学历、就业前景等等,扫描下方二维码加老师咨询,除了针对这些问题答疑解惑之外,还有「深度学习集训营」的完整课程大纲、深度学习礼包、优惠券等你来拿!名额有限,还等什么,扫一扫咨询吧!

当然,你还可以直接点击「阅读原文」,获取免费试听资格!




