学界 | 新型循环神经网络IndRNN:可构建更长更深的RNN(附GitHub实现)
选自arXiv
作者:Shuai Li等
机器之心编译
参与:张倩、黄小天
近日,澳大利亚伍伦贡大学联合电子科技大学提出一种新型的循环神经网络 IndRNN,不仅可以解决传统 RNN 所存在的梯度消失和梯度爆炸问题,还学习长期依赖关系;此外,借助 relu 等非饱和激活函数,训练之后 IndRNN 会变得非常鲁棒,并且通过堆叠多层 IndRNN 还可以构建比现有 RNN 更深的网络。实验结果表明,与传统的 RNN 和 LSTM 相比,使用 IndRNN 可以在各种任务中取得更好的结果。同时本文还给出了 IndRNN 的 TensorFlow 实现,详见文中 GitHub 链接。
循环神经网络 (RNN) [16] 已在动作识别 [8]、场景标注 [4] 、语言处理 [5] 等序列学习问题中获得广泛应用,并且成果显著。与卷积神经网络 ( CNN ) 等前馈网络相比,RNN 具有循环连接,其中最后的隐藏状态是到下一状态的输入。状态更新可描述如下:
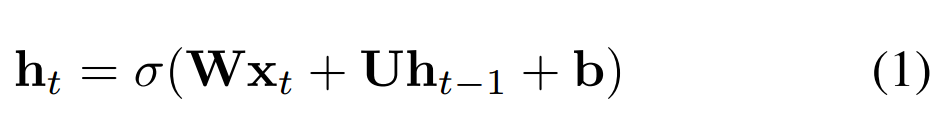
其中 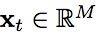
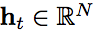
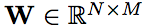
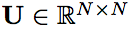
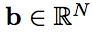
由于循环权重矩阵不断相乘,RNN 的训练面临着梯度消失和梯度爆炸的问题。长短期记忆 ( LSTM ) [ 10,17 ] 和门控循环单元 ( GRU ) [5] 等若干 RNN 模型可用来解决这些梯度问题。然而,在这些变体中使用双曲正切和 Sigmoid 函数作为激活函数会导致网络层的梯度衰减。因此,构建和训练基于 RNN 的深度 LSTM 或 GRU 其实存在困难。
相比之下,使用 relu 等非饱和激活函数的现有 CNN 可以堆栈到非常深的网络中 (例如,使用基本卷积层可以堆叠到 20 层以上;使用残差连接可以到 100 层以上 [12]),并且仍然在接受高效的训练。虽然在若干研究 [44, 36] 中已经尝试把残差连接用于 LSTM 模型,但情况并没有明显改善 (上述使用双曲正切和 sigmoid 函数的 LSTM 的梯度衰减是主要原因)。
此外,现有的 RNN 模型在 ( 1 ) 中使用相同的 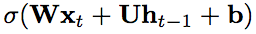
本文提出了一种新型循环神经网络——独立循环神经网络(IndRNN)。在 IndRNN 中,循环输入用 Hadamard 乘积处理为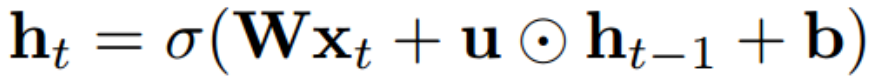
通过调节基于时间的梯度反向传播,可以有效地解决梯度消失和爆炸问题。
利用 IndRNN 可以保留长期记忆,处理长序列。实验表明,IndRNN 可以很好地处理 5000 步以上的序列,而 LSTM 能够处理的序列还不到 1000 步。
IndRNN 可以很好地利用 relu 等非饱和函数作为激活函数,并且训练之后非常鲁棒。
IndRNN 可以实现高效的多层堆叠以增加网络的深度,尤其是在层上具有残差连接的情况下。语言建模实验给出了一个 21 层 IndRNN 的实例。
由于各层神经元相互独立,就很容易解释每层 IndRNN 神经元的行为。
实验表明,IndRNN 在加法问题、序贯 MNIST 分类、语言建模和动作识别等方面的性能明显优于传统的 RNN 和 LSTM 模型。
3. 独立循环神经网络(IndRNN)
本文提出了一种独立循环神经网络 ( IndRNN ),具体描述如下:
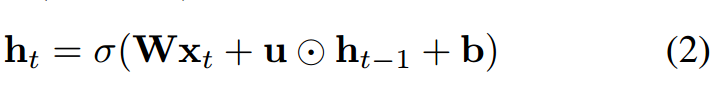
其中循环权重 u 是向量,
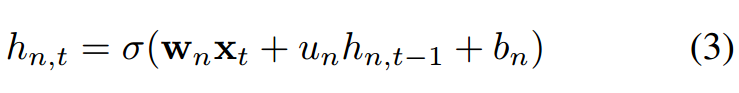
其中 w_n 和 u_n 分别是输入权重和循环权重的第 n 行。每个神经元仅在前一时间步从输入和它自己的隐藏状态中接收信息。也就是说,IndRNN 中的每个神经元独立地处理一种类型的时空模型。传统上,RNN 被视为时间上的、共享参数的多层感知器。与传统的 RNN 不同的是,本文提出的 IndRNN 神经网络为循环神经网络提供了一个新视角,即随着时间的推移 (即通过 u ) 独立地聚集空间模式 (即通过 w )。不同神经元之间的相关性可以通过两层或多层的堆叠来加以利用。在这种情况下,下一层的每个神经元处理上一层所有神经元的输出。
4. 多层 IndRNN
如上所述,同一 IndRNN 层中的神经元彼此独立,时间上的跨通道信息通过多层 IndRNN 进行探索。
IndRNN 基本架构如图 1(a) 所示,其中「weight」和「Recurrent+ ReLU」表示以 relu 作为激活函数的每个步骤的输入处理和循环处理。通过堆叠此基本架构,可以构建深度 IndRNN 网络。
基于 [13] 中残差层的「预激活」类型的残差 IndRNN 实例见图 1(b)。在每个时间步,梯度都可以从恒等映射直接传播到其他层。由于 IndRNN 解决了随时间累积的梯度爆炸和消失的问题,所以梯度可以在不同的时间步上有效地传播。因此,网络可以更深更长。
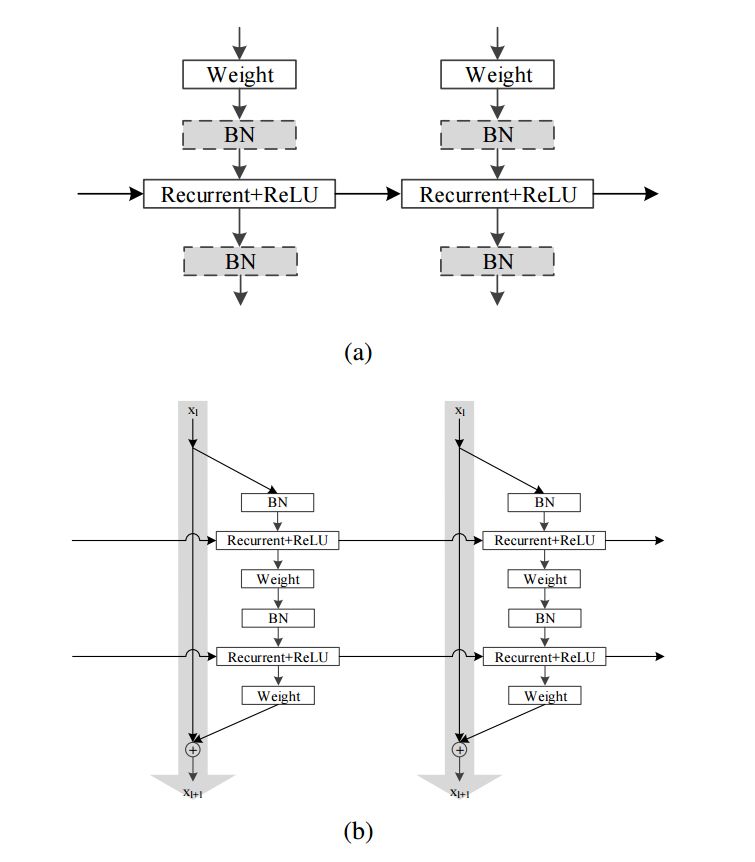
图 1:( a ) 为 IndRNN 基本架构图解;( b ) 为残差 IndRNN 架构图解。
5. 实验
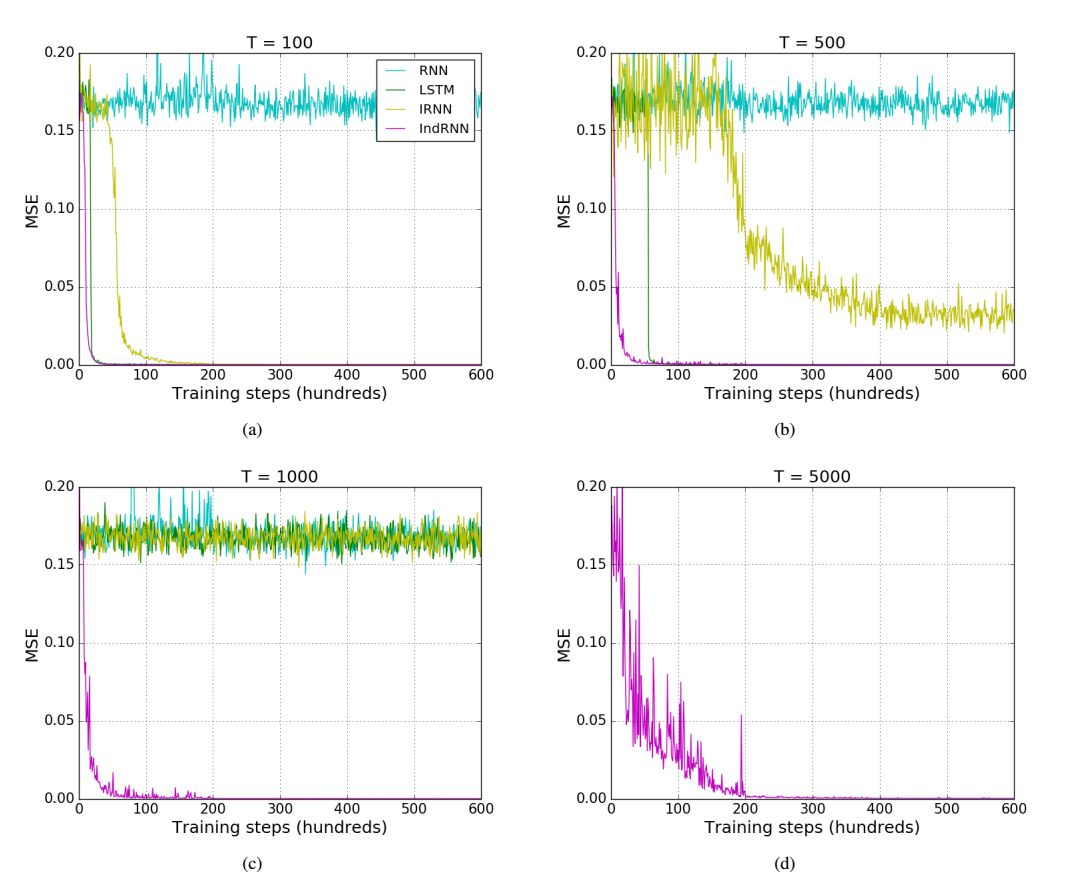
图 2:不同序列长度情况下解决相加问题的结果。所有图的图例相同,因此仅在 ( a ) 中示出。
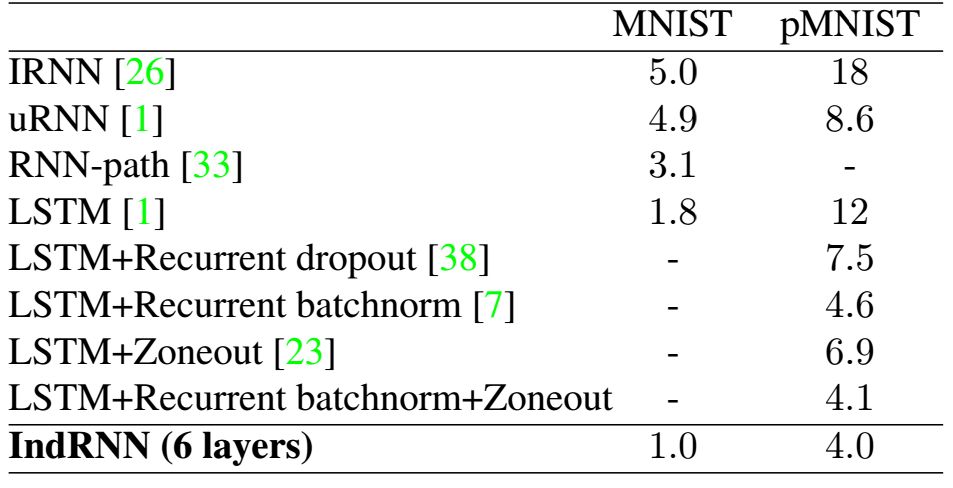
表 1:序贯 MNIST 和置换 MNIST(误差率 ( % ) ) 结果。
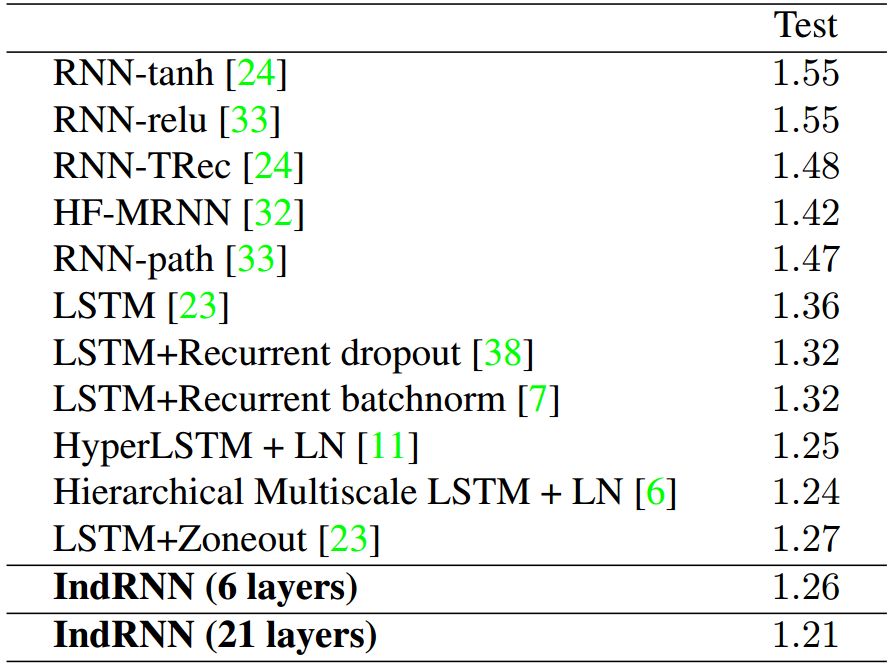
表 2:IndRNN 模型的 PTB-c 结果与文献记录结果的对比(基于 BPC)。
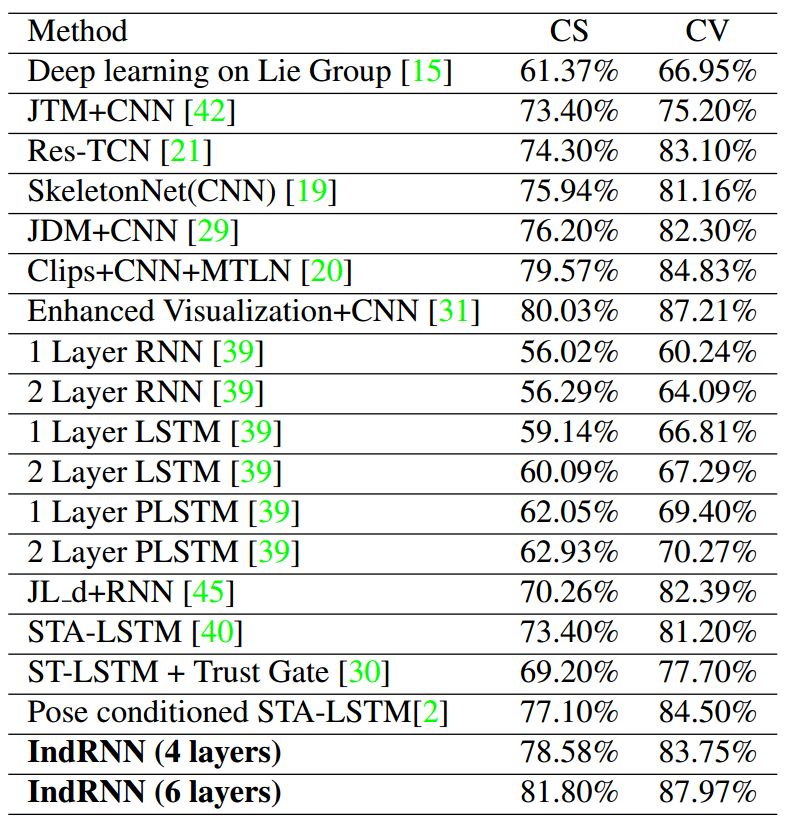
表 3:所有基于骨架的方法在 NTU RGB+D 数据集上的结果。
论文:Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN

论文链接:https://arxiv.org/abs/1803.04831
摘要:循环神经网络 ( RNN ) 已广泛应用于序列数据的处理。然而,由于众所周知的梯度消失和爆炸问题以及难以保持长期学习的模式,RNN 通常难以训练。长短期记忆 ( LSTM ) 和门控循环单元 ( GRU ) 被用来解决这些问题,但是双曲正切函数和 sigmoid 函数的使用会导致层上梯度衰减。因此,构建可有效训练的深度网络颇具挑战性。此外,每层 RNN 中的所有神经元都连接在一起,它们的运行状况很难解释。针对这些问题,本文提出了一种新的循环神经网络——独立循环神经网络 ( IndRNN ),即同一层的神经元相互独立,跨层连接。我们指出,IndRNN 可以通过简单的调节避免梯度爆炸和消失问题,同时允许网络学习长期依赖关系。此外,IndRNN 可以使用 relu 等非饱和激活函数,训练之后可变得非常鲁棒。通过堆叠多层 IndRNN 可以构建比现有 RNN 更深的网络。实验结果表明,本文中的 IndRNN 能够处理很长的序列 (超过 5000 个时间步),可以用来构建很深的网络 (实验中使用了 21 层),并且经过训练还可以更加鲁棒。与传统的 RNN 和 LSTM 相比,使用 IndRNN 可以在各种任务中取得更好的结果。
GitHub实现
上文是 IndRNN 具体的论文简介,论文作者其实还提供了该循环架构的 TensorFlow 实现代码和试验结果。我们发现架构代码中有非常详尽的参数解释,因此各位读者可参考 ind_rnn_cell.py 文件详细了解 IndRNN 的基本架构。此外,作者表示该实现使用 Python 3.4 和 TensorFlow 1.5 完成,所以我们可以在该环境或更新的版本测试。
项目地址:https://github.com/batzner/indrnn
1. 用法
将 ind_rnn_cell.py 文件复制到你的项目目录中,如下展示了 IndRNN 单元的简单调用过程:
from ind_rnn_cell import IndRNNCell
# Regulate each neuron's recurrent weight as recommended in the paper
recurrent_max = pow(2, 1 / TIME_STEPS)
cell = MultiRNNCell([IndRNNCell(128, recurrent_max_abs=recurrent_max),
IndRNNCell(128, recurrent_max_abs=recurrent_max)])
output, state = tf.nn.dynamic_rnn(cell, input_data, dtype=tf.float32)
...2. 原论文中提到的实验
有关本文中重构「相加问题」的相关脚本,请参见示例 examples/addition_rnn.py。更多实验(如 Sequential MNIST)将在今后几天进行更新与展示。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





