【AAAI2022】视觉语言Transformer学习多模态表示吗?探索的角度来看

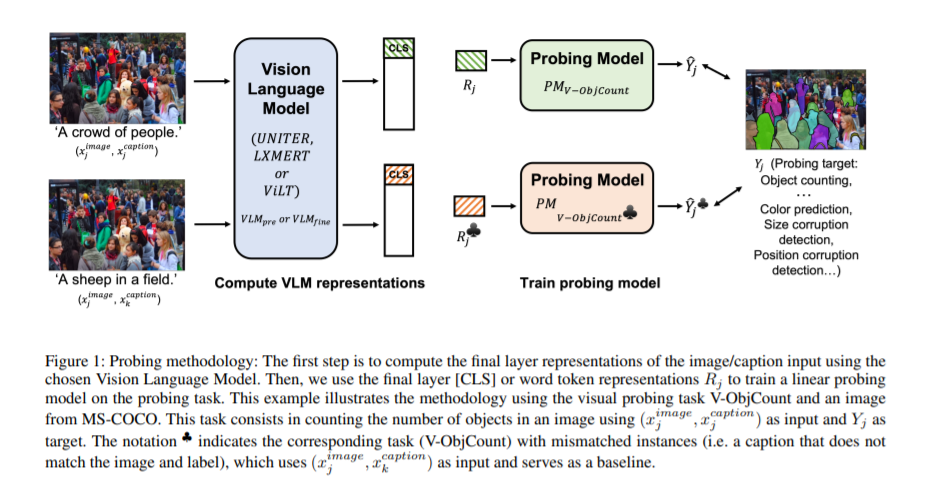
近年来,由于基于Transformer的视觉-语言模型的发展,联合文本-图像嵌入得到了显著的改善。尽管有这些进步,我们仍然需要更好地理解这些模型产生的表示。在本文中,我们在视觉、语言和多模态水平上比较了预训练和微调的表征。为此,我们使用了一组探测任务来评估最先进的视觉语言模型的性能,并引入了专门用于多模态探测的新数据集。这些数据集经过精心设计,以处理一系列多模态功能,同时最大限度地减少模型依赖偏差的可能性。虽然结果证实了视觉语言模型在多模态水平上理解颜色的能力,但模型似乎更倾向于依赖文本数据中物体的位置和大小的偏差。在语义对抗的例子中,我们发现这些模型能够精确地指出细粒度的多模态差异。最后,我们还注意到,在多模态任务上对视觉-语言模型进行微调并不一定能提高其多模态能力。我们提供所有的数据集和代码来复制实验。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VLTL” 就可以获取《【AAAI2022】视觉语言Transformer学习多模态表示吗?探索的角度来看》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月19日



相关VIP内容
相关资讯