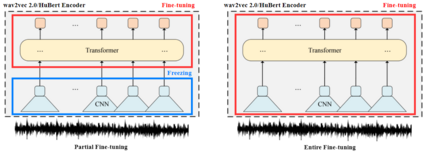
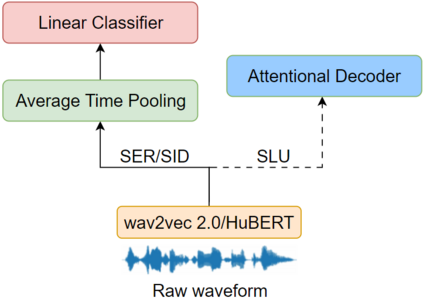
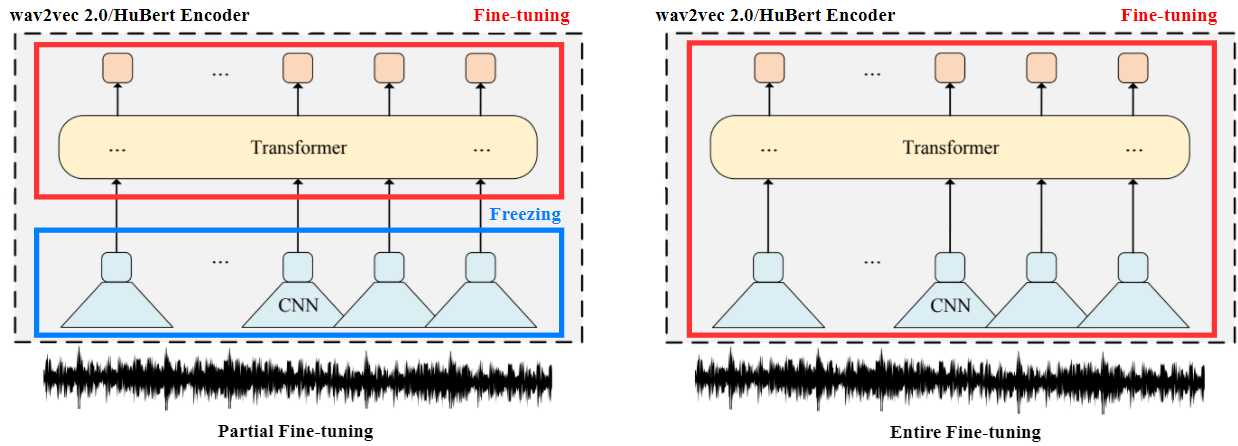
Speech self-supervised models such as wav2vec 2.0 and HuBERT are making revolutionary progress in Automatic Speech Recognition (ASR). However, they have not been totally proved to produce better performance on tasks other than ASR. In this work, we explore partial fine-tuning and entire fine-tuning on wav2vec 2.0 and HuBERT pre-trained models for three non-ASR speech tasks : Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. With simple proposed down-stream frameworks, the best scores reach 79.58% weighted accuracy for Speech Emotion Recognition on IEMOCAP, 2.36% equal error rate for Speaker Verification on VoxCeleb1, 89.38% accuracy for Intent Classification and 78.92% F1 for Slot Filling on SLURP, thus setting new state-of-the-art on the three benchmarks, showing the strong power of fine-tuned wav2vec 2.0 and HuBERT models on learning prosodic, voice-print and semantic representations.
翻译:诸如 wav2vec 2. 0 和 HuBERT 等自我监督的演讲模式在自动语音识别方面正在取得革命性的进展。 但是,它们并没有被完全证明能产生比 ASR 更好的业绩。 在这项工作中,我们探索了对 wav2vec 2.0 和 HubaERT 三个非ASR 演讲任务经过培训的模型进行部分微调和整个微调: 语音识别、 发言人核查和口语理解。 有了简单的下游框架, 最佳评分达到79.58%的加权精确度, VoxCeleb 语音识别的加权精确度为2.36%, VentCeleb1 的演讲者校验率为8.38%, Intelcation 精确度为89.38%, SLURP 填充时为78.92% F1, 从而为三种基准设定了新的艺术水平,显示了微调 wav2vec 2.0 和 HuBERT 模型在学习Prosodic、语音和语义表达方式方面的强大力量。