【CVPR2022】基于渐进自蒸馏的鲁棒跨模态表示学习

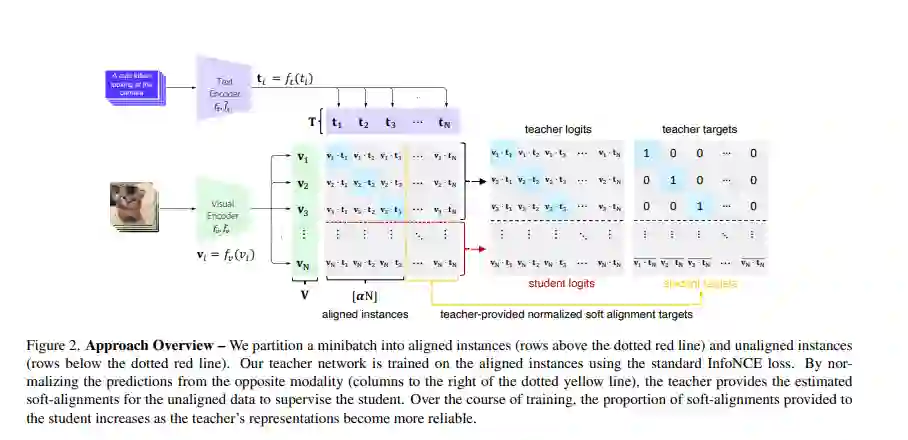
CLIP视觉语言方法的学习目标未能有效地考虑到网络采集的图像描述数据集存在的多对多的噪声,导致其计算和数据效率低下。为了解决这一挑战,我们引入了一种基于跨模态对比学习的新训练框架,该框架使用渐进自蒸馏和软图像-文本对齐,以更有效地从噪声数据中学习鲁棒表示。我们的模型提炼自己的知识,为每个小批中的图像子集和标题动态地生成软对齐目标,然后用来更新其参数。在14个基准数据集上的广泛评估表明,我们的方法在多种设置下始终优于CLIP对应的方法,包括:(a)零样本分类,(b)线性探针传输,(c)图像-文本检索,而不增加计算成本。使用基于ImageNet的鲁棒性测试平台的分析表明,与经过ImageNet训练的模型和CLIP本身相比,我们的方法对自然分布转移提供了更好的有效鲁棒性。最后,使用两个数量级的数据集进行预训练表明,我们对CLIP的改进往往与训练示例的数量成比例。
https://arxiv.org/abs/2204.04588
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LPSD” 就可以获取《【CVPR2022】基于渐进自蒸馏的鲁棒跨模态表示学习》专知下载链接



登录查看更多
相关内容


相关VIP内容
相关资讯