【CVPR2021】基于端到端预训练的视觉-语言表征学习


本文研究了卷积神经网络(CNN)和视觉语言预训练Transformer(VLPT)的联合学习,旨在从数百万个图像-文本对中学习跨模态对齐。
当前大多数文章都是先抽取出图像中的显著性区域,再将其与文字一一对齐。由于基于区域的视觉特征通常代表图像的一部分,因此现有的视觉语言模型要充分理解配对自然语言的语义是一项挑战。由于基于区域的视觉特征通常代表图像的一部分,现有的视觉语言模型很难完全理解成对自然语言的语义。
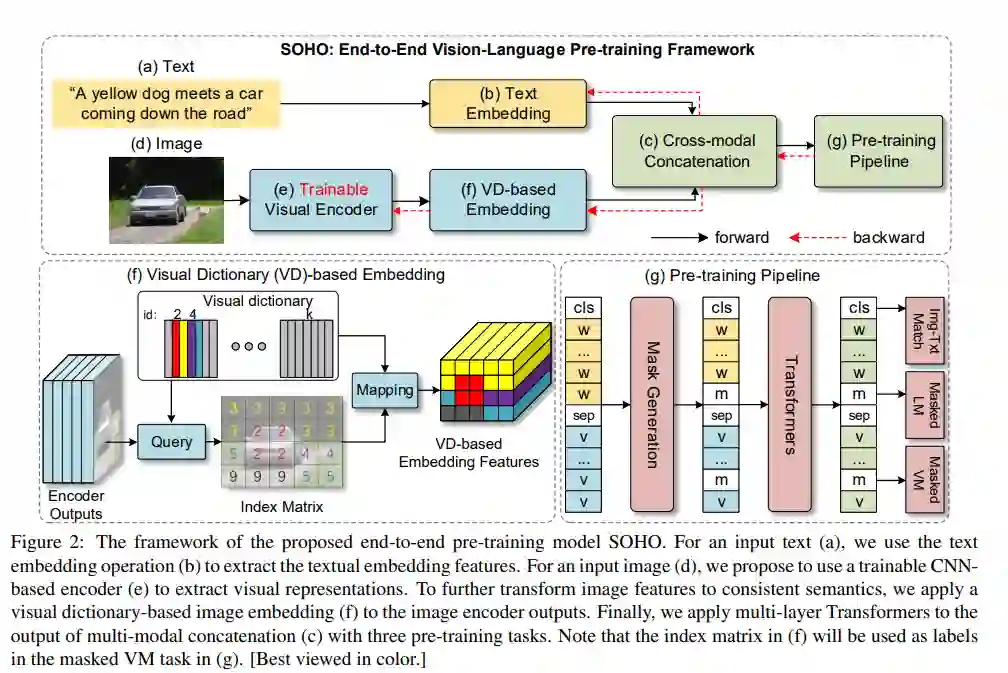
本文提出SOHO“开箱即看”的概念,将完整的图像为输入,以一种端到端的方式学习视觉语言表达。SOHO不需要边界框标注,这使得推理速度比基于区域的方法快10倍。特别地,SOHO学会了通过视觉词典(VD)来提取全面而紧凑的图像特征,这有助于跨模态理解。大量的实验结果也验证了本文SOHO的有效性。
原文下载链接:
https://www.zhuanzhi.ai/paper/a8c52c4b641c0a5bc840a955b6258b39
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VLPT” 就可以获取《【CVPR2021】基于端到端预训练的视觉-语言表征学习》专知下载链接



登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文