利用内容选择来加强生成式摘要


文章自动摘要(text summarization)技术是自然语言处理领域中一项重要的应用,其致力于将自然语言中长文本语句压缩成语义高度概括的短文本。摘要技术主要可以分为两个类别:抽取式(extractive summarization)和抽象式(abstractivesummarization)。抽取式摘要直接从文档中抽取句子或段落作为文章的摘要,而抽象式摘要需要对文章的内容进行压缩和改写。
相比较抽象式摘要,抽取式的技术相对简单、技术成本较低,且因为直接从原文中摘取句子,所以抽取的单个句子语法和语义错误较少。但是这种方法产生的摘要灵活性很差,一方面很难保证抽取的句子间语义相互关联又不重叠,另一方面受限于摘要的字数,此类方法很难处理信息量冗余的长句。近些年来,随着一些生成式的神经网络模型的出现,抽象式技术已经可以产生非常流利的摘要,但是在文档的内容相关性上还是较差。目前性能最好的摘要模型都结合了抽取式和抽象式两种技术,通过类似Pointer Generator[1]模型来从文档中复制词汇。
本篇文章带大家来阅读一篇来自EMNLP2018的文章,Bottom-Up Abstractive Summarization[2]。该论文主要提出使用一个data-efficient content selector来确定文档中重要的短语,然后利用这个选择器的结果来约束生成式模型的输出。另外文中也提到,由于内容选择器的训练只需要使用千级别的训练数据,使得它能迁移到新的领域的摘要模型中。这篇文章提出的方法在CNN-DM和NYT两份数据集上大部分指标都取得了现有最好水平。
首先,我们先回顾一下在文档摘要中非常重要的模型pointer- generator。
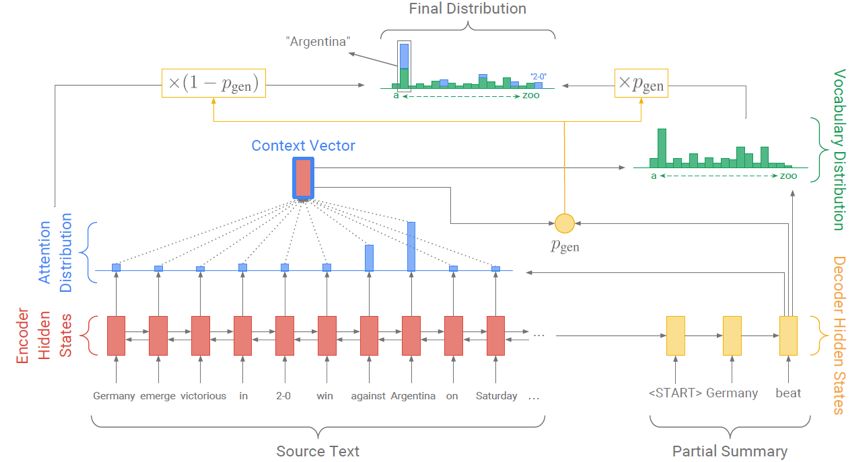
图1
模型结构如上图所示,Pointer-Generator在传统的基于attention的端到端生成模型的基础上,引入了类似copy net的机制。解码时,每个时刻先预测一个soft switch来表示复制或者生成。Copy distribution可以用对应源端的attention distribution来表示,一个词的copy概率即为源端所有attend到这个词的权重求和,其对应的词表是源端所有词。Generation分布对应的是整个预设的词表,一个词的generation概率由当前状态的输入和前一时刻的隐藏状态共同决定。具体生成一个词y的概率如下式所示:
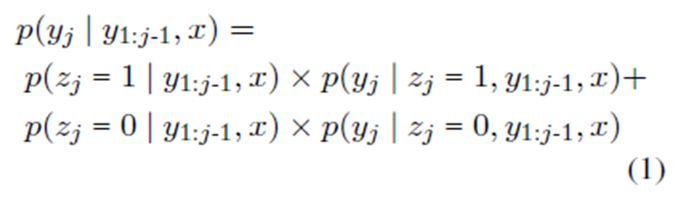
Pointer-Generator理论上可以生成一些遵循作者观点又通顺的语句,但是在实践中发现其生成的摘要往往倾向于copy源端的一整句话,极端情况下则退化为抽取式的模型。而这篇论文提出自底向上分步的训练方法(bottom-up attention)则可以生成一些包含重要信息且更具备压缩性的语句。
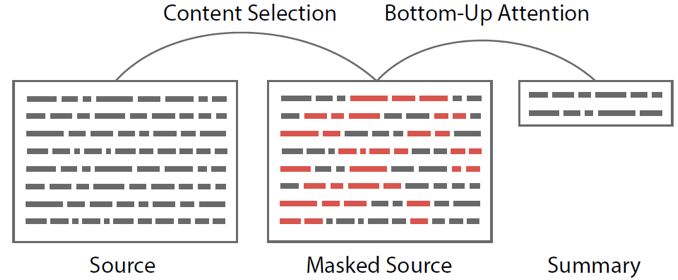
图2
作者的想法非常简单,因为现有的类似Pointer-Generator的模型在源端内容上选择能力不足,本文主要考虑在抽象式摘要的生成中,结合一个有效的内容选择器。具体地,如图2所示,作者先利用内容选择器来选择一些重要的短语(类似关键词),然后在此基础上利用公式1来生成最终的摘要结果。
内容选择器
本文将内容选择的问题形式化为一个序列化标注问题。标注模型需要的训练数据通过对齐源文档和参考摘要来生成。作者启发式地定义了一些对齐的规则。对于源端的一个词Xi ,如果它同时满足以下两个条件,则应该被内容选择器选中:
(1)它是源端x和参考摘要y中最长的公共子序列的一部分,
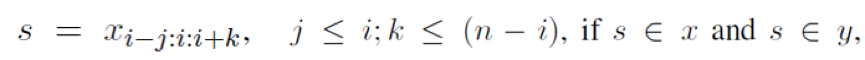
(2)这个子序列没有在之前的文档中出现过。
具体的标注模型上,本文使用了考虑两种词向量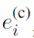
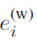
本文提出了几种结合内容选择器的训练方案。首先第一种方案,作者先在原始训练数据上训练一个pointer-generator模型,再独立地训练一个内容选择器,只在预测时采用分步的生成方法。具体的计算拷贝概率的公式如下所示,其中qi 是标注模型预测的得分,如果得分高于一个阈值
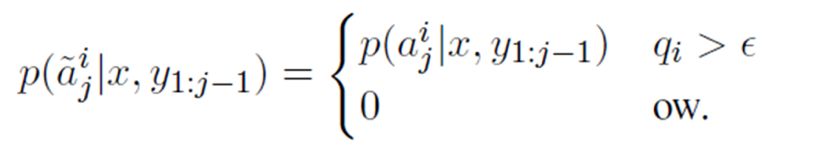
另外作者提出了三种端到端的训练方式:
(1)MASK ONLY:只在训练模型时使用mask(使用内容选择器的结果),即直接在内容选择器的输出结果上训练一个Pointer Generator模型,在测试时不做mask;
(2) MULTI-TASK:在训练时让content selector和Pointer-Generator两个模型共享一个编码器,分步的mask attention只在测试时做;
(3)DIFFMASK:这是一种完全可微分的方案,其利用内容选择器的输出概率来软截断从源端拷贝词的概率,即
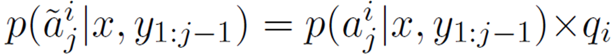
训练时联合来优化两个部分的损失函数。
当然作者在训练时也使用了一些不同的惩罚项,比如为了让模型输出尽可能长的句子,引入了一个长度惩罚lp,为了减缓生成语义重复的摘要的问题,使用了一种新的coverage惩罚cp,同时在做beam search时限制不会出现重复的trigram。如下式所示:
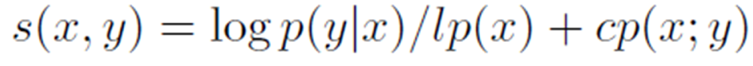
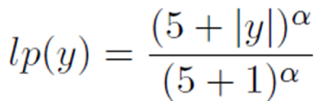
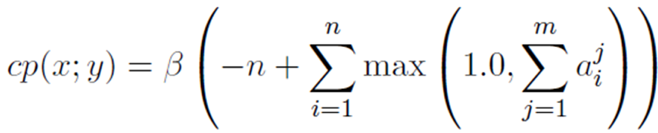
数据集和评价指标
实验数据集是CNN-DM和NYT新闻数据,评价指标为Rouge-1、Rouge-2和Rouge-L。
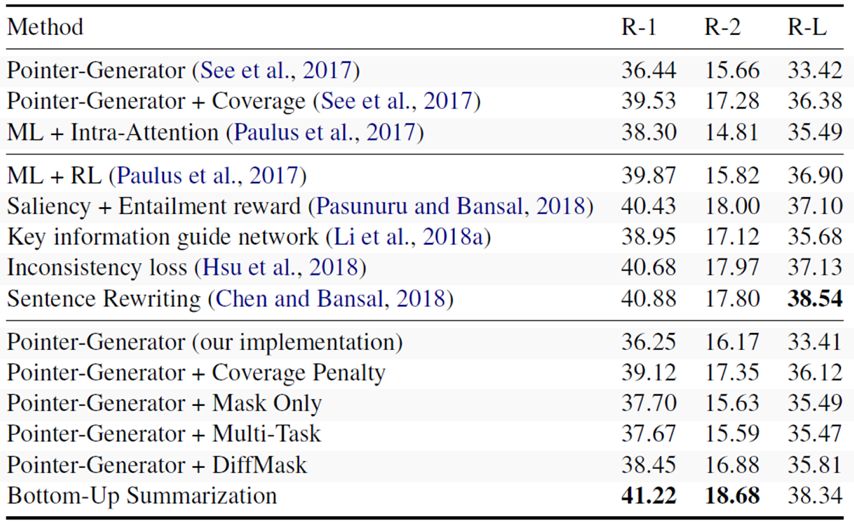
表 1
表1显示了本文在CNN-DM数据集上的结果,第一栏是抽象式摘要模型的结果,第二栏是使用强化学习的策略来生成摘要的方法,最底下一栏是本文提出的几种训练方式的结果。可以看出,三种端到端训练的结果都很一般,在训练时同时优化整个流程似乎有些问题,使用分步的训练方法则在Rouge-1和Rouge-2上取得了最好的结果,在Rouge-L上取得了接近最好的结果。
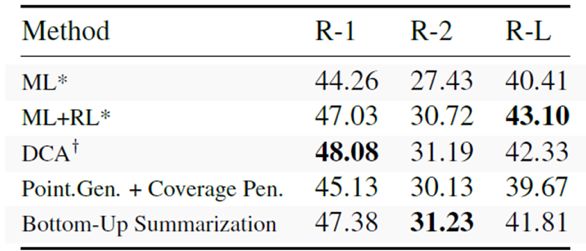
表2显示了本文在NYT数据集上的结果,相比较一些强化学习的模型,这种训练方式取得的结果依然很有竞争性。
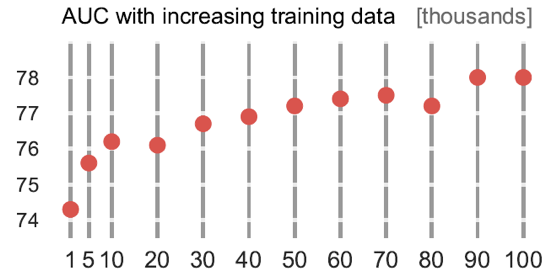
图3
另外作者发现,训练一个二元的内容选择器,只需要很少的训练数据即可学到一个不错的模型。由图3可以看出,只需要1000条标注数据,模型就已经取得了74的结果。
所以它考虑在一个大的数据集上训练一个Pointer-Generator模型,再在数据比较少的数据集上学习一个content selector,之后拿这两个模型在小数据上预测,进行迁移学习。
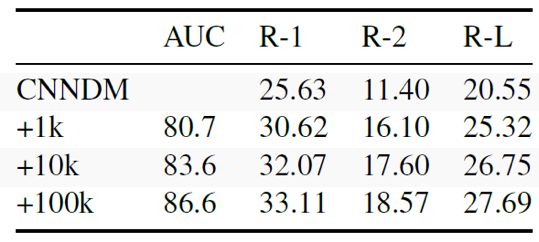
表3
表3展示了模型从CNN-DM数据集迁移到NYT数据集的训练结果。作者先在CNN-DM上训练一个生成式摘要模型,然后分别加入不同数量级的NYT数据来训练内容选择器。这个技术可以作为领域稀疏数据生成摘要的一种尝试。
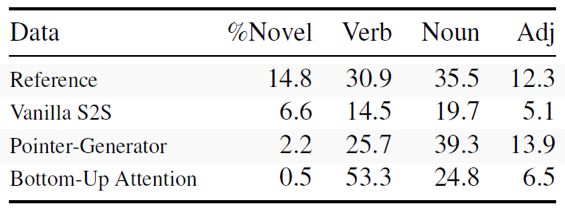
表4分析了不同方法生成的摘要中新词的比例,以及各个词性的分布。Bottom-up attention方法产生的新词比例比原始Pointer-Generator模型更低,且倾向于生成一些重要的动词。这个结果也显示了目前的混合模型作用更多在产生流利的句子上,但是在句子的改写方面仍然能力不足。
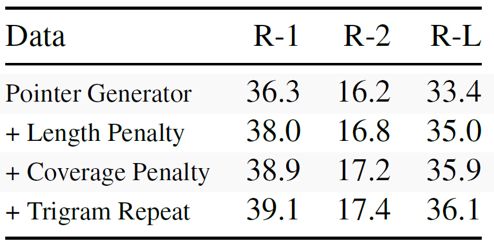
表5
表5展示了在CNN-DM数据集上的结果,加入不同惩罚项对最终结果有近3个点的影响。
论文提出的模型是在Pointer-Generator的基础上做了一些改进,方法更像是一种训练的trick。笔者认为这篇文章带给我们的启发是在抽象式摘要中引入了一种更强的内容选择器,即只从源文档中复制重要的词,以解决现有的生成式摘要模型产生与原文不相关句子的痛点。作者在论文中也公布了相应的源码,感兴趣的同学可以去查阅:https://github.com/sebastianGehrmann/bottom-up-summary。
参考文献
1. Get To ThePoint: Summarization with Pointer-Generator Networks. https://arxiv.org/pdf/1704.04368.pdf
2. Bottom-UpAbstractive Summarization, https://arxiv.org/pdf/1808.10792.pdf
3. Deepcontextualized word representations, https://arxiv.org/pdf/1802.05365.pdf

 微信ID:WeChatAI
微信ID:WeChatAI

登录查看更多
相关内容

专知会员服务
33+阅读 · 2020年4月24日
Arxiv
4+阅读 · 2020年3月5日
Arxiv
7+阅读 · 2019年10月21日




相关VIP内容
专知会员服务
33+阅读 · 2020年4月24日
相关资讯
相关论文
Arxiv
4+阅读 · 2020年3月5日
Arxiv
7+阅读 · 2019年10月21日