用深度学习做文本摘要
【导读】随着互联网的兴起,我们可以随时获取大量信息。通过序列模型,我们可以构建良好的文本摘要模型。
作者:Priya Dwivedi @ Deep Learning Analytics
文本摘要有两种类型:
1. 抽取型摘要 - 此方法从源文本中选择段落,并将其列为摘要。这就像用荧光笔突出显示重要部分。它的主要思想是汇总文本是源文本的子部分。
2.抽象概括 - 相比之下,抽象方法涉及理解意图并用你自己的话写出摘要。
自然抽象概括更具挑战性。这是机器学习进展缓慢的一个领域,也是一个难题,因为创建抽象摘要需要控制主题和自然语言的表达,这对于机器来说很困难。此外,针对此问题没有大数据集。这里的数据集包括源文本及其抽象摘要。 然而在新闻中,则能看到很多摘要的例子,如在发表新闻文章时,专业作家不断总结如下CNN新闻片段中所示的信息:

深度学习的文本摘要
进行文本摘要的标准方法是使用seq2seq模型。 典型如Pointer Generator的模型结构。
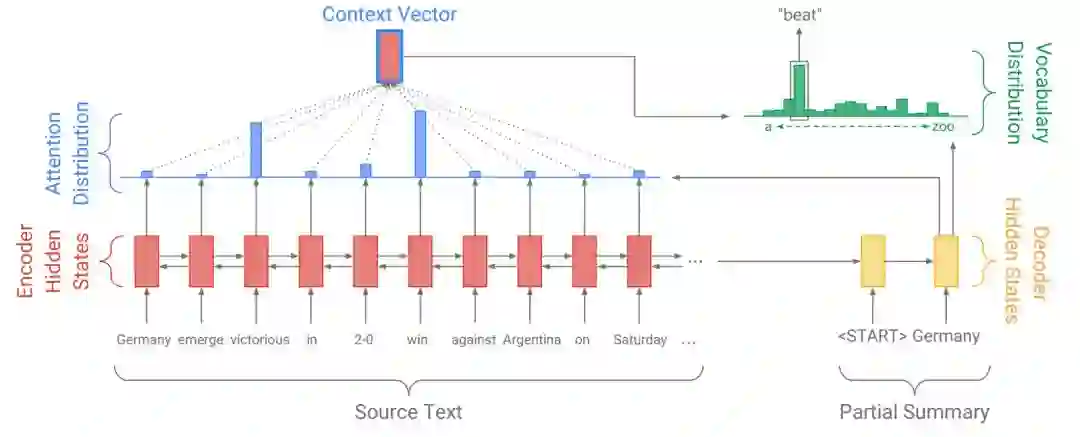
序列模型有三个主要部分:
1.编码器 - 从原始文本中提取信息的双向LSTM层,如上图的红色部分。双向LSTM一次读取一个字,并根据当前字和之前读过的字更新其隐藏状态。
2.解码器 - 单向LSTM层,一次生成一个字的摘要。它使用来自编码器的信息以及之前编写的信息来创建下一个字的概率分布。解码器以黄色显示,概率分布为绿色。
3.注意力机制 - 编码器和解码器是这里的构建块,但历史上编码器解码器架构本身没有引起注意并不是很成功。在没有注意力机制的情况下,解码器的输入是编码器的最终隐藏状态,可以是256或512维矢量,如果我们想象这个小矢量不可能拥有其中的所有信息,那么它就成了信息瓶颈。通过注意力机制,解码器可以访问编码器中的中间隐藏状态,并使用所有这些信息来决定下一个字。在图中,注意力以蓝色显示。
正如Pointer Generator论文所示,上述架构足以开始使用,但由它创建的摘要有两个问题:
这些摘要有时会不准确地重现事实细节(例如德国队以3-2击败阿根廷队)。这对于罕见或词汇外的单词(例如2-0)尤其常见。
摘要经常出现重复词。 (例如德国击败德国击败德国击败...)
Point Generator模型通过创建一个指针机制来解决这些问题,该指针机制允许它在生成文本和复制之间切换。源指针。指针的调整为0和1之间的概率标量。如果它是1则模型执行抽象生成一个单词,如果为0则复制该单词。
与序列到序列的注意系统相比,Point Generator网络有几个优点:
指针生成器网络可以轻松复制源文本中的单词。
指针生成器模型甚至能够复制源文本中的词汇外单词。这是一个重要的奖励,使我们能够处理看不见的单词,同时也允许我们使用较小的词汇表(这需要较少的计算和存储空间)。
指针生成器模型训练更快,需要更少的训练迭代以实现与序列到序列注意系统相同的性能。
实验结果
我们在Tensorflow中实现了这个模型,并在CNN / Daily Mail数据集上进行了训练。该模型获得了0.38的Rouge-1得分。我们观察到,该模型在创建新闻文章的摘要方面做得非常好,这些摘要是它所训练的数据。然而,如果提出的文本不是新闻,它仍然会创建很好的摘要,但这些摘要本质上更具有提取性。
原文链接:
https://towardsdatascience.com/text-summarization-using-deep-learning-6e379ed2e89c
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!520+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程


