
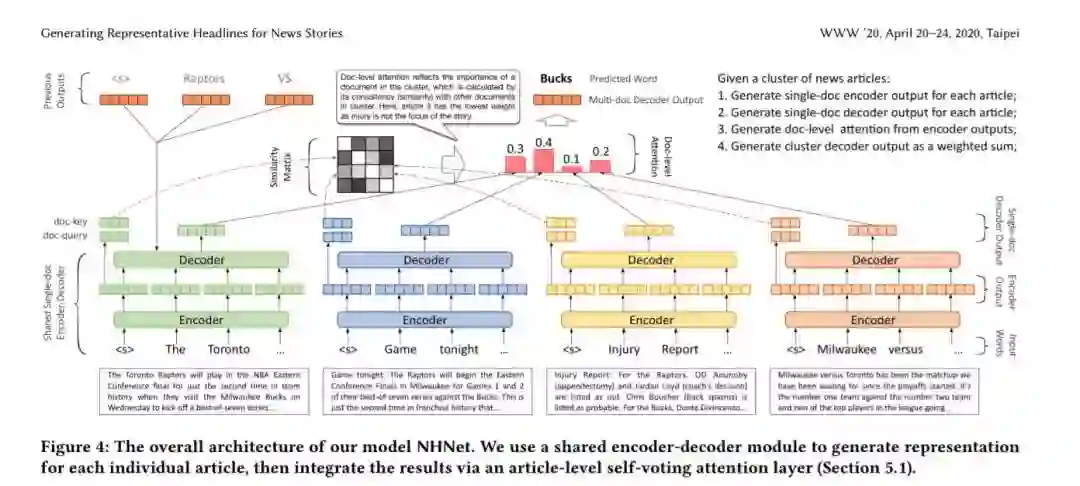
每天都有数以百万计的新闻文章在网上发布,这对读者来说是难以承受的。将报道同一事件的文章分组成新闻报道是帮助读者进行新闻消费的一种常见方式。然而,如何高效、有效地为每一个故事生成一个有代表性的标题仍然是一个具有挑战性的研究问题。文档集自动摘要的研究已经有几十年的历史了,但是很少有研究关注于为一组文章生成具有代表性的标题。摘要的目的是用最少的冗余捕获最多的信息,而标题的目的是短篇幅捕获由story文章共同共享的信息,并排除对每一篇文章过于具体的信息。在这项工作中,我们研究的问题,产生具有代表性的新闻故事标题。我们开发了一种远监督方法来训练大规模的没有任何人工标注的生成模型。这种方法集中在两个技术组件上。首先,我们提出了一个多层次的预训练框架,该框架融合了大量不同质量的未标记语料库。我们证明,在这个框架内训练的模型比那些使用纯人类策展语料库训练的模型表现得更好。其次,我们提出了一种新的基于自投票的文章注意层来提取多篇文章共享的显著信息。我们证明了该层模型对新闻中潜在的干扰具有较强的鲁棒性,无论是否存在干扰,其性能都优于已有的基线。我们可以通过合并人类标签来进一步增强我们的模型,我们展示了我们的远监督方法,这大大减少了对标签数据的需求。
成为VIP会员查看完整内容
相关内容

Arxiv
9+阅读 · 2018年5月31日
相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2018年5月31日