论文浅尝 | 通过文本到文本神经问题生成的机器理解
论文笔记整理:程茜雅,东南大学硕士,研究方向:自然语言处理,知识图谱。

Citation: Yuan X, WangT, Gulcehre C, et al. Machine comprehension by text-to-text neural question generation[J]. arXiv preprint arXiv:1705.02012, 2017.
动机
1、在智能系统里提出合适的问题有利于信息获取。
2、学会提出问题有利于提高回答问题的能力。
3、在大多数QA(Question Answering)数据集中回答问题属于抽取式(extractive)任务,相比较而言,提出问题属于生成式(abstractive)任务。
4、提出一个好的问题所包含的技能远超于回答问题所需的技能。因为一个问题通常只有一个答案,但是针对一个答案可能有多个问题。因此提出一个高质量的问题较难。
5、QG(Question Generation)应用广泛。譬如:为QA生成训练数据,自动导师系统等。
基于上述动机,本文构建了一个用于QG的神经模型,并将其应用在包含QA的任务中。这是第一个针对QG的端到端、文本到文本的模型。
方法
本文使用了encoder-decoder框架,其中encoder负责处理答案和文本,decoder负责生成问题。最后使用强化学习训练模型。
1、Encoder-Decoder框架
(1) Encoder
输入问题的答案和与问题有关的文本这两段序列。获取它们的word embeddings。给文本中每个word embedding增加一个二元特征来表示文本中的单词是否属于答案。使用双向LSTM神经网络对文本进行编码,得到每个单词的annotation向量(其实就是隐状态),并最终得到文本的语境向量。另外,将文中属于答案的单词的annotation向量组合起来,并且和答案的wordembedding一一对应联结,并输入到一个双向LSTM神经网络中进行编码,将每个方向的隐状态联结起来得到基于文本的答案编码向量(extractive condition encoding)。将该extractive condition encoding和文本的语境向量相联结,得到最终的语境向量,送入decoder中。
(2) Decoder
基于encoder的文本和答案,生成问题。并使用了pointer-softmax formulation,选择从原文本中copy或者自己生成。使用LSTM和attention机制生成问题。
2、政策梯度优化
(1) 动机
因为在训练encoder-decoder模型的过程中通常会使用teacher forcing,该方法存在一个弊端,它会阻止模型犯错,进而无法从错误中学习。所以本文使用强化学习来缓解这个问题。
(2) Rewards
本文在强化学习过程中使用了两种rewards,分别是QA的精确度结果R_qa和流畅性R_ppl。
QA:将模型生成的问题和原文本输入到QA模型中(本文用的是MPCM模型),得到答案,将该答案的精确度作为 reward R_qa,对模型进行激励。
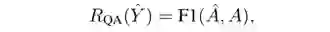
流畅性(PPL):衡量生成问题的流畅性和语法正确性作为reward R_ppl,本文使用了perplexity。
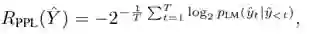
最后分别对R_qa和R_ppl赋予权重,并相加得到总的reward。
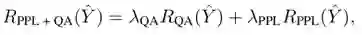
(3) Reinforce
使用REINFORCE算法最大化模型的预期reward。
实验
1、数据集
本文使用的是SQuAD数据集。
2、Baseline
使用包含attention和pointer-softmax的Seq2Seq模型作为baseline模型。该模型除了在获取基于文本的答案编码向量(extractive condition encoding)的方法上与本文的模型不同之外,其余部分和本文的模型一样,baseline模型将所有文本的annoation向量取平均值作为基于文本的答案编码向量(extractive condition encoding)。
3、评测方法
本文只使用了自动评测的方法。评测指标分别是:NLL(negative log-likelihood)、BLEU、F1、QA(MPCM生成的问题精度)和PPL(perplexity)。
评测结果如下图所示:
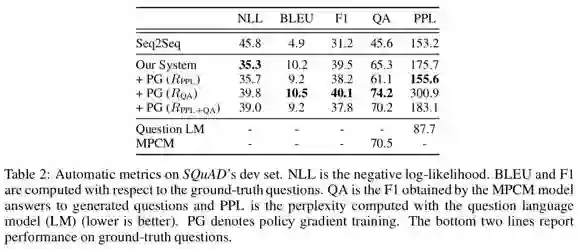
4、结论
(1) 模型的BLEU值很低,这是因为针对一个文本和答案,可能有多个不同的问题。
(2) baseline 模型生成的问题流畅但比较模糊,本文的模型生成的问题更加具体,但是流畅性低,存在错误。
下图是各个模型针对text生成的问题。

(3)本文作者最后提出未来将研究人工评测来确定rewards和人类判断之间的关系,以此提升模型的效果。
思考与所得
依我之见,这篇文章有两个亮点值得借鉴。
1、对answer的编码处理方法。一般对于answer就是将它输入到一个RNN中,得到最后的隐状态。这种方式有一种弊端,得到的答案语境向量是脱离原文本而存在的,与文本的关联性较小。于是本文从输入的原文中找到对应于答案的annotation向量,将其组合起来,并将其一一和答案的word embedding相联结,输入到LSTM中进行编码,得到基于文本的答案向量。这样子就增强了答案向量和文本的相关性。
2、使用了政策梯度优化的强化学习方法训练模型。由于一般在训练过程中使用的teacher forcing无法让模型犯错,无法从错误中学习,所以本文用了强化学习的方法解决这个问题,其中针对本文的QG任务使用了两个特定的rewards。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



