屠榜目标跟踪!SwinTrack:Transformer跟踪的简单而强大的基线
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

SwinTrack: A Simple and Strong Baseline for Transformer Tracking
具体实验数据有更新,建议详见最新论文:https://arxiv.org/abs/2112.00995
代码:https://github.com/LitingLin/SwinTrack
Transformer最近在改进视觉跟踪算法方面显示出强大的潜力。然而,现有的基于Transformer的跟踪器大多使用Transformer来融合和增强CNN生成的特征。相比之下,在本文中提出了一种完全基于注意力的Transformer跟踪算法,Swin-Transformer Tracker(SwinTrack)。
SwinTrack使用Transformer进行特征提取和特征融合,允许目标对象和搜索区域之间的完全交互以进行跟踪。为了进一步提高性能,综合研究了特征融合、位置编码和训练损失的不同策略。所有这些使SwinTrack成为一个简单而强大的Baseline。
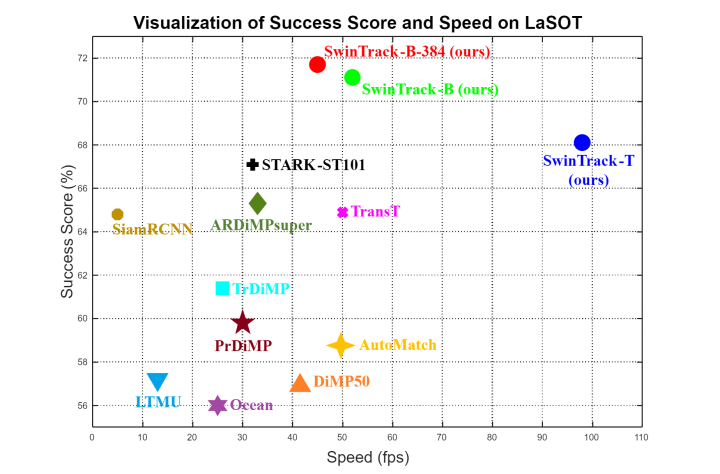
在实验中,SwinTrack在LaSOT上以0.717的SUC创造了新的纪录,比STARK高出4.6,同时仍然以45FPS的速度运行。此外,在其他具有挑战性的LaSOText、TrackingNet和GOT-10k上,拥有0.483的SUC、0.832C的SUC和0.694的AO,实现了最先进的性能。
![]()
1简介
最近,Transformer在视觉任务方面取得了重大进展。将Transformer架构引入视觉问题的尝试大致可以分为两种类型:
-
将Transformer结构视为CNN的强大补充,采用混合架构,将注意力机制与卷积网络相结合,试图利用两者的优势;
-
致力于探索一个完全的注意力模型,相信Transformer将在不久的将来打败CNN结构,注意力机制将成为下一代的基本构建模块。
一些混合架构在各种任务方面已经迅速达到了最先进的水平,这表明了Transformer的巨大潜力。相比之下,完全注意力模型在第一次测试时就不那么顺利了。Vision Transformer(ViT,第一个引入到视觉任务的完全注意力模型)和它的许多后继者在性能方面不如CNN,直到Swin-Transformer的出现。
Swin-Transformer采用了基于窗口的分层结构来解决Transformer架构中的两个主要挑战:高分辨率图像的尺度问题和高计算复杂度问题。与使用固定大小的特性图的ViT家族不同,Swin-Transformer通过逐渐将相邻patch从小到大合并来构建特性图。利用层次特征图,可以利用传统的多尺度预测来克服缩放问题。此外,Swin-Transformer引入了一个不重叠的窗口分区操作。Self-Attention计算仅限于窗口内。从而大大降低了计算复杂度。此外,分区窗口定期移动以桥接前一层中的窗口。
Transformer的优势被广泛承认主要有两个因素:
-
Transformer是一个序列到序列的模型,这使得它更容易组合多模态数据,从而在网络架构设计中提供更大的灵活性; -
从注意力机制出发的远程建模能力,释放了传统的基于CNN或基于RNN模型的局限性。
视觉目标跟踪是一个具有悠久历史的具有挑战性的研究课题。许多问题仍然没有得到很好的解决,包括被遮挡或失去视觉后的重新定位,相似物体之间的区别等等。Transformer tracking和LSTT是视觉物体跟踪任务中最先进的跟踪器。如前所述,它们都使用混合架构,使用ResNet作为Backbone,Transformer作为编码器和解码器网络。作者通过充分利用全注意力模型和Swin-Transformer Backbone可以显著提高跟踪器的性能。
通过对注意力机制本质的洞察和一系列彻底的实验,作者设计了一个强大而高效的全注意力跟踪器——SwinTrack。在具有挑战性的长期数据集LaSOT上,SwinTrack将SOTA跟踪器提升了4.6%,而FPS仍然保持在45。我们还提供了一个更轻版本的SwinTrack,它提供了97FPS的SOTA性能。

SwinTrack的主要设计包括:
-
Swin-Transformer作为Backbone; -
针对跟踪器的不同部分,选择合适的候选网络结构; -
引入松散位置编码,为基于连接的特征融合提供精确的位置编码; -
在分类预测分支中引入IoU-Aware Classification Score,得到更准确的bounding box预测。
2Swin Transformer Tracking
2.1 概览
如2所示,SwinTrack是基于Siamese网络架构。
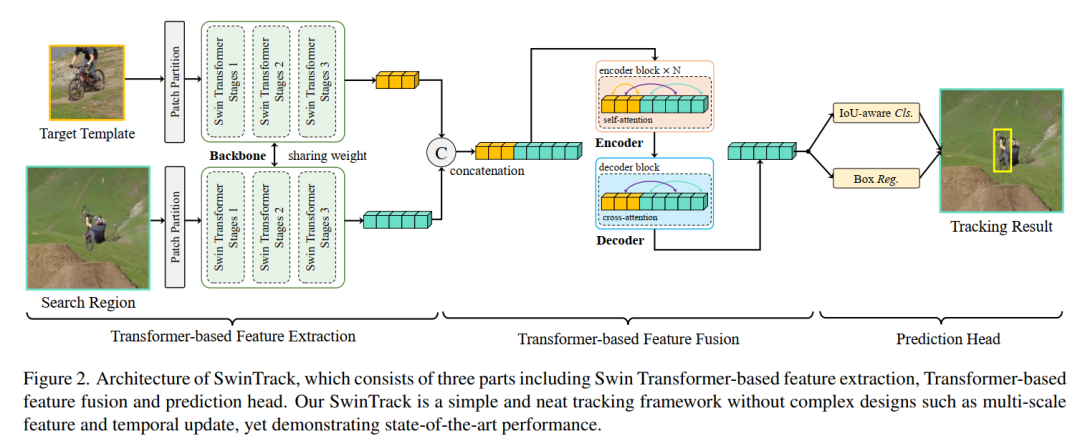
SwinTrack由4个主要组成部分组成:
-
Swin-Transformer Backbone -
注意力编解码网络 -
位置编码 -
head network 在跟踪过程中,2个Swin-Transformer Backbone分别提取模板图像patch和搜索区域图像patch的特征,并共享权重,编码器网络将模板图像和搜索图像中的特征标记进行拼接融合,并通过注意力机制逐层增强拼接的token,位置编码帮助模型区分来自不同来源和不同位置的token,解码器网络生成搜索图像的最终特征图,并将其反馈给Head网络,得到IoU-Aware分类响应图和BBox估计图。下面便分别讨论一下:
2.2 基于Transformer的特征提取
深度卷积神经网络极大地提高了跟踪器的性能。随着跟踪器的发展,backbone也经历了两次进化:AlexNet和ResNet。与ResNet相比,Swin-Transformer可以提供更紧凑的特征表示和更丰富的语义信息,以帮助后续网络更好地定位目标对象。
SwinTrack遵循经典的Siamese跟踪器的方案,它需要一对图像patch作为输入,一个是模板图像patch ,另一个是搜索区域图像补丁 (为了简化起见,分别称它们为模板图像和搜索图像)。
将来自模板图像的特征token表示为 ,来自搜索图像的特征标记表示为 , s表示backbone的stride。由于模型中没有维度投影,所以C也是整个模型的隐藏维度。
2.3 基于Transformer的特征融合
1、编码器
编码器由一系列块组成,每个块包含一个多头自注意力模块(MSA)和前馈网络(FFN)。FFN包含一个两层多层感知器(MLP), GELU激活层插入第一层后输出。层归一化(LN)总是在每个模块(MSA和FFN)之前执行。残差连接主要应用于MSA和FFN模块。
在将特征token送入编码器之前,模板图像和搜索图像中的token沿着空间维度进行拼接,以生成联合表示U。对于每个Block,MSA模块计算联合表示的自注意力,FFN对MSA生成的特征token进行细化。当token从编码器中取出时,执行解拼接操作以恢复模板图像特征token和搜索图像特征token。
整个过程可以表示为:
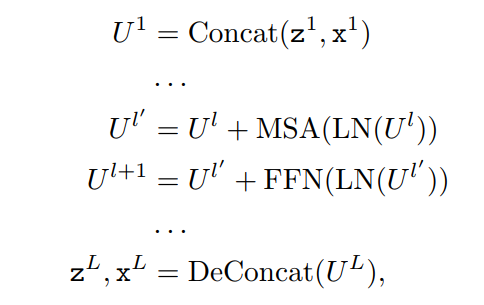
其中l表示第l层,L表示块数。
1、Why concatenated attention?
为了简化描述,作者调用上面描述的基于连接的融合方法。为了融合处理多个分支的特征,直观的做法是分别对每个分支的特征token进行Self-Attention,完成特征提取步骤,然后计算跨不同分支特征token的Cross Attention,完成特征融合步骤。作者称这种方法为基于交叉注意力的融合。
考虑到Transformer是一个序列到序列的模型,Transformer可以自然地接受多模态数据作为输入。与基于交叉注意力的融合相比,基于concat的融合,通过操作组合节省计算操作,通过权值共享减少模型参数。从这个角度来看,基于concat的融合隐式实现了Siamese网络架构。为了确保注意力机制知道当前正在处理的token属于哪个分支以及它在分支中的位置,必须仔细设计模型的位置编码解决方案。
2、Why not window-based self/cross-attention?
由于选择了Swin-Transformer的第3阶段作为输出,token的数量非常小,因此基于窗口的注意力和完全注意力之间的FLOPs非常相似。此外,一些token可能需要经过多层才能计算相关性,这对跟踪器来说太复杂了。
2、解码器
该解码器由Multi-head Cross Attention(MCA)模块和前馈网络(FFN)组成。解码器将编码器的输出特征 作为输入,通过计算 和 。解码器非常类似于编码器中的一个层,因为不需要更新最后一层中的模板图像的特征,所以删除了从模板图像token到搜索图像token的相关性。可以把解码器过程按照如下描述:
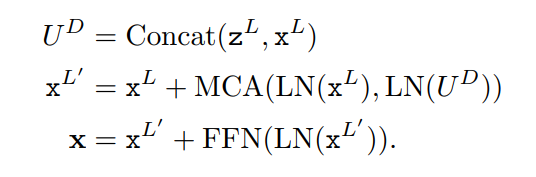
1、Why not an end-to-end architecture?
许多基于Transformer的模型具有端到端架构,这意味着该模型直接预测任务的目标,而不需要任何后处理步骤。然而,在 SwinTrack中,端到端模型仍然不适用于本文的任务。在实验中,当使用Transformer解码器直接预测目标物体的BBox时,模型收敛时间较长,跟踪性能较差。
作者所选择的解码器可以在3方面帮助提高性能:
-
通过预测响应映射,可以将候选选择任务转移到人工设计的后处理步骤; -
通过密集预测,可以向模型中输入更丰富的监督信号,从而加快训练过程; -
可以使用更多的领域知识来帮助提高跟踪性能,比如在响应图上应用一个Hanning penalty window来引入平滑运动。
2、Why not a target query-based decoder?
作者实验还发现传统的transformer解码器难以恢复二维位置信息。
2.4 位置编码
Transformer需要位置编码来标识当前处理token的位置。通过一系列的比较实验,选择TUPE中提出的联合位置编码作为SwinTrack的位置编码方案。此外,将untied positional encoding推广到任意维度,以适应跟踪器中的其他组件。
原始Transformer提出了一个绝对位置编码方法来表示位置:一个固定的或可学习的矢量 被分配给每个位置 。从基本的注意力模块开始,有:
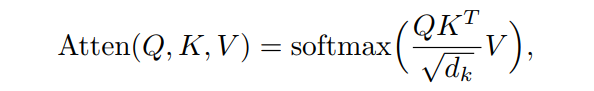
其中Q、K、V分别为query向量、key向量和value向量,它们是注意力函数的参数,dk为键的维数。在注意力模块中引入线性投影矩阵和multi-head attention,则得到multi-head variant:
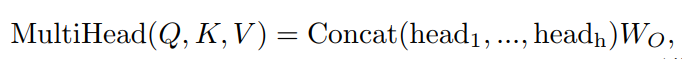
其中,
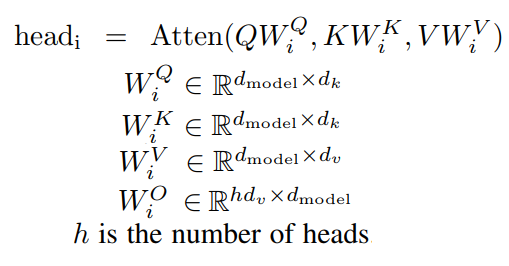
为简单起见,假设 ,并使用自注意力模块。将输入序列记为 ,其中n是序列的长度, 是输入数据中的第i个token。将输出序列表示为 。自注意力模块可以重写为:
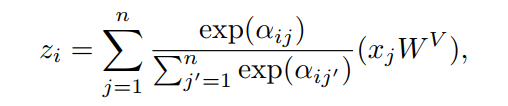
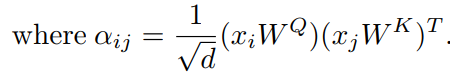
显然,自注意力模块具有排列不变性。因此,它不能“理解”输入token的顺序。
1、Untied absolute positional encoding
将一个可学习的位置编码加到自注意力模块中,得到如下方程:
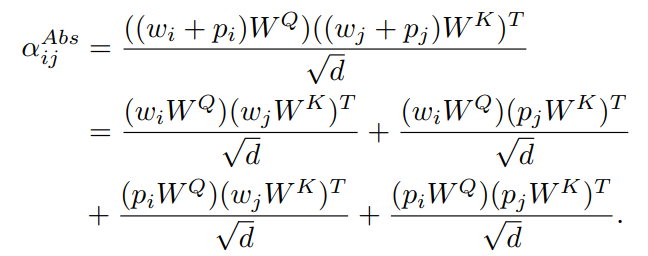
上述方程被扩展为4个项:
-
token-to-token -
token-to-position -
position-to-token -
position-to-position。
有学者讨论了方程中存在的问题,并提出了无约束绝对位置编码,它通过去除方程中的token-to-position相关项,并使用一个孤立的一对投影矩阵来解除token和position之间的相关性 和 对位置嵌入向量进行线性变换。下面是第l层使用无约束绝对位置编码得到 的新公式:
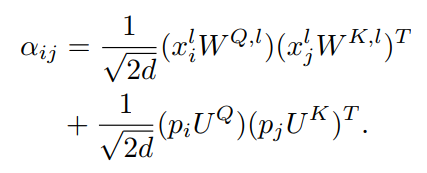
其中 和 分别是位置i和位置j的位置嵌入, 和 是位置嵌入向量的可学习投影矩阵。当扩展到多头版本时,位置嵌入 在不同的head之间是共享的,而每个head的 和 是不同的。
2、Relative positional bias
相对位置编码是绝对位置编码的必要补充。通过在方程(8)中加入一个相对位置偏差来应用相对位置编码:
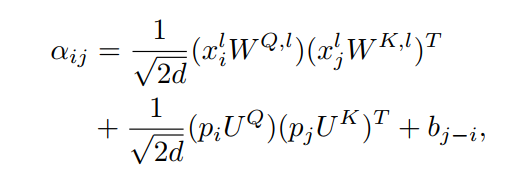
其中对于每个j−i, 是一个可学习的标量。相对位置偏差也是各层共有的。当扩展到多头版本时, 对于每个头是不同的。
3、Generalize to multiple dimensions
在使用跟踪器的编码器和解码器网络之前,需要将untied positional encoding扩展到多维版本。一种简单的方法是为每个维度分配一个位置嵌入矩阵,然后将来自不同维度的所有嵌入向量在对应的索引处相加,以表示最终的嵌入向量。加上相对位置偏差,对于n维情况,有:
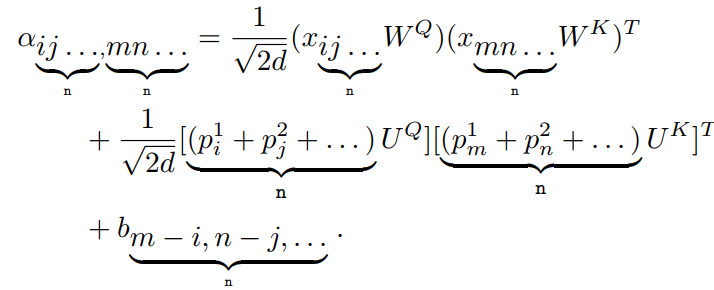
4、Generalize to concatenation-based fusion
为了实现基于concat的融合,还将untied absolute positional encoding 进行concat以匹配实际位置,相对位置偏差索引元组现在附加一对索引来反映当前所涉及的query和key的起源。
以编码器中的第l层为例:
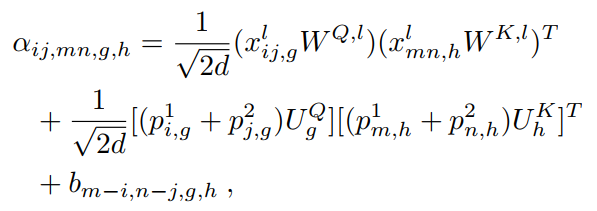
其中g和h分别是查询和key产生的索引,例如,1代表来自模板图像的token,2代表来自搜索图像的token。解码器中的形式与此类似,只是g是固定的。在实现中,解位置编码的参数分别在编码器和解码器内部共享。
2.5 Head and Training Loss
1、Head
head network分为两个分支:
-
分类分支 -
回归分支 每个分支是一个三层感知器。一个负责前景-背景分类。另一个负责BBox的回归。两者都从解码器接收到特征映射 ,分别预测分类响应映射 和包围盒回归映射 。
2、Classification loss
在分类分支,采用IoU-aware classification score为训练目标,以varifocal loss为训练损失函数。
IoU-aware设计近年来非常流行,但大多数工作都将借据预测分支作为辅助分支来辅助分类分支或边界框回归分支。为了消除不同预测分支之间的差距,有研究将分类目标由ground-truth值替换为预测BBox与ground-truth之间的IoU,即IoU-aware classification score(IACS)。IACS可以帮助模型从候选中选择更准确的边界框。与IACS一起,varifocal loss帮助IACS方法优于其他iou感知设计。varifocal loss有以下形式:
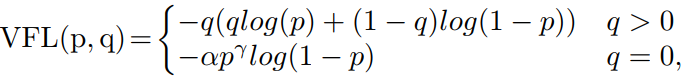
其中p为预测IACS, q为目标分数。对于正样本,即前景点,q为预测的边界框与ground-truth边界框之间的IoU。对于负样本,q = 0。则分类损失可表示为:
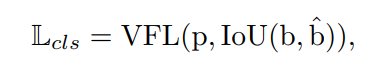
其中b为预测边界框, 为ground-truth边界框。
3、Regression loss
对于边界框回归,采用generalized IoU los。回归损失函数可表示为:
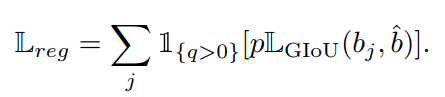
用p对GIoU损失进行加权,强调样本的高分类分数。负样本的训练信号被忽略。
3实验

3.1 与ResNet对比
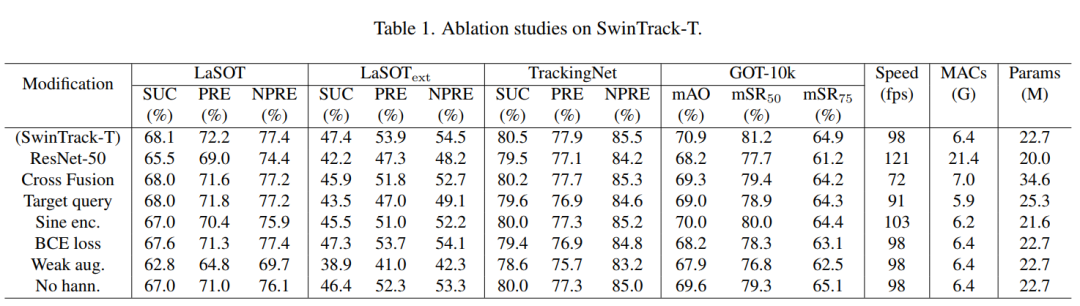
1、Feature fusion
从表1可以看出,与基于concat的融合相比,基于交叉注意力的融合不仅表现不如基于concat的融合,而且具有更多的参数。
2、解码器
受DETR启发,SwinTrack采用了Transformer解码器。通过对预训练目标query token进行交叉注意力计算,模型可以在特征中找到潜在的目标对象。理想情况下,它可以直接生成目标对象的边界框,而不需要任何后处理步骤。然而,在表1中的经验结果显示,带有Transformer解码器的跟踪器在大多数数据集中的性能很差。
3、位置编码
比较了Transformer中采用的统一位置编码和原始的since编码。如表1所示,在不同的数据集上,采用联合位置编码的SwinTrack-T比采用正弦编码的SwinTrack-T获得了更好的精度,大约提高了1%,同时仍然在98帧/秒左右运行。
4、损失函数
从表1中可以观察到,在不损失的情况下,具有varifocal loss的SwinTrack-T显著优于具有binary entropy loss(BCS)的SwinTrack-T。
5、Positional Augmentations
表1中的“Weak august”行显示的是训练阶段生成搜索图像时推导随机尺度和随机翻译的数据集评估结果。与微调超参数相比,LaSOT中评估的成功得分下降了5.3%,LaSOText中甚至下降了8.5%。
6、Post processing
通过删除后处理中的hanning penalty window,如表1所示,性能显著下降。这表明,即使有一个强大的backbone ,hanning penalty window仍然有效。
3.2 SOTA对比
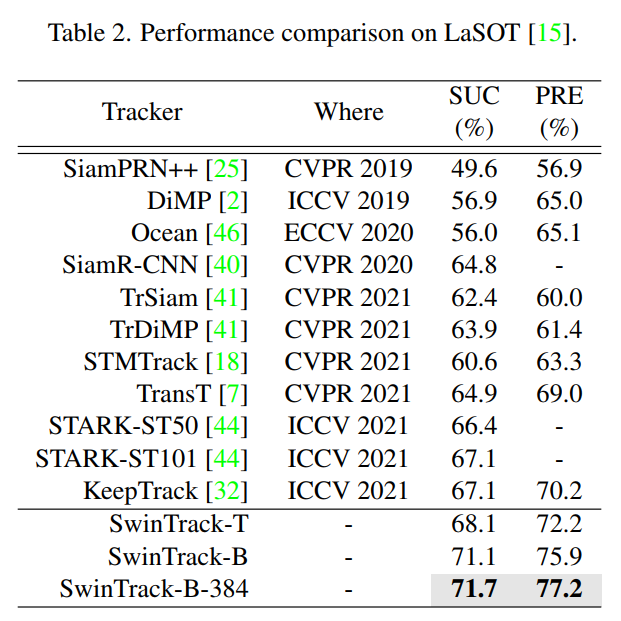
1、LaSOT
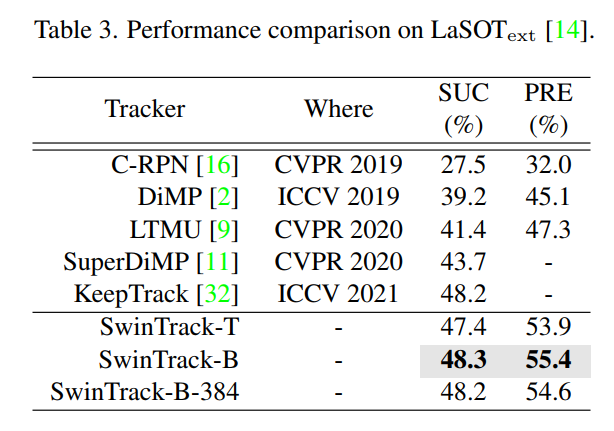
2、LaSOText
3、TrackingNet
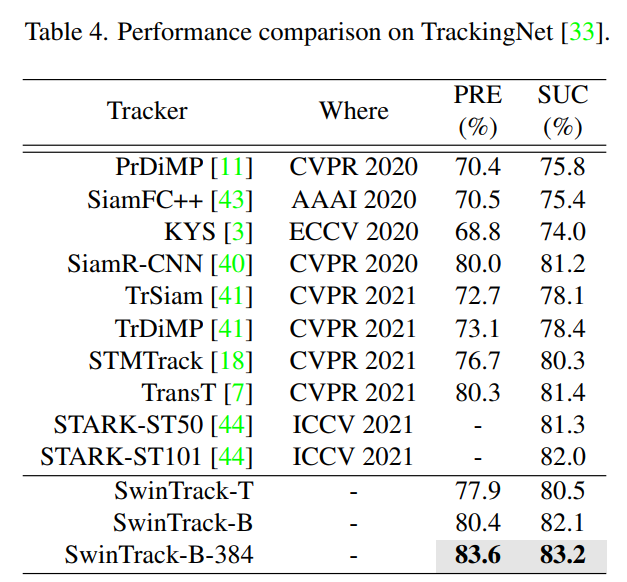
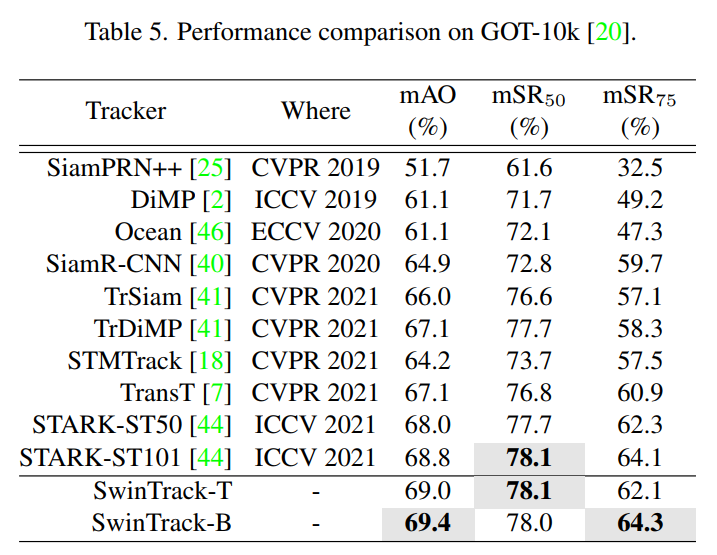
4、GOT-10k
上面论文代码下载
后台回复:SwinTrack,即可下载上述论文和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看



