【泡泡图灵智库】MVSNet:非结构化多视图立体的深度推估(ECCV)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:MVSNet:Depth Inference for Unstructed Multi-view Stereo
作者:Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan
来源:ECCV 2018
编译:尹双双
审核:李永飞
提取码:w8pp
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——MVSNet: Depth Inference for Unstructured Multi-view Stereo,该文章发表于ECCV 2018。
本文提出了一种用于多视图图像深度映射推理的端到端深度学习体系结构。在该网络中,我们首先提取深度的视觉图像特征,然后通过可微单应性变换,在参考摄像机的可见范围内构建三维代价体积。接下来,我们应用3D卷积对初始深度图进行正则化和回归,然后用参考图像对初始深度图进行细化,生成最终的输出。通过用一个基于方差的代价准则将多个特征映射到一个代价特征,我们的框架可灵活地适应任意N-view输入。MVSNet在大型室内DTU数据集上进行了实验验证,通过简单的后处理,我们的方法不仅显著优于先前的技术水平,而且运行时的速度也快了好几倍。在2018年4月18日之前,我们的方法在没有进行任何微调的情况下,在复杂的室外水池和寺庙数据集上排名第一,对MVSNet进行了评估,显示了MVSNet较强的泛化能力。
主要贡献
1.为了进行深度图的推理,本文的3D 体积是建立在camera frustum上的,而不是常规的欧式空间。
2.本文的方法将MVS重建解耦为更小的逐视图深度地图估计问题,使得大规模重建成为可能。
算法流程
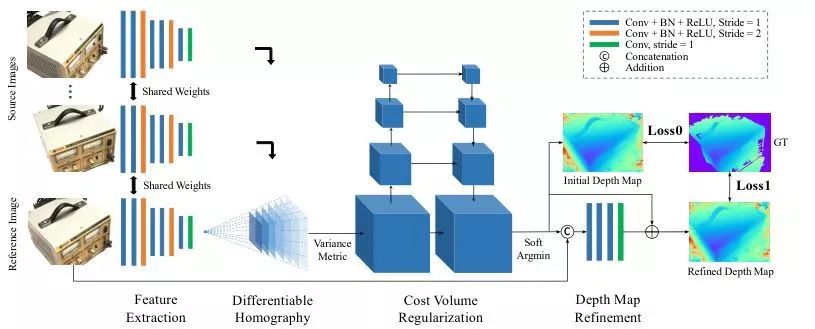
图1 MVSNet的网络设计。输入图像经过二维特征提取网络和可微单应变换生成代价体。最终的深度图输出从正则化的概率体中回归,并使用参考图像进行细化
1、影像特征
从N张输入影像中提取深度特征用于密集匹配,采用一个8层的2D CNN,第3层和第6层的步长设置为2,将特征塔划分为3个尺度。每个尺度里,用2个卷积层来提取更高级别的图像表示。除了最后一层,每个卷积层跟有一个BN层和ReLU。
与输入图像相比,二维网络的输出是N个32通道的特征图,每个维度缩小了4个。值得注意的是,虽然提取特征后图像帧的大小被缩小,但是剩下的每个像素的原始邻近信息已经被编码到32通道像素描述符中,防止了密集匹配丢失有用的上下文信息。与单纯对原始图像进行密集匹配相比,提取的特征图显著提高了重建质量。
2、代价体积
可微单应性
所有的特征图都被转换成不同的正面参考摄像机的平行平面,形成N个特征体{Vi},从变换的特征图Vi(d)到深度d处的Fi的坐标变换,由平面变换x'~Hi(d)x决定。
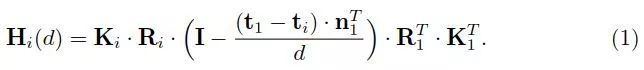
代价度量
将多个特征体{Vi}集成到一个代价体积C,为了适应任意数量的输入视图,我们提出了一种基于方差的成本度量M来度量n个视图的相似度。所有视图都应该对匹配成本做出同等的贡献,并且不优先考虑参考图像,我们选择“方差”操作,因为“均值”操作本身不提供关于特征差异的信息,而且它们的网络需要CNN前后的层来帮助推断相似性。相比之下,我们基于方差的成本度量显式地度量了多视图特性的差异。在以后的实验中,我们将证明这种显式的差分测量提高了验证的精度。
代价体积归一化
从影像特征计算的原始代价体积可能会受到噪声污染(比如因缺乏non-Lambertian表面或重叠度),需要结合平滑度约束来推断深度图。我们的正则化步骤是为了细化上述成本体积C,生成用于深度推断的概率体积P。
3、深度图
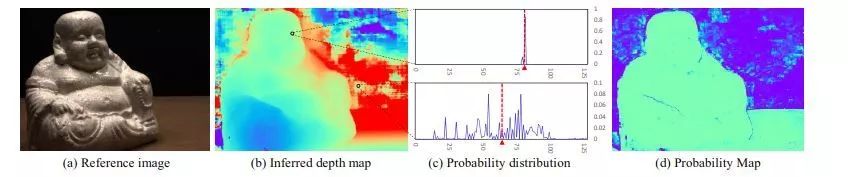
图2 推断深度图,概率分布和概率图。(a) dtu数据集[1],114 scan 的1张参考图像;(b)推断的深度图;(c)离群点像素(上)和离群点像素(下)的概率分布,其中x轴为深度假设索引,y轴为概率,红线为soft argmin结果;(d)概率图。如(c)所示,离群点分布较为分散,导致(d)的概率估计较低。
初始估计
沿着深度方向计算期望值,即所有假设的概率加权和:
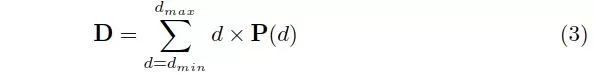
概率图
沿深度方向的概率分布也反映了深度估计的质量。,我们定义深度估计dˆ的质量为在地面真实深度小范围附近内估算的概率。由于深度假设是沿着摄像机视觉椎采样的,我们只需对四个最近的深度假设求概率和来得到估计质量。
深度图优化
我们使用参考图像作为指导来细化深度图,将初始深度图和调整后的参考图像拼接成一个4通道的输入,然后通过三个32通道的二维卷积层和一个1通道的卷积层来学习深度残差。然后将初始深度图添加回去,以生成细化的深度映射。最后一层不包含BN层和ReLU单元,学习负残差。此外,为了防止在一定深度尺度上产生偏差,我们将初始深度量值预缩放到范围[0,1],并在细化后将其转换回来。
损失
同时考虑初始深度图和优化深度图的损失。我们使用地面真实深度图与估计深度图的平均绝对差值作为训练损失。由于地面真值深度图在整幅图像中并不总是完整的,我们只考虑那些带有有效地面真值标签的像素:
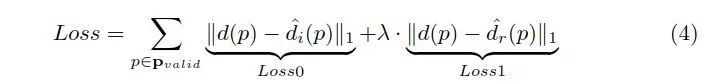
4、实现
训练
数据准备:DTU数据集包含多个MVS的大型数据集,有超过100个不同灯光条件的场景。它为地面真值点云提供了正态信息,用经过筛选的SPSR生成网格表面,然后将网格渲染到每个视点,生成训练所需的深度图。
视图选择:我们的训练中使用了一个参考图像和两个源图像(N = 3),依据稀疏点为每个影像对计算一个得分。
后处理
深度图过滤:在将结果转换为密集的点云之前,有必要过滤掉那些背景和闭塞区域的异常值。提出了两种鲁棒深度图滤波准则:光度一致性准则和几何一致性准则。
深度图融合:与其他多视图立体方法类似,用深度地图融合来集成来自不同视图的深度地图以统一点云表示。

图3 scan9,DTU数据集重建。从左上角到右下角:(a) MVSNet推断出的深度图;(b)经光度和几何滤波后的深度图;(c)由地面真值绘制的深度图;(d)参考图像;(e)最终融合点云;(f)点云真值
主要结果
1、DTU数据集基准比较
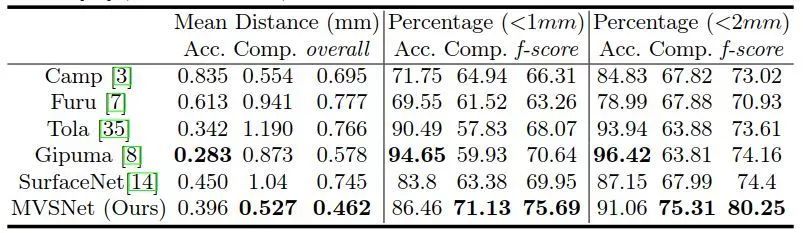

图4 DTU数据集scan9、11、75的定性结果。我们的MVSNet生成了最完整的点云,特别是在那些没有文本和反射的区域。
2、坦克和庙宇数据集上泛化性能评估
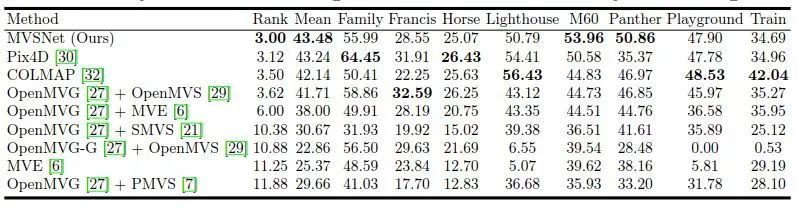

图5 坦克和寺庙数据集 intermediate set 的点云结果,证明了MVSNet在复杂户外场景下的泛化能力
3、Ablations
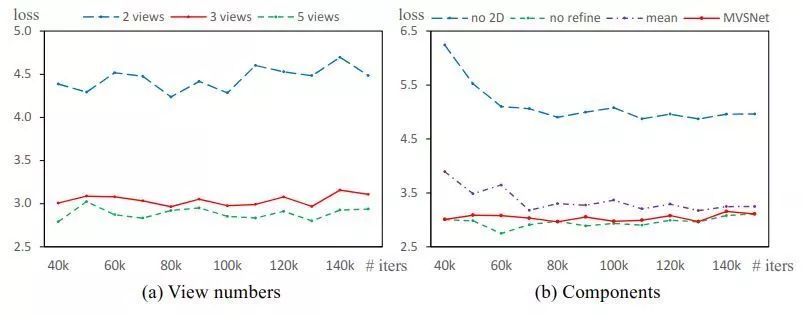
图6 Ablation的研究。(a)不同输入视图数目的验证损失。(b) 2D图像特征、代价度量和深度地图优化

Abstract
We present an end-to-end deep learning architecture for depth map inference from multi-view images. In the network, we first extract deep visual image features, and then build the 3D cost volume upon the reference camera frustum via the differentiable homography warping. Next, we apply 3D convolutions to regularize and regress the initial
depth map, which is then refined with the reference image to generate the final output. Our framework flexibly adapts arbitrary N-view inputs using a variance-based cost metric that maps multiple features into one cost feature. The proposed MVSNet is demonstrated on the large-scale indoor DTU dataset. With simple post-processing, our method not only significantly outperforms previous state-of-the-arts, but also is several times faster in runtime. We also evaluate MVSNet on the complex outdoor Tanks and Temples dataset, where our method ranks first before April 18, 2018 without any fine-tuning, showing the strong generalization ability of MVSNet.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


