自监督学习
使计算机能够观察世界,通过学习图像、语音或文本的结构来了解世界。这推动了人工智能最近的许多重大进展。
尽管世界科研人员在该领域投入大量精力,但目前自我监督学习算法从图像、语音、文本和其他模式中学习的方式存在很大差异。因此,人工智能论坛Analytics India Magazine推出2022年十大自监督学习模型,以飨读者。
论文链接:https://arxiv.org/pdf/2202.03555.pdf
开源代码:https://t.co/3x8VCwGI2x pic.twitter.com/Q9TNDg1paj
Meta AI 在一月份发布了 data2vec 算法,用于语音、图像和文本相关的计算机视觉模型。根据AI团队,该模型在NLP任务中具有很强的竞争力。
它不使用对比学习或依赖于输入示例的重建。Meta AI团队表示,data2vec的训练方式是通过提供输入数据的部分视图来进行预测模型表示。
该团队表示:「我们首先在学生模型中对掩码的训练样本编码。之后,在相同模型中,对未掩码的输入样本编码,从而构建训练目标。这个模型(教师模型)和学生模型只有参数上的不同。」
![]()
该模型根据掩码的训练样本,预测未掩码训练样本的模型表示形式。这消除了学习任务中对特定于模态的目标的依赖。
![]()
论文链接:https://arxiv.org/pdf/2201.03545.pdf
开源代码:https://t.co/nWx2KFtl7X
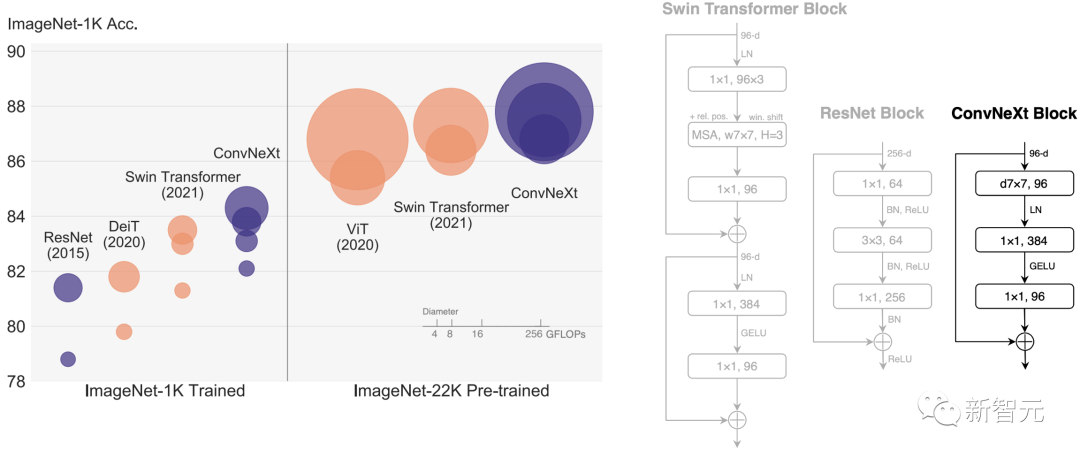
ConvNext也叫ConvNet model for the 2020s,是Meta AI团队于三月发布的一款模型。它完全基于 ConvNet的模块,因此准确、设计简单且可扩展。
![]()
论文链接:https://t.co/H7crDPHCHV
开源代码:https://t.co/oadSBT61P3
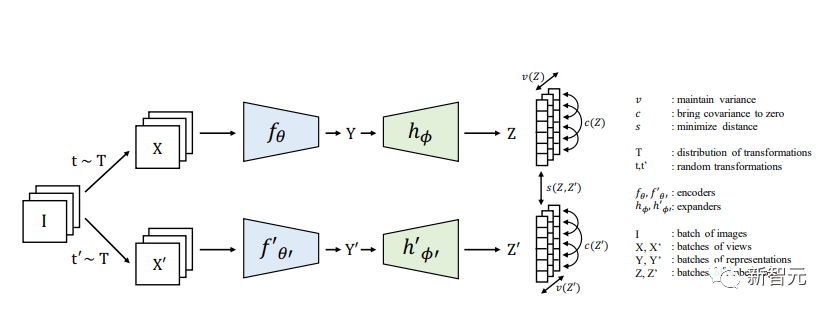
方差不变性协方差正则化(VICReg)结合了方差项和基于冗余约简的去相关机制以及协方差正则化,以避免编码器产生恒定或非信息向量的崩溃。
VICReg不需要诸如分支之间的权重共享、批量标准化、特征标准化、输出量化、停止梯度、memory banks等技术,并在几个下游任务上达到的结果与最先进水平相当。此外,通过实验可证明,方差正则化项可以稳定其他方法的训练,并促进性能的提高。
![]()
论文链接:
https://arxiv.org/abs/2203.08414
麻省理工学院的计算机科学与人工智能实验室与微软和康奈尔大学合作开发了基于能量的图形优化的自我监督转换器(STEGO),解决计算机视觉中最困难的任务之一:在没有人工监督的情况下为图像的每一个像素分配标签。
STEGO学习了「语义分割」——简单来说,就是为图像中的每个像素分配标签。
语义分割是当今计算机视觉系统的一项重要技能,因为图像可能会受到对象物体的干扰。更难的是,这些对象并不总是适合文字框。相比于植被、天空和土豆泥这样难以量化的东西,算法往往更适用于离散的「事物」,比如人和汽车。
以狗在公园里玩耍的场景为例,以前的系统可能只能识别出狗,但是通过为图像的每个像素分配一个标签,STEGO可以将图像分解为若干主要成分:狗、天空、草和它的主人。
![]()
可以「观察世界」的机器对于自动驾驶汽车和医疗诊断预测模型等各种新兴技术至关重要。由于STEGO可以在没有标签的情况下学习,它可以检测不同领域的对象,甚至是人类尚未完全理解的对象。
![]()
论文链接:https://arxiv.org/pdf/2210.04062.pdf
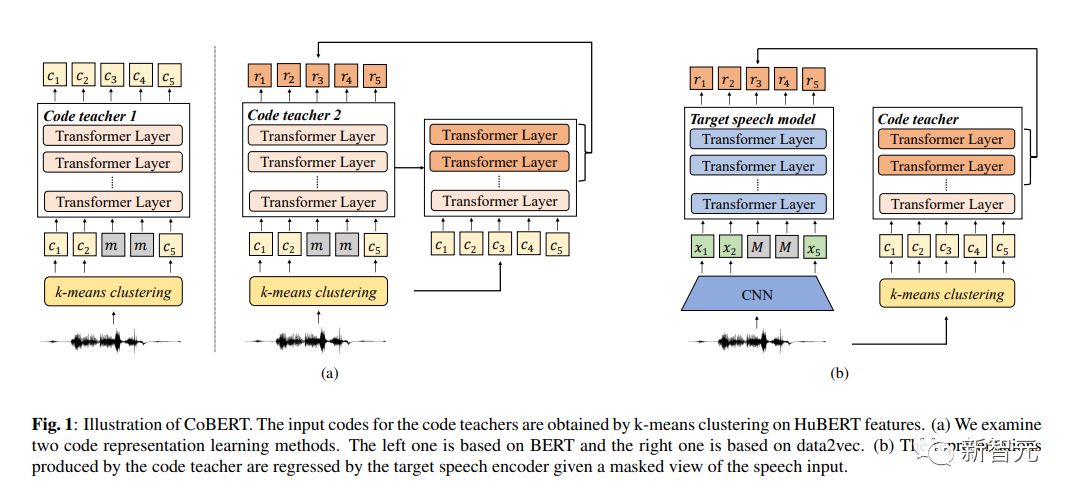
对于自我监督语音表示学习,香港中文大学(深圳)的研究人员提出了Code BERT(CoBERT)。与其他自蒸馏方法不同,他们的模型预测来自不同模态的表征。该模型将语音转换为一系列离散代码,用于表示学习。
首先,该研究团队使用HuBERT预训练代码模型在离散空间中进行训练。然后,他们将代码模型提炼成语音模型,旨在跨模态执行更好的学习。ST任务的显著改进表明,与以前的工作相比,CoBERT的表示可能携带更多的语言信息。
CoBERT在ASR任务上的表现优于目前最佳算法的性能,并在SUPERB 语音翻译(ST)任务中带来重大改进。
![]()
论文链接:https://arxiv.org/abs/2207.09158
FedX是微软和清华大学、韩国科学技术院合作推出的无监督联邦学习框架。通过局部和全局知识提炼和对比学习,该算法从离散和异构的本地数据中无偏表示学习。此外,它是一种适应性强的算法,可用作联合学习情境中各种现有自监督算法的附加模块。
![]()
论文链接:
https://arxiv.org/pdf/2206.03012.pdf
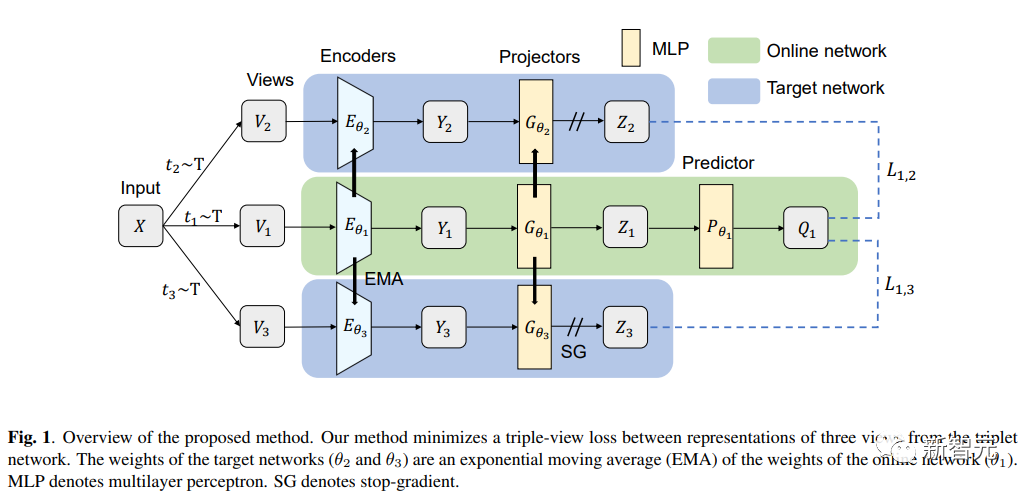
日本北海道大学提出了TriBYOL,用于小批量的自监督表示学习。该模型下,研究人员不需要大批量的计算资源来学习良好的表示。这模型为三元组网络结构,结合了三视图损失,从而在多个数据集上提高了效率并优于几种自监督算法。
![]()
论文链接:https://arxiv.org/pdf/2202.00758.pdf
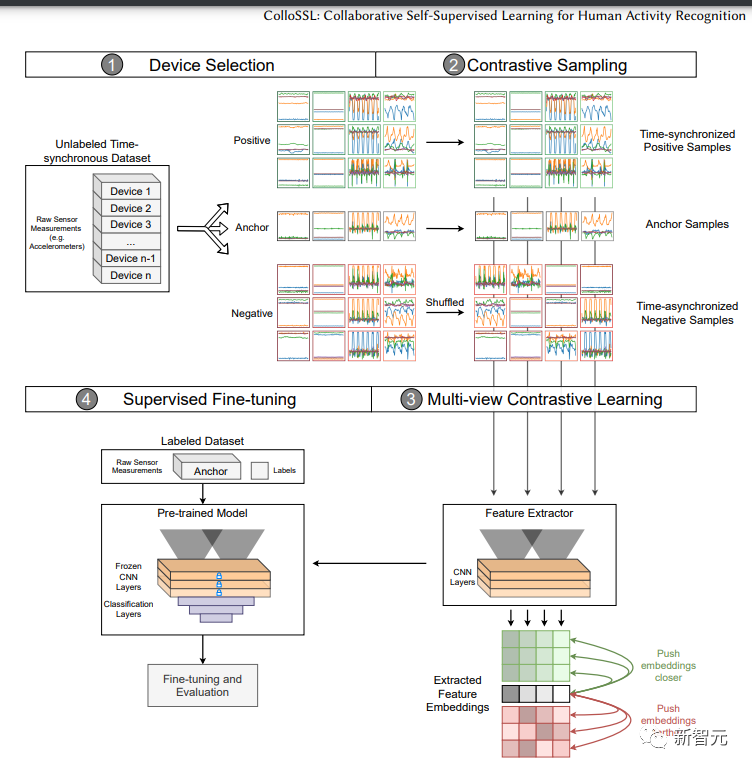
诺基亚贝尔实验室的研究人员与佐治亚理工学院和剑桥大学合作开发了ColloSSL,这是一种用于人类活动识别的协作自我监督算法。
多个设备同时捕获的未标记传感器数据集可以被视为彼此的自然转换,然后生成用于表示学习的信号。本文提出了三种方法——设备选择、对比采样和多视图对比损失。
![]()
论文链接:https://arxiv.org/pdf/2207.10023.pdf
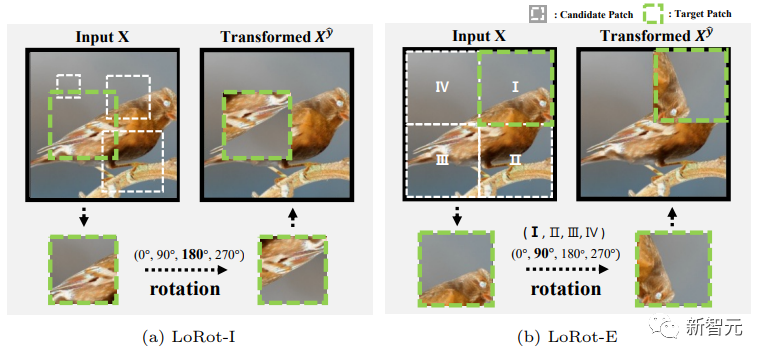
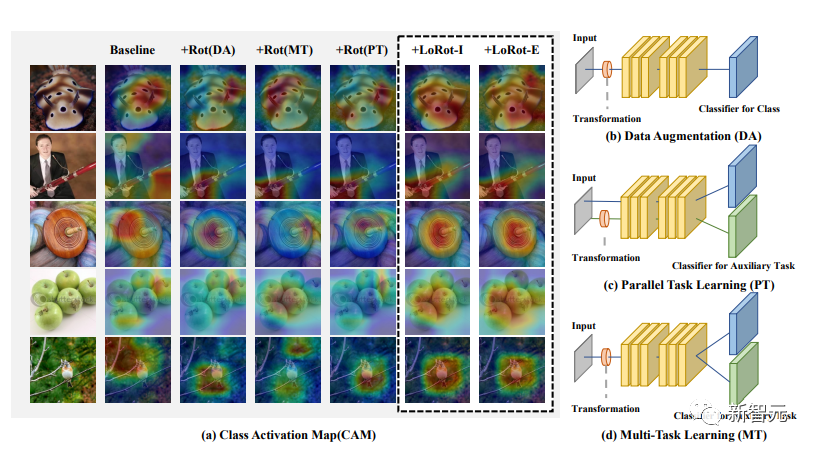
成均馆大学研究团队提出了一个简易的自监督辅助任务,该任务预测具有三个属性的可定位旋转(LoRot)以辅助监督目标。
该模型具有三大特点。第一,研究团队引导模型学习丰富的特征。第二,分布式培训在自监督转变的同时不会发生明显变化。第三,该模型轻量通用,对以前的技术具有很高的适配性。
![]()
论文链接:
https://arxiv.org/pdf/2106.10466.pdf
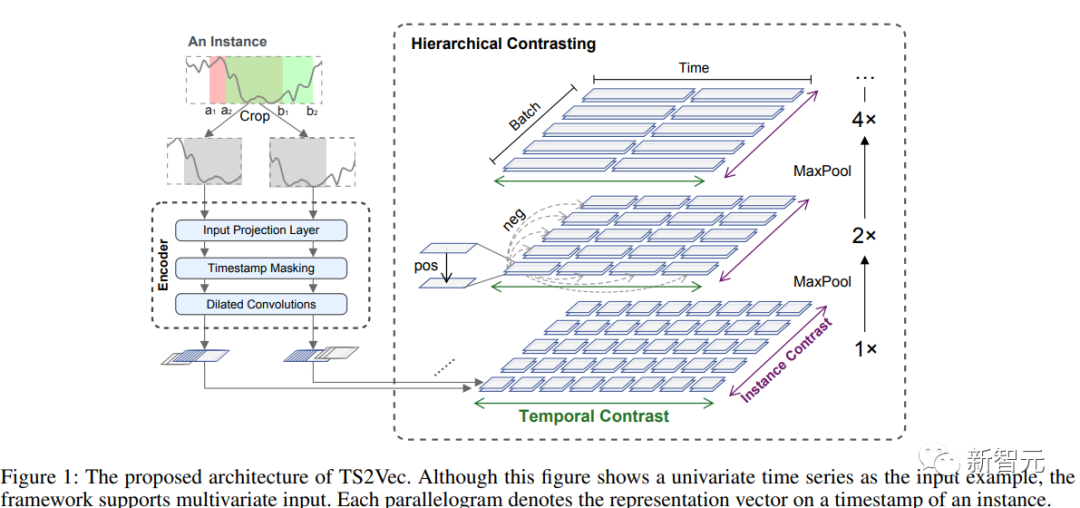
微软和北京大学提出了一个通用学习框架TS2Vec,用于在任意语义级别中时间序列的表示学习。该模型在增强的上下文视图中以分层技术执行对比学习,从而为各个时间戳提供强大的上下文表示。
结果显示,与最先进的无监督时间序列表示学习相比,TS2Vec模型在性能上有显著改进。
2022年,自监督学习和强化学习这两个领域都有巨大的创新。虽然研究人员一直在争论哪个更重要,但就像自监督学习大佬Yann LeCun说的那样:「强化学习就像蛋糕上的樱桃,监督学习是蛋糕上的糖衣,而自监督学习就是蛋糕本身。」
https://analyticsindiamag.com/top-10-self-supervised-learning-models-in-2022/
公众号后台回复“ECCV2022”获取论文资源分类汇总下载~
算法竞赛:算法offer直通车、50万总奖池!高通人工智能创新应用大赛等你来战!
技术干货:超简单正则表达式入门教程|22 款神经网络设计和可视化的工具大汇总
极视角动态:芜湖市湾沚区联手极视角打造核酸检测便民服务系统上线!|青岛市委常委、组织部部长于玉一行莅临极视角调研
![]()