年度必读:2018最具突破性人工智能论文Top 10
编辑 | 肖琴、三石 原文 | 新智元
我们总结了2018年以来最重要的10篇AI研究论文,让你对今年机器学习的进展有一个大致的了解。当然,还有很多具有突破性的论文值得一读,但我们认为这是一个很好的列表,你可以从它开始。
以下是我们推荐的2018必读Top 10论文:
Universal Language Model Fine-tuning for Text Classification
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Deep Contextualized Word Representations
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Delayed Impact of Fair Machine Learning
World Models
Taskonomy: Disentangling Task Transfer Learning
Know What You Don’t Know: Unanswerable Questions for SQuAD
Large Scale GAN Training for High Fidelity Natural Image Synthesis
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
1、文本分类的通用语言模型微调
标题:Universal Language Model Fine-tuning for Text Classification
作者:Jeremy Howard & Sebastian Ruder (2018)
https://arxiv.org/abs/1801.06146
论文摘要
迁移学习已经对计算机视觉领域产生了很大的影响,但NLP领域的现有方法仍然需要针对任务进行修改和从零开始进行训练。本文提出一种有效的迁移学习方法——通用语言模型微调(Universal Language Model Fine-tuning, ULMFiT),该方法可应用于任何NLP任务,并介绍了对语言模型进行微调的关键技术。
我们的方法在六个文本分类任务上显著优于最先进的技术,在大多数数据集上将错误率降低了18-24%。此外,仅使用100个标记示例,它的性能不比在100倍以上的数据上从零开始训练的模型的性能差。我们将开源预训练模型和代码。
概要总结
这篇论文建议使用预训练的模型来解决广泛的NLP问题。使用这种方法,你不需要从头开始训练模型,只需要对原始模型进行微调。他们的方法称为通用语言模型微调(ULMFiT),其性能优于最先进的结果,误差降低了18-24%。更重要的是,只使用100个标记示例,ULMFiT的性能与在10K标记示例上从零开始训练的模型的性能相当。
核心思想
为了解决标记数据的缺乏的困难,使NLP分类任务更容易、更省时,研究人员建议将迁移学习应用于NLP问题。因此,你不用从头开始训练模型,而是可以使用另一个经过训练的模型作为基础,然后只对原始模型进行微调来解决特定问题。
但是,为了取得成功,微调应考虑几个重要因素:
不同的层应该被微调到不同的程度,因为它们分别捕获不同类型的信息。
当学习率先线性增加后线性衰减时,使模型参数适应特定任务的特征会更有效。
同时对所有层进行微调可能会导致灾难性遗忘;因此,最好从最后一层开始逐层解冻模型。
最重要的成果
显著优于最先进的技术:误差减少了18-24%。
需要的标记数据更少:只有100个标记示例和50K未标记示例,性能与从零开始学习100倍以上的数据的性能相当。
AI社区的评价
在计算机视觉领域,经过预处理的ImageNet模型的可用性已经改变了这一领域,ULMFiT对于NLP问题也同样重要。
该方法适用于任何语言的任何NLP任务。来自世界各地的报告表明,该方法在德语、波兰语、北印度语、印度尼西亚语、汉语和马来语等多种语言方面,都取得了显著进步。
未来研究方向
改进语言模型的预处理和微调。
将这种新方法应用于新的任务和模型(如序列标记、自然语言生成、蕴涵或问题回答)。
可能的应用
ULMFiT可以更好地解决广泛的NLP问题,包括:
识别垃圾邮件、机器人、攻击性评论;
按照特定的特征对文章进行分组;
对正面和负面评论进行分类;
寻找相关文件等。
这种方法还可能有助于序列标记和自然语言生成。
2、混淆梯度
标题:Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
作者:Anish Athalye, Nicholas Carlini, David Wagner
https://arxiv.org/abs/1802.00420
论文摘要
我们发现“混淆梯度”(obfuscated gradients)作为一种梯度掩码(gradient masking),会在防御对抗样本中导致一种错误的安全感。虽然造成混淆梯度的防御似乎可以击败基于迭代优化的攻击,但我们发现依赖这种效果的防御可以被规避。我们描述了表现出这种效应的防御特征行为,对于我们发现的三种混淆梯度,我们都开发了攻击技术来克服它。在一个案例中,我们检查了发表在ICLR 2018的论文的未经认证的白盒安全防御,发现混淆梯度是常见的情况,9个防御中有7个依赖于混淆梯度。在每篇论文所考虑的原始威胁模型中,我们的新攻击成功地完全规避了6个,部分规避了1个。
概要总结
研究人员发现,针对对抗性样本的防御通常使用混淆梯度,这造成了一种虚假的安全感,实际上这种防御很容易被绕过。该研究描述了三种防御混淆梯度的方法,并展示了哪些技术可以绕过防御。这些发现可以帮助那些依赖混淆梯度来防御的组织强化他们当前的方法。
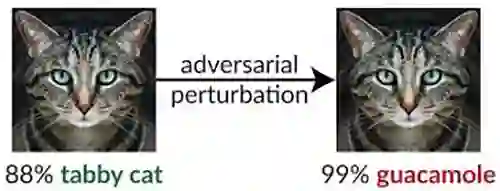
核心思想
防御混淆梯度有三种常见的方法:
破坏梯度是由防御方有意(通过不可微操作)或无意(通过数值失稳)造成的不存在或不正确的梯度;
随机梯度是由随机防御引起的;
消失/爆炸梯度是由极深的神经网络评估引起的。
有很多线索表明梯度有问题,包括:
一步攻击比迭代攻击更有效;
黑盒攻击比白盒攻击更有效;
无界攻击没有100%成功;
随机抽样发现对抗性样本;
增加扭曲约束无法增加成功。
最重要的成果
说明目前使用的大部分防御技术容易受到攻击,即:
ICLR 2018接受的论文中,9种防御技术中有7种造成了混淆梯度;
研究人员开发的新攻击技术能够成功地完全绕开6个防御,部分绕开1个防御。
AI社区的评价
这篇论文获得了ICML 2018最佳论文奖,这是最重要的机器学习会议之一。
论文强调了当前技术的优势和劣势。
未来研究方向
在仔细且全面的评估下构建防御,这样它们不仅可以防御现有的攻击,而且还可以防御未来可能发生的攻击。
可能的应用
通过使用研究论文中提供的指导,组织可以识别他们的防御是否依赖于混淆梯度,并在必要时改用更强大的方法。
3、ELMo:最好用的词向量
标题:Deep contextualized word representations
作者:Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer
https://arxiv.org/abs/1802.05365
论文摘要
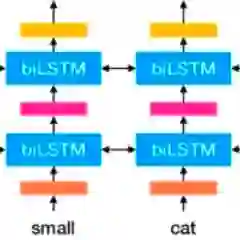
我们提出一种新的深层语境化的词表示形式,它既模拟了词使用的复杂特征(如语法和语义),也模拟了这些用法在不同语言语境中的变化(即,一词多义)。我们的词向量是一个深度双向语言模型(biLM)内部状态的学习函数,该模型是在一个大型文本语料库上预训练的。我们证明,这些表示可以很容易地添加到现有的模型中,并在六个具有挑战性的NLP问题(包括问题回答、文字蕴涵和情感分析)中显著地提升了技术的最先进水平。我们还提供了一项分析,表明暴露预训练网络的深层内部结构是至关重要的,它允许下游模型混合不同类型的半监督信号。
概要总结
艾伦人工智能研究所的团队提出一种新型的深层语境化单词表示——语言模型嵌入(Embeddings from Language Models, ELMo)。在ELMo增强的模型中,每个单词都是基于它所使用的整个上下文向量化的。在现有的NLP系统中加入ELMo可以减少6-20%的相对误差,显著减少训练模型所需的时间,以及显著减少达到基线性能所需的训练数据量。
核心思想
以深度双向语言模型(biLM)的内部状态加权和的形式生成词嵌入,该模型在大型文本语料库上预训练。
要包含来自所有biLM层的表示,因为不同的层代表不同类型的信息。
将ELMo表示建立在字符的基础上,以便网络可以使用形态学线索“理解”训练中未见的词汇表外的token。
最重要的成果
将ELMo添加到模型中可以得到state-of-the-art的结果,在问题回答、文字蕴涵、语义角色标记、相关引用解析、命名实体提取和情绪分析等NLP任务中,相对误差降低了6 - 20%。
使用ELMo增强模型可以显著减少达到最先进性能所需的更新次数。因此,使用ELMo的语义角色标记(SRL)模型只需要10 epochs就可以超过486 epochs训练后达到的基线最大值。
将ELMo引入模型还可以显著减少实现相同性能水平所需的训练数据量。例如,对于SRL任务,ELMo增强模型只需要训练集的1%就可以实现与基线模型相同的性能,而基线模型需要10%的训练数据。
AI社区的评价
这篇论文在全球最具影响力的NLP会议之一——NAACL上被评为Outstanding paper。
论文提出的ELMo方法被认为是2018年NLP领域最大的突破之一,也是NLP未来几年的重要成果。
未来研究方向
通过将ELMos与上下文无关的词嵌入连接起来,将这种方法合并到特定的任务中。
将ELMos与输出连接。
可能的应用
ELMo显著改善了现有NLP系统的性能,从而增强:
聊天机器人的性能,使其能够更好地理解人类和回答问题;
对客户的正面和负面评价进行分类;
查找相关信息和文件等。
4、序列建模:时间卷积网络取代RNN
标题:An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
作者:Shaojie Bai, J. Zico Kolter, Vladlen Koltun
https://arxiv.org/abs/1803.01271
论文摘要
对于大多数深度学习实践者来说,序列建模与循环网络是同义词。然而,最近的研究结果表明,卷积架构在语音合成和机器翻译等任务上的表现优于循环网络。给定一个新的序列建模任务或数据集,应该使用哪种架构?我们对序列建模的一般卷积和循环架构进行了系统的评价。我们在广泛的标准任务中评估这些模型。我们的结果表明,一个简单的卷积架构在不同的任务和数据集上的表现优于LSTM等典型的循环网络。我们的结论是,需要重新考虑序列建模和循环网络之间的共同关联,卷积网络应该被视为序列建模任务的一个自然起点。我们提供了相关代码:http://github.com/locuslab/TCN
概要总结
本文的作者质疑了一个常见假设,即循环架构应该是序列建模任务的默认起点。他们的结果表明,时间卷积网络(TCNs)在多个序列建模任务中明显优于长短期记忆网络(LSTMs)和门控循环单元网络(GRUs)等典型的循环架构。
核心思想
时间卷积网络(TCN)是基于最近提出的最佳实践(如扩张卷积和残差连接)设计的,它在一系列复杂的序列建模任务中表现得明显优于通用的循环架构。
TCN表现出比循环架构更长的记忆,因此更适合需要较长的历史记录的任务。
最重要的成果
在序列建模任务上提供了卷积架构和循环架构的广泛、系统的比较。
设计了一个卷积架构,它可以作为序列建模任务的一个方便且强大的起点。
AI社区的评价
在使用RNN之前,一定要先尝试CNN。你会惊讶于你能走多远。——特斯拉人工智能主管Andrej Karpathy。
未来研究方向
为了提高TCN在不同序列建模任务中的性能,需要进一步精化架构和算法。
可能的应用
TCN的提出可以提高依赖于循环架构的AI系统的序列建模能力,包括:
机器翻译;
语音识别;
音乐和语音产生。
5、探索机器学习的公平性
标题:Delayed Impact of Fair Machine Learning
By Lydia T. Liu, Sarah Dean, Esther Rolf, Max Simchowitz, Moritz Hardt (2018)
https://arxiv.org/abs/1803.04383
论文摘要
机器学习中的公平性主要是在静态的分类设置进行研究,而不考虑决策如何随时间改变基础样本总体。传统观点认为,公平性标准能够促进它们所保护的群体的长期利益。
我们研究了静态公平标准与幸福感的时间指标是如何相互作用的,如长期改善、停滞和利益变量下降。我们证明,即使在单步反馈模型中,一般的公平标准也不会随着时间的推移而促进改善,并且不受约束的目标不仅不会促进改善,甚至可能造成损害。我们描述了三个标准的延迟影响,对比了这些标准表现出不同行为的机制。此外,我们还发现一种自然形式的测量误差扩大了公平标准发挥有利作用的机制。
我们的结果突出了测量和时间建模在公平标准评估中的重要性,提出了一系列新的挑战和权衡取舍。
概要总结
当使用基于分数的机器学习算法来决定谁可以获得机会(例如贷款、奖学金、工作),谁得不到机会时,目标是确保不同人口群体被公平对待。伯克利人工智能研究实验室的研究人员表明,由于某些延迟的结果,使用共同的公平标准实际上可能会损害代表性不足或处境不利的群体。因此,他们鼓励在设计一个“公平”的机器学习系统时考虑长期结果。
核心思想
考虑实施公平标准的延迟结果显示,这些标准可能对他们旨在保护的群体的长期利益有不利影响。由于公平标准可能会对弱势群体造成主动的伤害,解决的办法可以是使用结果最大化的决策规则,或者一个结果模型。
最重要的成果
表明了人口均等、机会均等等公平标准可以为弱势群体带来任何可能的结果,包括改善、停滞或恶化,而遵循最优无约束选择政策(如利润最大化),则永远不会给弱势群体带来恶化的结果(主动伤害)。
通过FICO信用评分数据的实验支持了理论预测。
考虑了硬公平约束的替代方案。
AI社区的评价
这篇论文获得了ICML 2018最佳论文奖,ICML是最重要的机器学习会议之一。
该研究表明,有时正面的歧视会适得其反。
未来研究方向
考虑超出群体平均变化影响的其他特征(如方差、个体水平结果)。
研究结果优化对建模和测量误差的鲁棒性。
可能的应用
通过从公平性标准强加的约束转向结果建模,企业可能会开发出更有利可图、也“更公平”的ML系统,用于放贷或招聘。
6、世界模型
标题:World Model
By David Ha,Jurgen Schmidhuber(2018)
https://worldmodels.github.io
论文摘要
我们探索并建立了流行的强化学习环境的生成神经网络模型。我们的world model可以以无监督的方式快速训练,用来学习环境的压缩空间和时间表示。通过使用从world model中提取的特征作为agent的输入,我们可以训练一个非常紧凑和简单的策略,可以解决所需的任务。我们甚至可以完全在智能体自身的world model所产生的“幻觉梦境(hallucinated dream)”中训练智能体,并将该策略转换回实际环境中。
概览
Ha和Schmidhuber开发了一种world model,这种模型可以在无监督的情况下快速训练,以学习环境的时空表现形式。在赛车任务中,智能体成功的在赛道上行驶,避开了VizDom实验中怪物射击的火球。这些任务对以前的方法来说太具有挑战性了。
核心思想
该解决方案由三个不同的部分组成:
变分自动编码器(VAE),负责捕获视觉信息。 它将RGB输入图像压缩成遵循高斯分布的32维隐向量。 智能体可以使用更小的环境表示,因此可以更有效地学习。
递归神经网络(RNN),负责前瞻性思维。这是一个内存组件,它试图预测可视组件捕获的下一张图片在考虑前一张图片和上一张图片时可能会是什么样子。
控制器,负责选择操作。这是一个简单的神经网络,连接VAE的输出和RNN的隐藏状态,并选择良好的行动。
最重要的成果
这是第一个已知的智能体解决流行的“赛车”强化学习环境。
该研究证明了完全在智能体模拟的潜在空间梦境世界中训练它,并且执行任务的可能性。
AI社区的评价
这篇论文在人工智能社区中得到了广泛的讨论,被认为是一篇利用神经网络在“幻觉”世界中强化学习和训练智能体的杰出作品。
未来研究方向
通过将小型RNN替换为更高容量的模型或合并外部内存模块,使智能体能够探索更复杂的世界。
使用更通用的方法进行试验,这些方法允许分层规划(hierarchical planning )。
可能的应用
在运行计算密集型游戏引擎时,现在可以在模拟环境中尽可能多地训练智能体,而不是在实际环境中浪费大量的计算资源来进行训练。
7、分解任务迁移学习
标题:Taskonomy: Disentangling Task Transfer Learning
By Amir R. Zamir,Alexander Sax,William Shen,Leonidas J. Guibas,Jitendra Malik,Silvio Savarese(2018)
https://arxiv.org/abs/1804.08328
论文摘要
视觉任务之间有关联吗?例如,表面法线可以简化对图像深度的估计吗?直觉回答了这些问题,暗示了视觉任务中存在结构。了解这种结构具有显著的价值;它是迁移学习的基本概念,提供了一种原则性的方法来识别任务之间的冗余。
我们提出了一种完全计算的可视化任务空间结构建模方法。 这是通过在潜在空间中的二十六个2D,2.5D,3D和语义任务的字典中查找(一阶和更高阶)传递学习依赖性来完成的。该产品是用于任务迁移学习的计算分类映射。我们研究这种结构的结果,例如出现的非平凡关系,并利用它们来减少对标记数据的需求。例如,我们展示了在保持性能几乎相同的情况下,解决一组10个任务所需的标记数据点的总数可以减少大约2/3(与独立训练相比)。我们提供了一组用于计算和探测这种分类结构的工具,包括一个解决程序,用户可以使用它来为他们的用例设计有效的监督策略。
概览
自现代计算机科学的早期以来,许多研究人员就断言视觉任务之间存在一个结构。现在Amir Zamir和他的团队试图找到这个结构。他们使用完全计算的方法建模,并发现不同可视化任务之间的许多有用关系,包括一些重要的任务。他们还表明,通过利用这些相互依赖性,可以实现相同的模型性能,标记数据要求大约减少2/3。
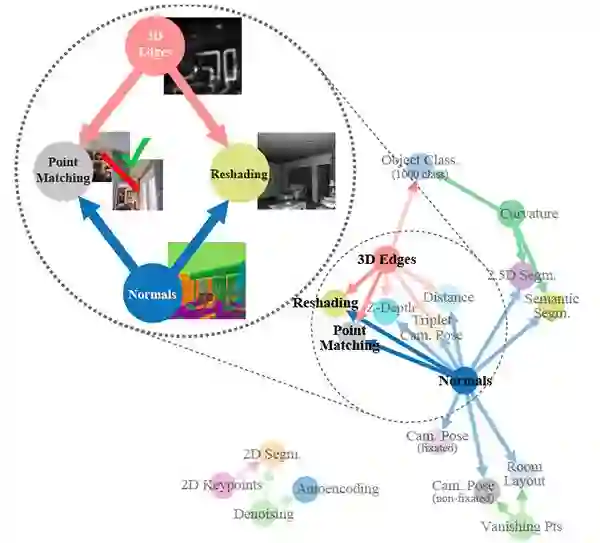
核心思想
了解不同可视化任务之间关系的模型需要更少的监督、更少的计算和更可预测的行为。
一种完整的计算方法来发现视觉任务之间的关系是可取的,因为它避免了强加的、可能是不正确的假设:先验来自于人类的直觉或分析知识,而神经网络可能在不同的原理上运作。
最重要的成果
识别26个常见视觉任务之间的关系,如目标识别、深度估计、边缘检测和姿态估计。
展示这个结构如何帮助发现对每个视觉任务最有效的迁移学习类型。
AI社区的评价
该论文在计算机视觉与模式识别重要会议CVPR 2018上获得了最佳论文奖。
结果非常重要,因为对于大多数实际任务,大规模标记数据集不可用。
未来研究方向
从一般的视觉任务完全由人类定义的模型,转向将人类定义的视觉任务视为由计算发现的潜在子任务组成的观察样本的方法。
探索将发现转化为不完全是视觉任务的可能性。
可能的应用
在本文中发现的关系可以用来构建更有效的视觉系统,这个系统将需要更少的标记数据和更低的计算成本。
8、SQuAD无法解决的问题
标题: Know What You Don't Know: Unanswerable Questions For SQuAD
By Pranav Rajpurkar,Robin Jia,Percy Liang
https://arxiv.org/abs/1806.03822
论文摘要
摘要抽取式阅读理解系统通常可以在上下文文档中找到问题的正确答案,但对于没有在上下文中陈述正确答案的问题,它们往往会做出不可靠的猜测。现有的数据集要么只关注可回答的问题,要么使用自动生成的容易识别的不可回答的问题。为了解决这些缺点,我们提供了SQuAD 2.0,这是斯坦福问答数据集(SQuAD)的最新版本。SQuAD 2.0结合了现有的SQuAD数据和超过50000个由众包工人以对抗性方式写下的无法回答的问题,使其看起来与能够回答的问题相似。为了在SQuAD 2.0上做得好,系统不仅必须尽可能回答问题,还要确定段落何时不支持答案并且不回答问题。 对于现有模型,SQuAD 2.0是一项具有挑战性的自然语言理解任务:在SQUAD 1.1上获得86%F1的强大神经系统在SQuAD 2.0上仅获得66%的F1。
概览
斯坦福大学的一个研究小组扩展了著名的斯坦福问答数据集(SQUAD),提出了超过50,000个难以回答的问题。这些问题的答案不能在支持段落(supporting paragraph)中找到,但是这些问题看起来与可回答的问题非常相似。更重要的是,支持段落包含了对这些问题的合理(但不正确)的回答。这使得新的SQuAD 2.0对于现有的最先进的模型来说极具挑战性。
核心思想
当前的自然语言理解(NLU)系统远非真正的语言理解,其根本原因之一是现有的Q&A数据集关注的问题是保证在上下文文档中存在正确答案的问题。
为了真正具有挑战性,应该提出一些无法回答的问题,以便:它们与支持段落相关;这一段包含了一个貌似合理的答案,它包含了与问题所要求的信息相同的信息,但是是不正确的。
最重要的成果
通过53,777个新的无法回答的问题扩展SQuAD,从而构建具有挑战性的大规模数据集,迫使NLU系统了解何时无法根据上下文回答问题。
这给NLU系统带来了新的挑战,因为现有的模型(66%的准确率)较低于人类的准确率(89.5%)。
这表明貌似合理的答案确实对NLU系统起到了有效的干扰作用。
AI社区的评价
该论文被计算语言学协会(ACL)评为2018年度最佳短文。
新的数据集增加了NLU领域的复杂性,并且实际上可以在这一研究领域促进性能训练。
未来研究的方向
开发“了解他们不知道的东西”的新模型,从而更好地理解自然语言。
可能的应用
在这个新的数据集上训练阅读理解模型,可以提高它们在现实场景中的性能,在这些场景中,答案通常不是直接可用的。
9、用于高保真自然图像合成的大规模GAN训练
标题:Large Scale GAN Training For High Fidelity Natural Image Synthesis
By Andrew Brock,Jeff Donahue,Karen Simonyan(2018)
https://arxiv.org/abs/1809.11096
论文摘要
尽管生成图像建模最近取得了进展,但从ImageNet等复杂数据集成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,我们在最大的规模下进行了生成对抗网络的训练,并研究了这种规模下的不稳定性。我们发现,将正交正则化应用于发生器,使其服从于一个简单的“截断技巧”,可以允许通过截断潜在空间来精细控制样本保真度和多样性之间的权衡。 我们的修改使得模型在类条件图像合成中达到了新的技术水平。 当我们在ImageNet上以128×128分辨率进行训练时,我们的模型(BigGAN)的初始得分(IS)为166.3,Frechet初始距离(FID)为9.6。
概览
DeepMind团队发现,当前的技术足以从现有数据集(如ImageNet和JFT-300M)合成高分辨率、多样化的图像。他们特别指出,生成对抗网络(GANs)可以生成看起来非常逼真的图像,如果它们在非常大的范围内进行训练,即使用比以前实验多2到4倍的参数和8倍的批处理大小。这些大规模的GAN,或BigGAN,是类条件图像合成的最新技术。

核心思想
随着批(batch)大小和参数数量的增加,GAN的性能更好。
将正交正则化应用到生成器中,使模型响应特定的技术(“截断技巧”),该技术提供了对样本保真度和多样性之间的权衡的控制。
最重要的成果
证明GAN可以从scaling中获益;
构建允许显式、细粒度地控制样本多样性和保真度之间权衡的模型;
发现大规模GAN的不稳定性;
BigGAN在ImageNet上以128×128分辨率进行训练:初始得分(IS)为166.3,之前的最佳IS为52.52;Frechet Inception Distance (FID)为9.6,之前最好的FID为18.65。
AI社区的评价
该论文正在为ICLR 2019做准备;
自从Big Hub上线BigGAN发生器之后,来自世界各地的AI研究人员正在玩BigGAN,来生成狗,手表,比基尼图像,蒙娜丽莎,海滨以及更多主题。
未来研究方向
迁移到更大的数据集以减少GAN稳定性问题;
探索减少GAN产生的奇怪样本数量的可能性。
可能的应用
取代昂贵的手工媒体创作,用于广告和电子商务的目的。
10、BERT:深度双向变换器语言理解的预训练
标题:BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
By Jacob Devlin,Ming-Wei Chang,Kenton Lee,Kristina Toutanova(2018)
https://arxiv.org/abs/1810.04805
论文摘要
我们介绍了一种新的语言表示模型,称为BERT,它代表转换器的双向编码器表示。与最近的语言表示模型不同,BERT的设计是通过在所有层中对左右上下文进行联合条件作用来预先训练深层双向表示。因此,只需要一个额外的输出层,就可以对预训练的BERT表示进行微调,从而为广泛的任务(如回答问题和语言推断)创建最先进的模型,而无需对特定于任务的体系结构进行大量修改。
BERT概念简单且功能丰富。它在11项自然语言处理任务中获得了最新的结果,包括将GLUE基准提高到80.4%,多项精度提高到86.7,以及将SQuAD v1.1答题测试F1提高到93.2,比人类表现高出2.0%。
概览
谷歌AI团队提出了一种新的最前沿的自然语言处理(NLP)模型——BERT,Bidirectional Encoder Representations from Transformers。它的设计允许模型从左右两边考虑每个单词的上下文。在概念简单的同时,BERT在11个NLP任务上获得了最新的最先进的结果,这些任务包括回答问题、命名实体识别和其他与一般语言理解相关的任务。
核心思想
通过随机屏蔽一定比例的输入tokens来训练一个深层双向模型,从而避免单词可以间接“看到自己”的循环;
此外,通过构建一个简单的二元分类任务,预测句子B是否紧跟着句子A,对句子关系模型进行预处理,从而让BERT更好地理解句子之间的关系。
训练一个非常大的模型(24个Transformer块,1024个hidden,340M参数)和大量数据(33亿字语料库)。
最重要的成果
为11项NLP任务提供最先进的技术,包括:GLUE分数80.4%,比之前的最佳成绩有7.6%的提升;在SQuAD 1.1上达到93.2%的准确率,超过人类水平2%。
建议一个预训练的模型,它不需要任何实质性的架构修改就可以应用于特定的NLP任务。
AI社区的评价
BERT模型标志着NLP的新时代;
两个无人监督的任务在一起为许多NLP任务提供了很好的结果;
语言模型的预训练成为一种新标准。
未来研究方向
在更广泛的任务中测试该方法;
可能的应用
BERT可以帮助企业解决一系列的NLP问题,包括:为聊天机器人提供更好的客户体验;客户评论分析;查阅相关资料等等。
推荐阅读