本教程涵盖了自监督视觉表示学习领域的流行方法和最新进展。我们将介绍掩码自动编码器和对比学习等主题。我们将展示这些框架如何成功地从2D静态图像和动态视频信息中学习。最后,我们还将从机器学习的角度讨论自监督学习。总的来说,我们将展示不同自监督学习技术之间的联系和区别,并提供关于社区中流行方法的见解。
https://feichtenhofer.github.io/eccv2022-ssl-tutorial/
组织人员:

目录内容:
Welcome and agenda - Xinlei Chen and Christoph Feichtenhofer, Meta AI * Opening remarks - Yann LeCun, Meta AI and NYU * Masked autoencoders as scalable vision learners - Xinlei Chen, Meta AI * Self-supervised learning from masked video and audio - Christoph Feichtenhofer, Meta AI * The virtuous cycle of object discovery and representation learning - Olivier J. Hénaff, DeepMind * Contrastive learning of visual representations - Ting Chen, Google
Masked autoencoders as scalable vision learners


论文链接:https://arxiv.org/abs/2111.06377
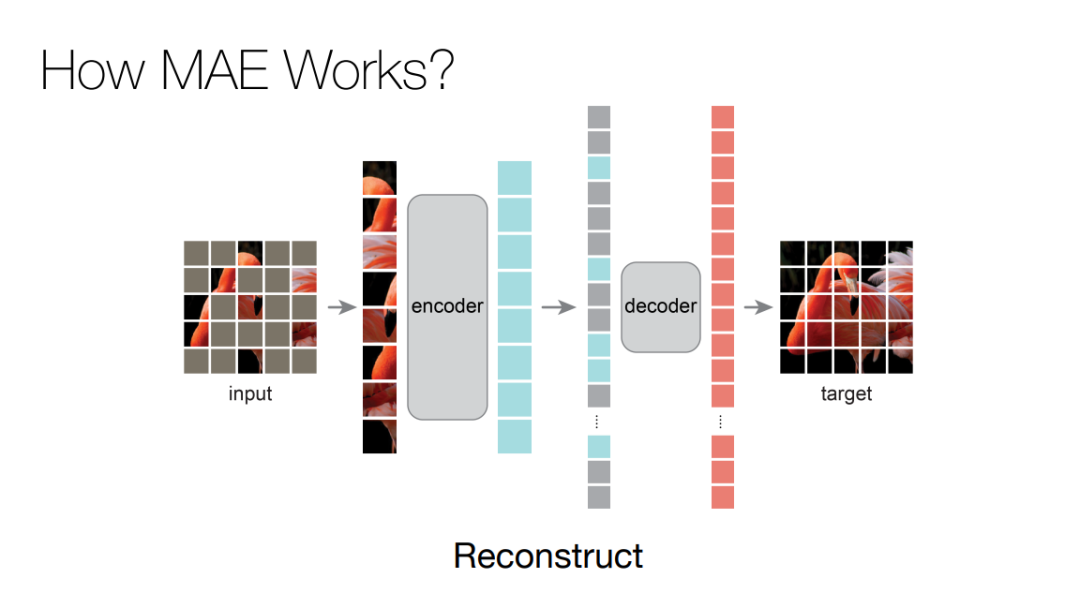
这篇论文展示了一种被称为掩蔽自编码器(masked autoencoders,MAE)的新方法,可以用作计算机视觉的可扩展自监督学习器。MAE 基于两个核心理念:研究人员开发了一个非对称编码器 - 解码器架构,其中一个编码器只对可见的 patch 子集进行操作(没有掩蔽 token),另一个简单解码器可以从潜在表征和掩蔽 token 重建原始图像。
研究人员进一步发现,掩蔽大部分输入图像(例如 75%)会产生重要且有意义的自监督任务。结合这两种设计,我们就能高效地训练大型模型:提升训练速度至 3 倍或更多,并提高准确性。 作者认为,这种可扩展方法允许学习泛化良好的高容量模型:例如在仅使用 ImageNet-1K 数据的方法中,vanilla ViT-Huge 模型实现了最佳准确率 (87.8%)。在下游任务中的传输性能优于有监督的预训练,并显示出可观的扩展能力。

Self-supervised learning from masked video and audio