突破自监督ResNet的极限!DeepMind新作!在 ImageNet 上自监督超越有监督学习?
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:好困 袁榭
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:好困 袁榭
【导读】近日,DeepMind又整了个新活:RELIC第二代!首次用自监督学习实现了对有监督学习的超越。莫非,今后真的不用标注数据了?

方法
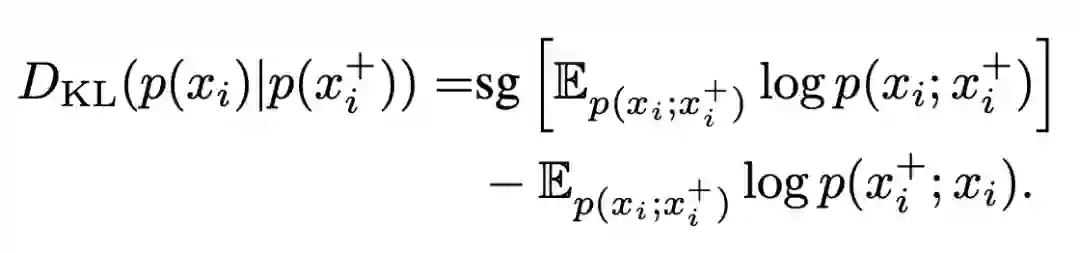
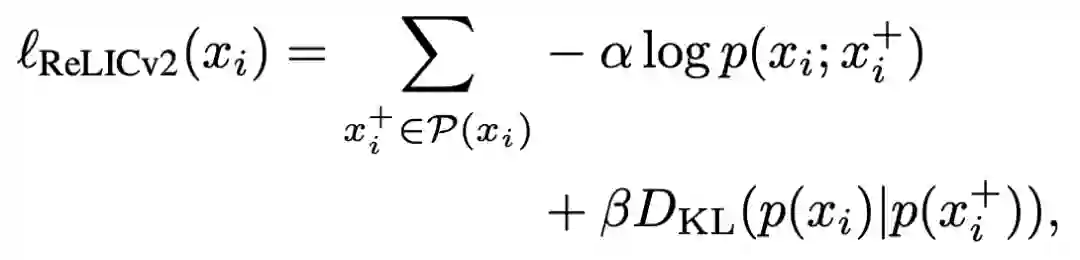
for x in batch: # load a batch of B samples # Apply saliency mask and remove background x_m = remove_background(x) for i in range(num_large_crops): # Select either original or background-removed # Image with probability p_m x = Bernoulli(p_m) ? x_m : x # Do large random crop and augment xl_i = aug(crop_l(x)) ol_i = f_o(xl_i) tl_i = g_t(xl_i)
for i in range(num_small_crops): # Do small random crop and augment xs_i = aug(crop_s(x)) # Small crops only go through the online network os_i = f_o(xs_i) loss = 0 # Compute loss between all pairs of large crops for i in range(num_large_crops): for j in range(num_large_crops): loss += loss_relicv2(ol_i, tl_j, n_e) # Compute loss between small crops and large crops for i in range(num_small_crops): for j in range(num_large_crops): loss += loss_relicv2(os_i, tl_j, n_e) scale = (num_large_crops + num_small_crops) * num_large_crops loss /= scale # Compute grads, update online and target networks loss.backward() update(f_o) g_t = gamma * g_t + (1 - gamma) * f_o
RELICv2的伪代码
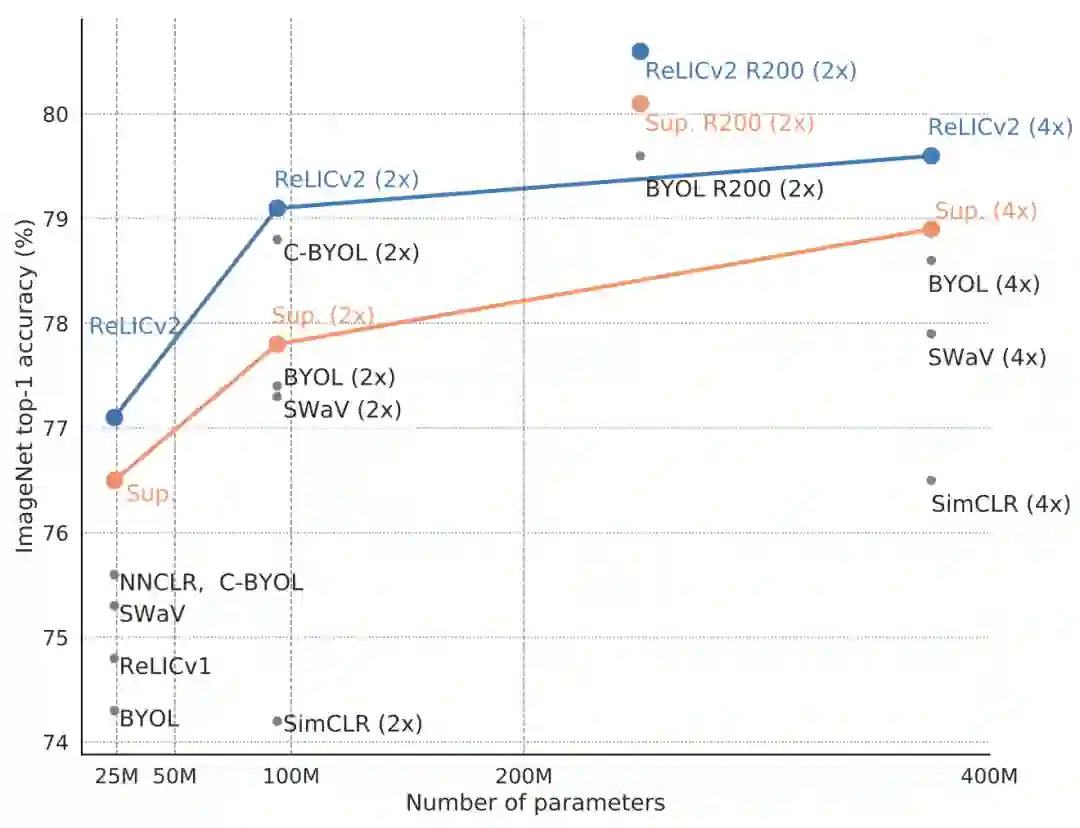
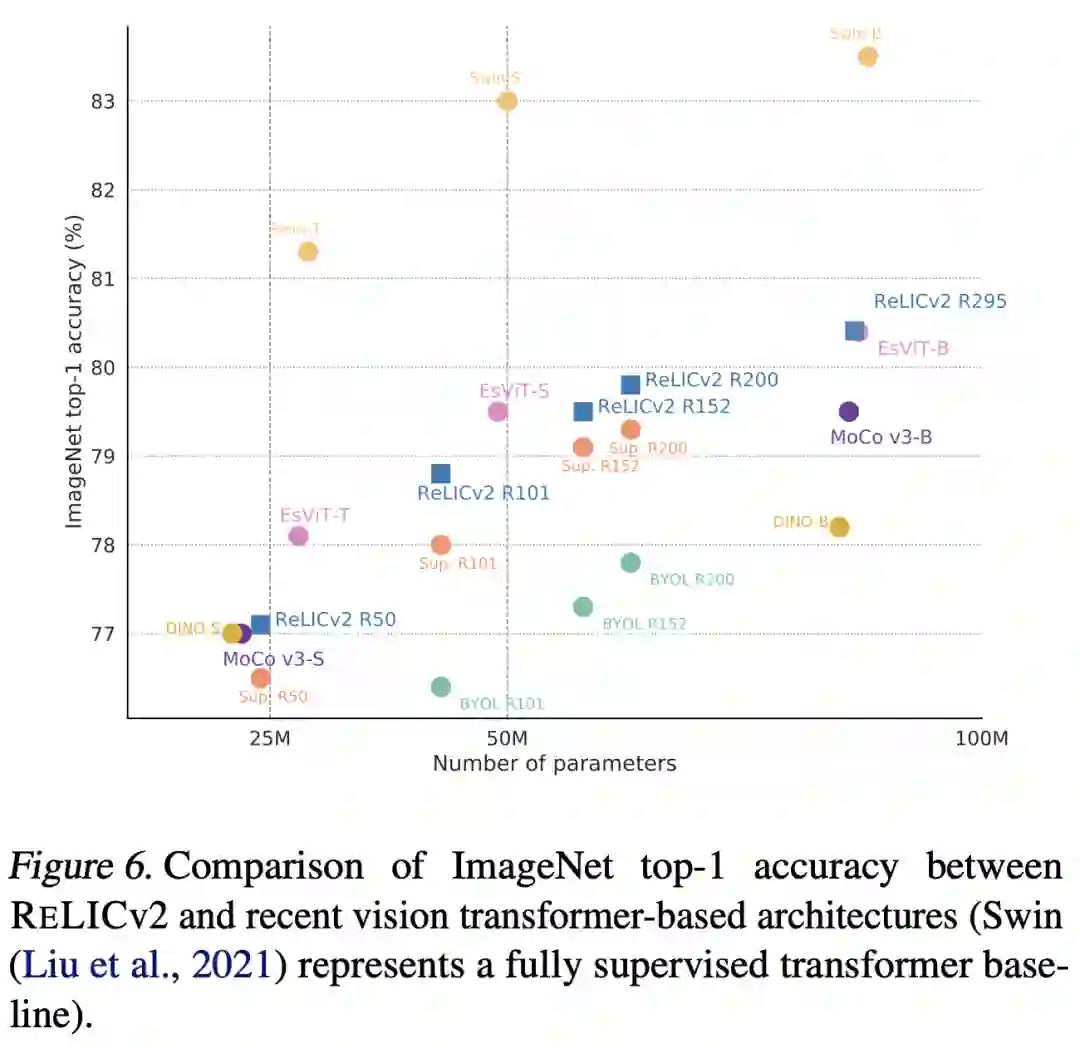
结果
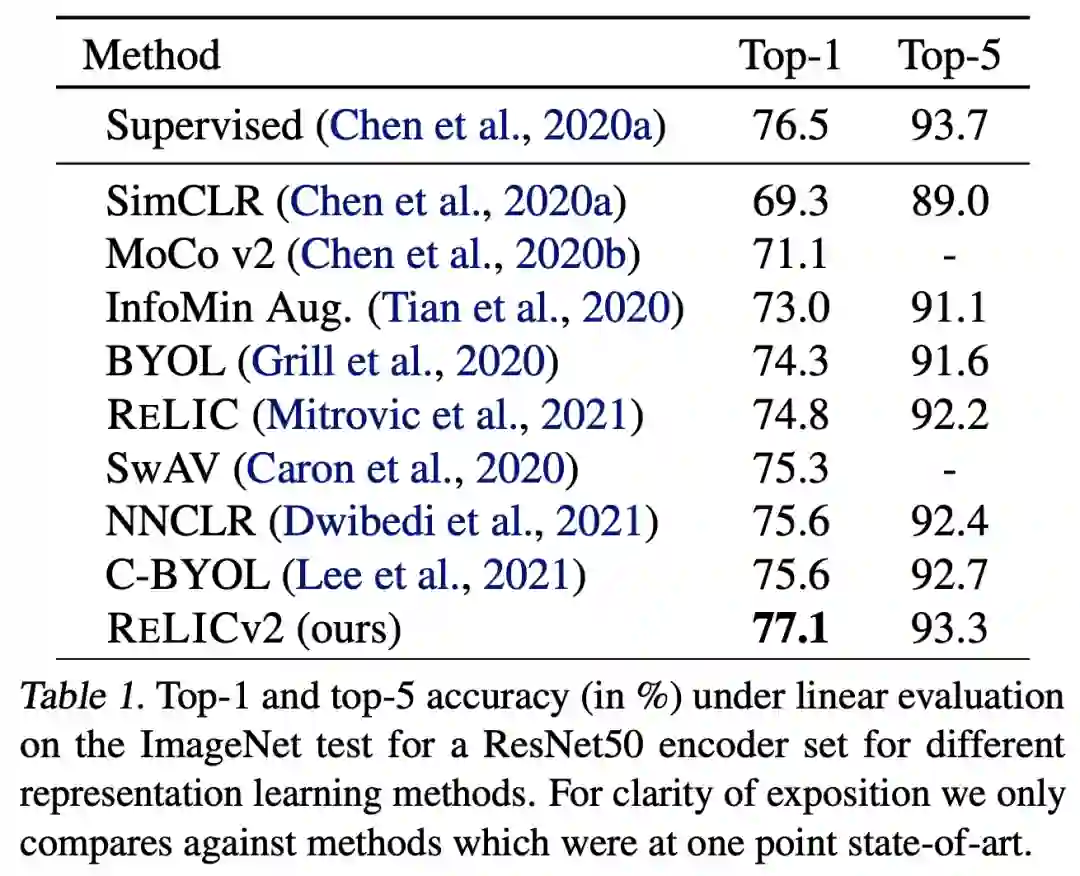
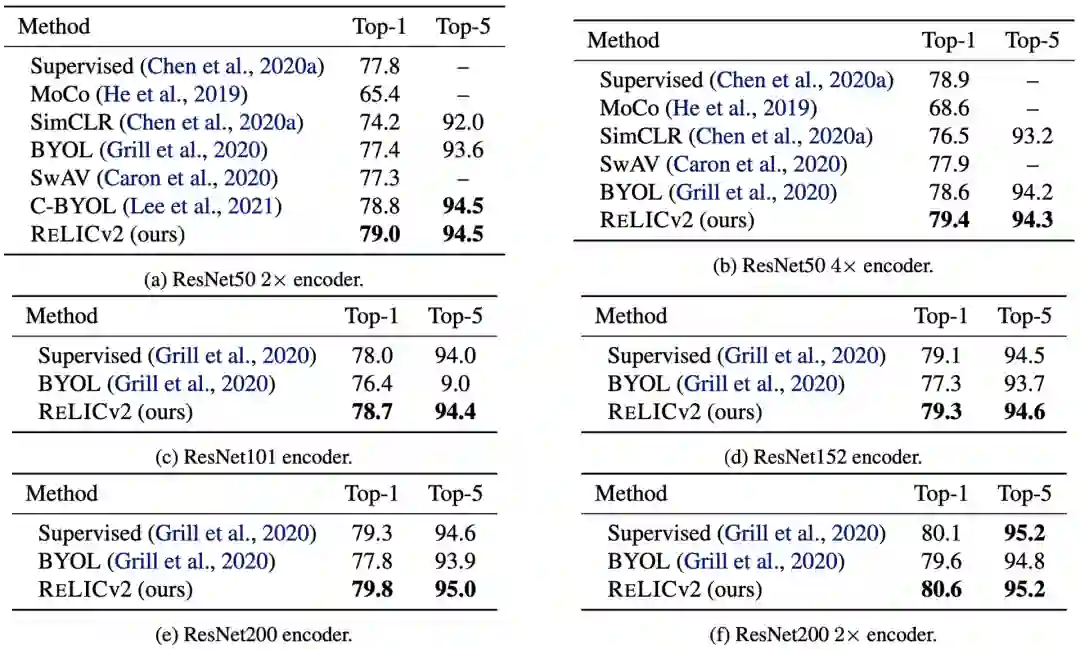
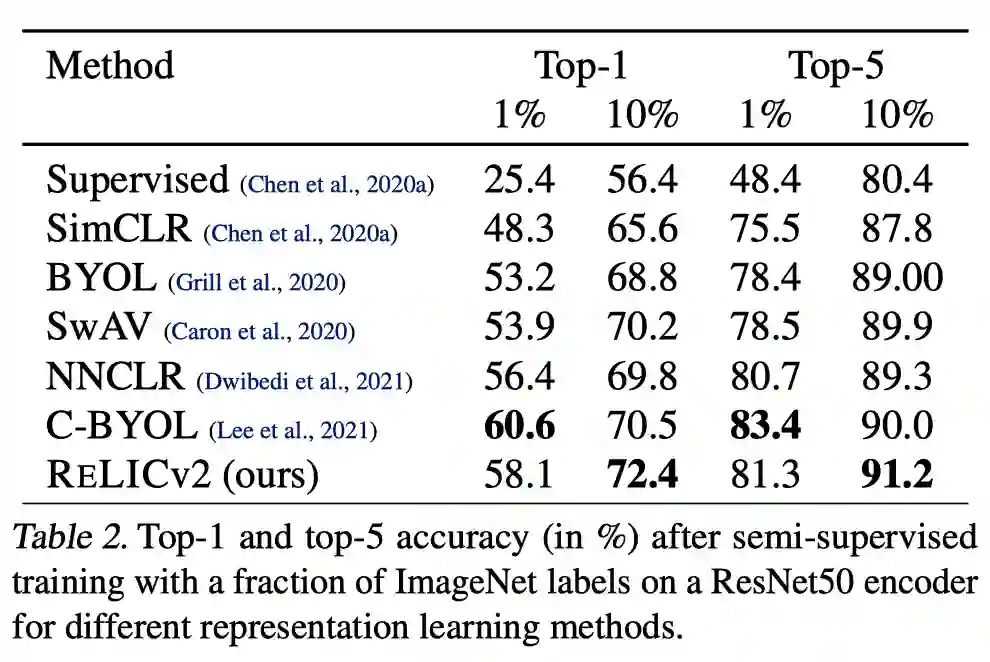
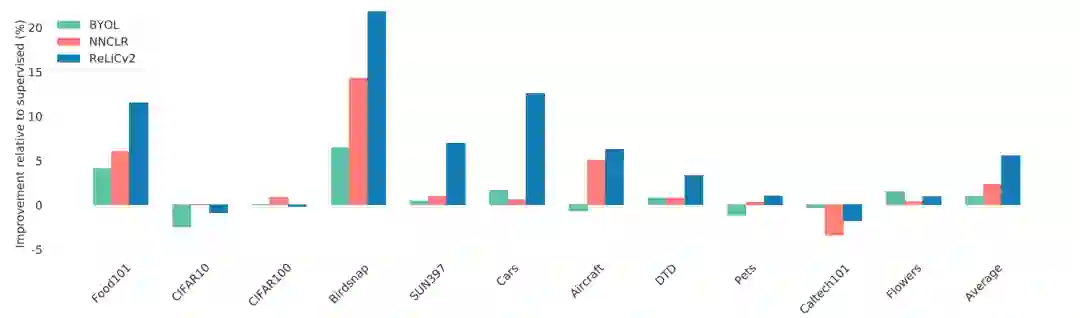

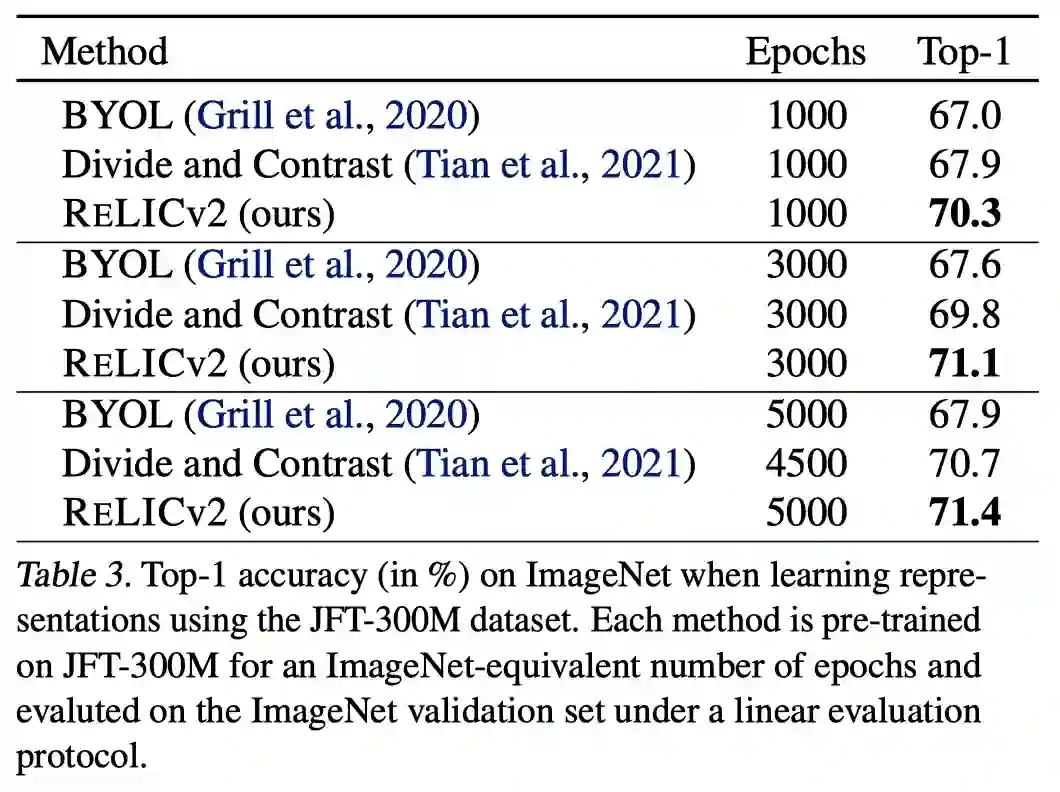
分析
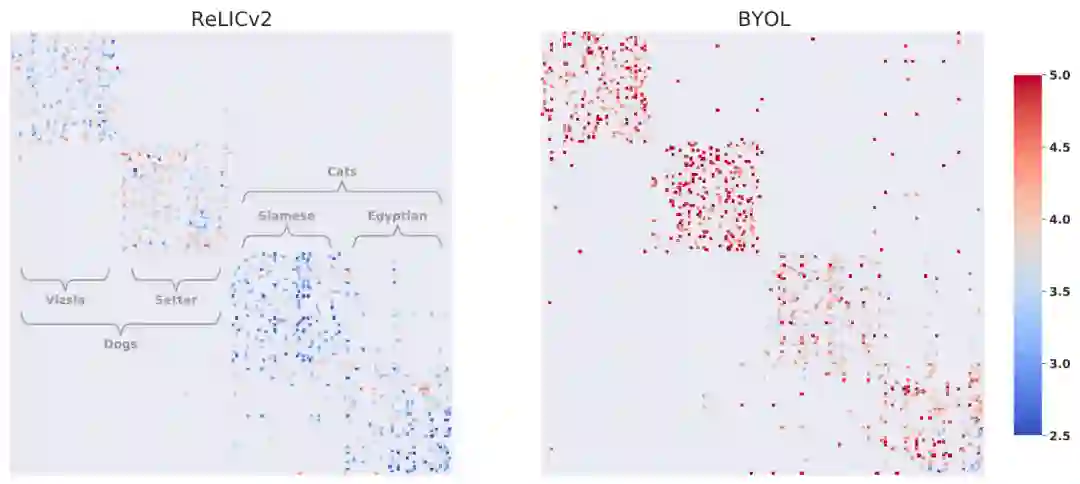
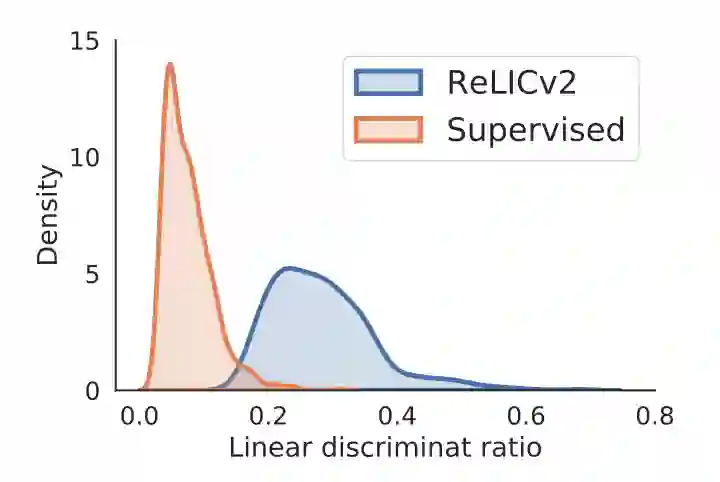
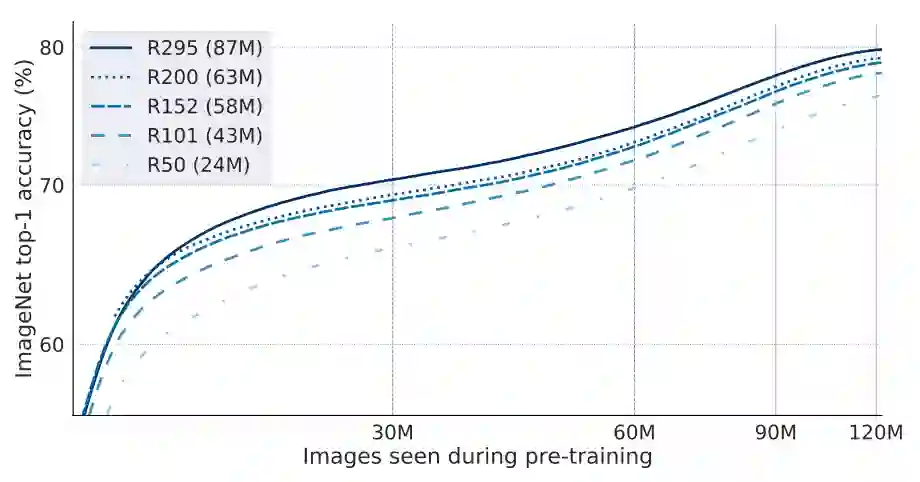
结论
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号

登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文