12层也能媲美ResNet?邓嘉团队提出最新力作ParNet,ImageNet top1精度直冲80.7%

极市导读
是否有可能构建一个高性能的Non-deep(非深度)神经网络呢 ?普林斯顿大学的Jia Deng团队的最新力作ParNet:凭借12层的深度网络在ImageNet上达到了80.7%的top-1精度。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

原文链接:https://arxiv.org/pdf/2110.07641.pdf
代码链接:https://github.com/imankgoyal/NonDeepNetworks
本文是普林斯顿大学的Jia Deng团队的最新力作ParNet:它凭借12层的深度网络在ImageNet上达到了80.7%的top-1精度 。所提ParNet以RepVGG的模块为出发点,同时提出了针对非深度网络设计的SSE模块构建了一种新型的模块RepVGG-SSE 。所提方案凭借非常浅的结构取得了非常高的性能,比如:ImageNet的80.7% ,CIFAR10的96%,CIFAR100的81%,MS-COCO的48%。此外,作者还分析了该结构的缩放规则并说明了如何不改变网络提升提升性能。最后,作者还提供了一份证明:非深度网络如何用于构建低延迟识别系统。
Abstract
Depth(深)是深度神经网络的标志 。但是,更深意味着更多的计算量、更高的推理延迟。这就引出了一个问题:是否有可能构建一个高性能的Non-deep(非深度)神经网络呢 ?本文研究表明:可以 !
为达成上述目标,我们采用了并行子网络 (而非串行)。这种处理方式可以有效降低深度同时保持高性能。
通过利用并行子结构,所提方案首次以深度为12的网络在ImageNet数据集上达到了80.7%性能 ,在CIFAR10上达到了96%,在CIFAR100达到了81%。与此同时,所提方案(深度为12的骨干网络)在MS-COCO数据集上达到了48%AP指标。下图为所提方案与其他CNN、Transformer模型关于深度-性能的对比图。
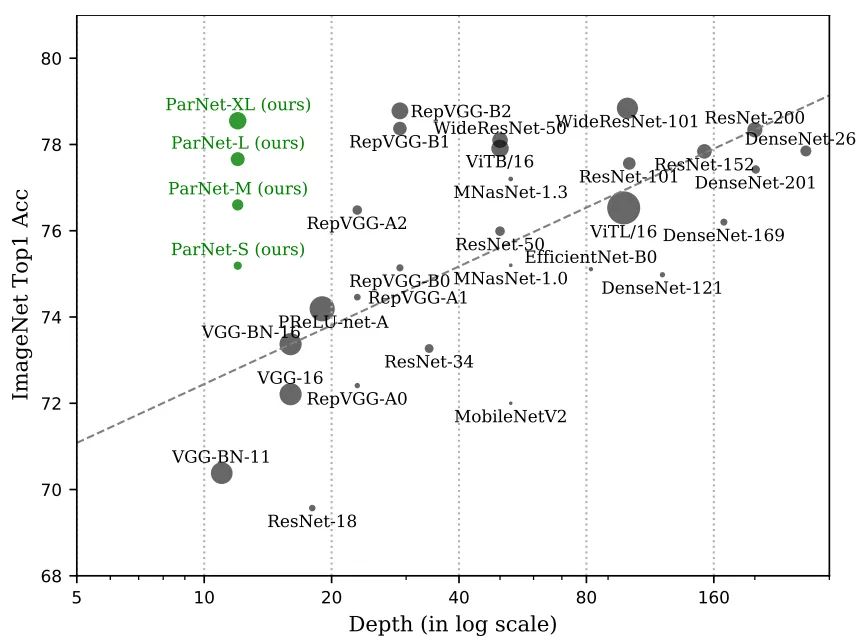
Method
本文提出了一种的新架构ParNet:更浅的同时具有高性能 。ParNet包含用于处理不同分辨率输入的并行子结构,我们将这些并行子结构称之为streams 。不同streams的特征在网络的后期进行融合,融合的特征将用于下游任务。下图给出了本文所提ParNet架构示意图。
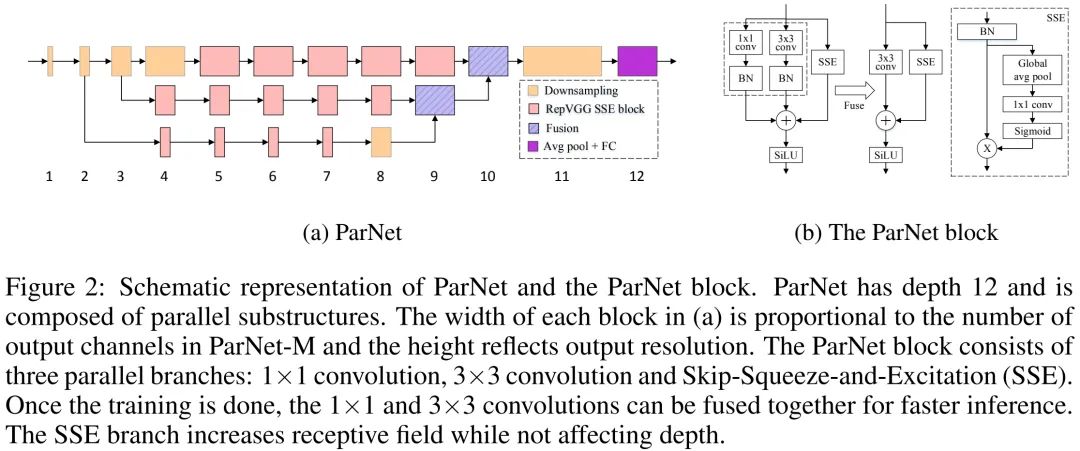
ParNet Block
为探索非深度网络是否可以取得高性能,我们发现VGG风格模块比ResNet风格模块更适合该方案 。因此,ParNet采用了类VGG模块。一般来讲,VGG风格网络要比ResNet的训练难度更大;而结构重参数化(如RepVGG)可以有效解决该训练难问题。
因此,我们从RepVGG中出发并对其进行修改以使其更适合于非深度架构。非深度网络的一个挑战在于: 卷积的感受野非常有限。为解决该问题,我们在SE注意力基础上构建了一个Skip-Squeeze-Excitation (SSE)。由于常规的SE会提升网络深度,因此,常规SE并不适用于我们的架构。所提SSE结构示意图见上图Figure2右,它附加在跳过连接分支上仅包含一个全连接层。我们发现:这种结构设计有助于提升模型性能。我们将上述所构建的模块称之为RepVGG-SSE。
对于大尺度数据集而言,非深度网络可能不具备足够的非线性能力,进而限制其表达能力。因此,我们采用SiLU替代ReLU 。
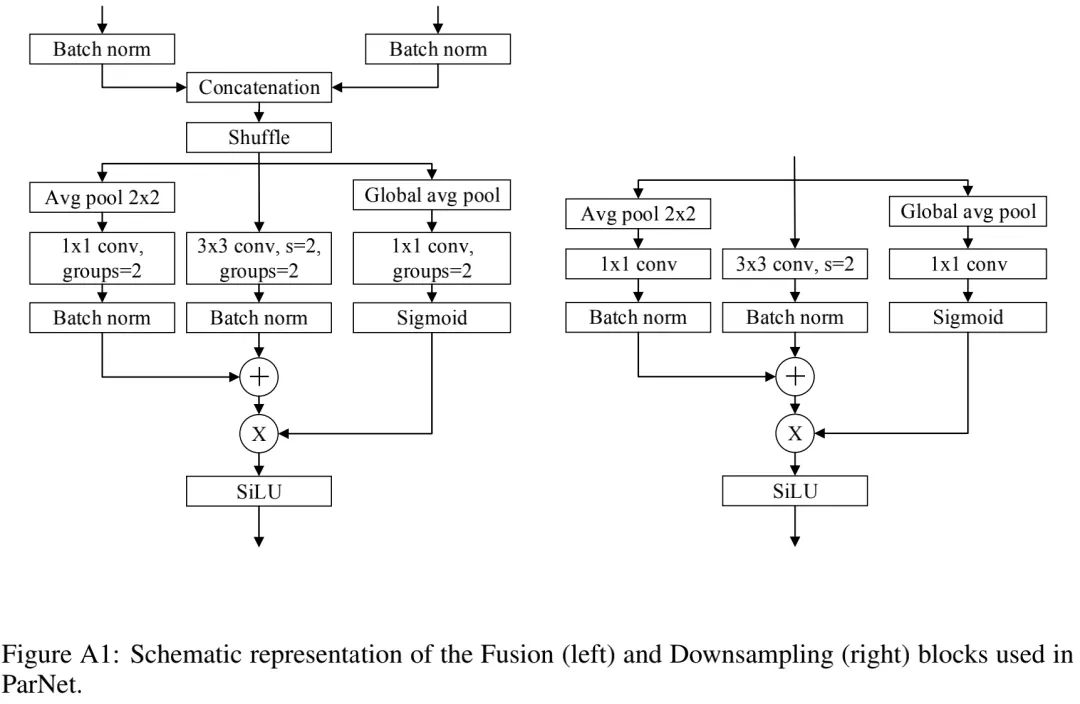
Downsampling and Fusion Block
除了RepVGG-SSE(它的输入与输出具有相同尺寸)外,ParNet还包含一个下采样与融合模块。
-
下采样模块:它用于降低分辨率提升宽度以促进多尺度处理。它同样跳过连接分支,它添加了一个与卷积并行的单层SE模块,此外还在 卷积分支添加了2D均值池化。
-
融合模块:它用于融合不同分辨率的信息。它类似于下采样模块但包含额外的concat层。除了concat外,它的输入通道数更多。因此,为降低参数量,我们采用g=2的组卷积。
Network Architecture
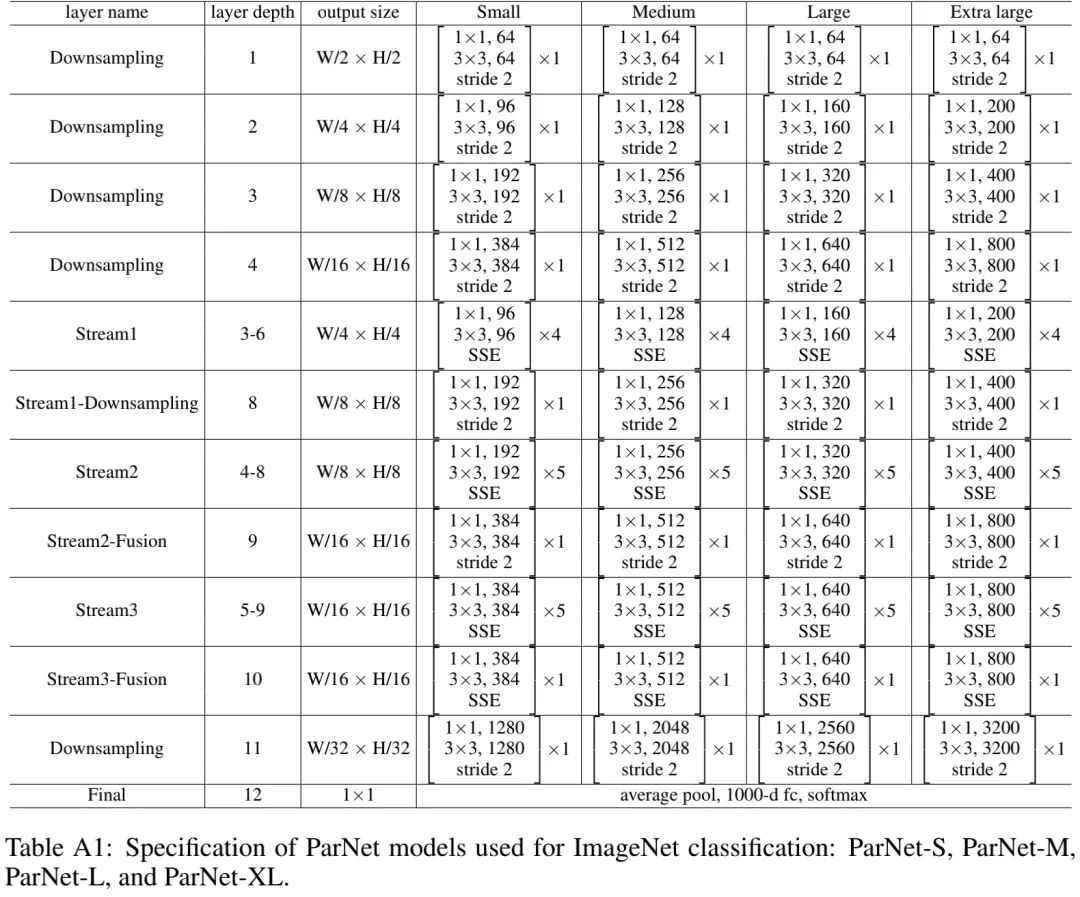
上表给出了所提ParNet结构信息说明,注:上表为针对ImageNet而设计的结构。对于CIFAR任务,网络结构有轻微调整。
Scaling ParNet
已有研究表明:调整网络的深度、分辨率以及宽度可以取得更高的精度。由于我们的目标是评估非深度网络是否可以取得更高的性能 ,因此我们保持ParNet的深度不变转而调整宽度、分辨率以及streams数量 。
对于CIFAR10与CIFAR100,我们提升网络宽度而保持分辨率为32,stream为3;对于ImageNet,我们通过实验对三个维度进行调整。
Experiments
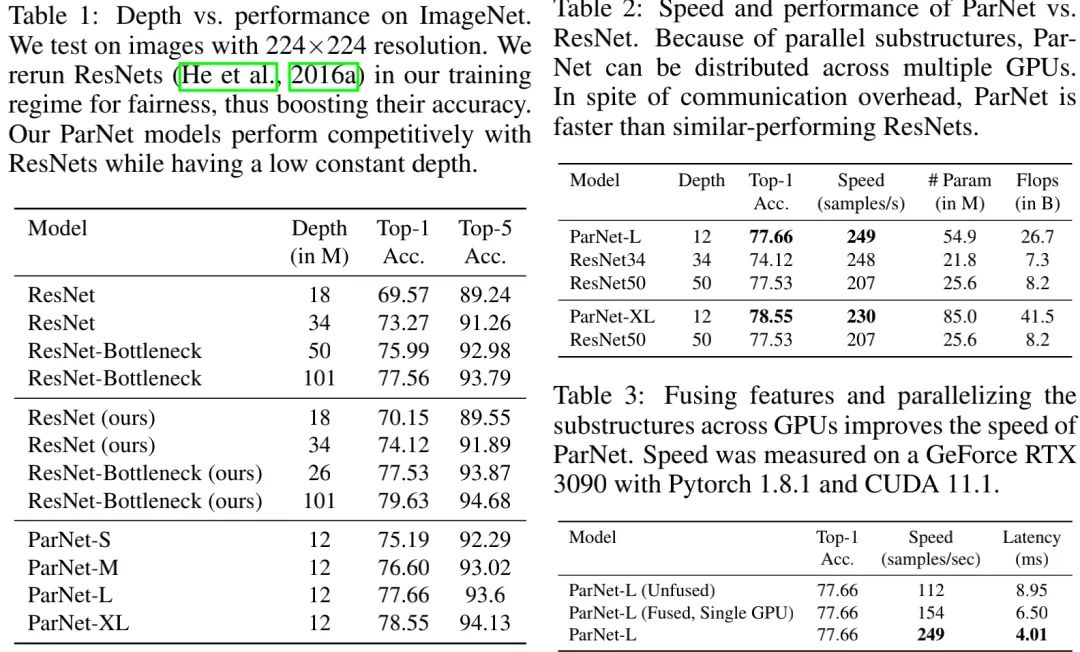
上表1给出了ImageNet数据集上的性能对比,可以看到:
-
深度仅为12的ParNet取得了非常高的性能;
-
ParNet-S具有比ResNet34更高的性能、更低的参数量;
-
ParNet-L具有比ResNet50更高的性能;
-
ParNet-XL具有与ResNet101相当的性能,同时深度仅为其1/8。
上表2给出了所提ParNet与ResNet在精度、速度、参数量以及FLOPs方面的对比,从中可以看到:
-
相比ResNet34与ResNet50,ParNet-L具有更快的速度、更高的精度;
-
相比ResNet50,ParNet-XL具有更快的速度、更高的精度。
-
这就意味着:我们可以采用ParNet替代ResNet以均衡推理速度-参数量-flops等 因素。
上表3给出了三个ParNet的三个变种:unfused、fused以及多GPU。从中可以看到:ParNet可以跨GPU高效并行以达成更快推理 。这里的实现结果是在通讯负载约束下得到,也就是说:通过特定的硬件减少通讯延迟可以进一步提升推理速度 。
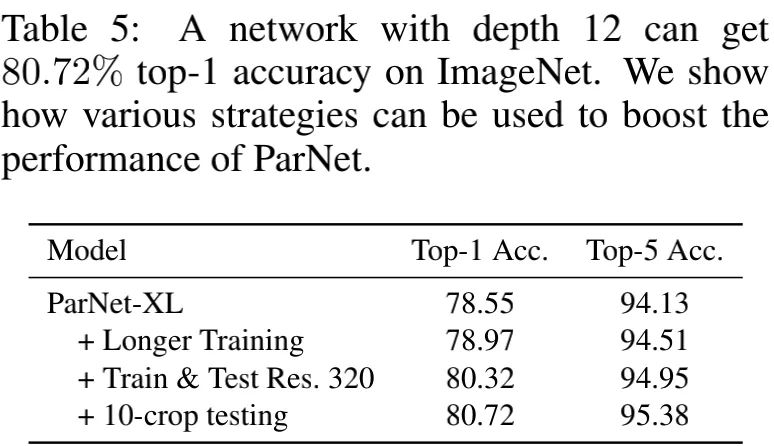
上表通过额外的方式进一步提升ParNet的性能,比如更高分辨率、更长训练周期、10-crop测试。通过不同trick组合,我们将ParNet-XL的性能从78.55提升到了80.72% 。据我们所知,这也是人类识别水平首次被深度为12层的网络达到 。
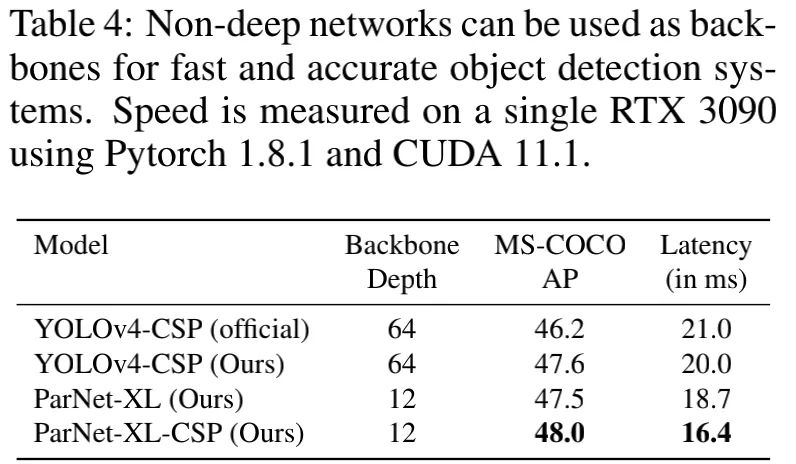
上图给出了ParNet作为骨干时在MS-COCO检测任务上的性能对比,可以看到:相比基线模型,ParNet具有更快的推理速度,更高的性能 。这说明:非深度网络可以用于构建快速目标识别系统 。
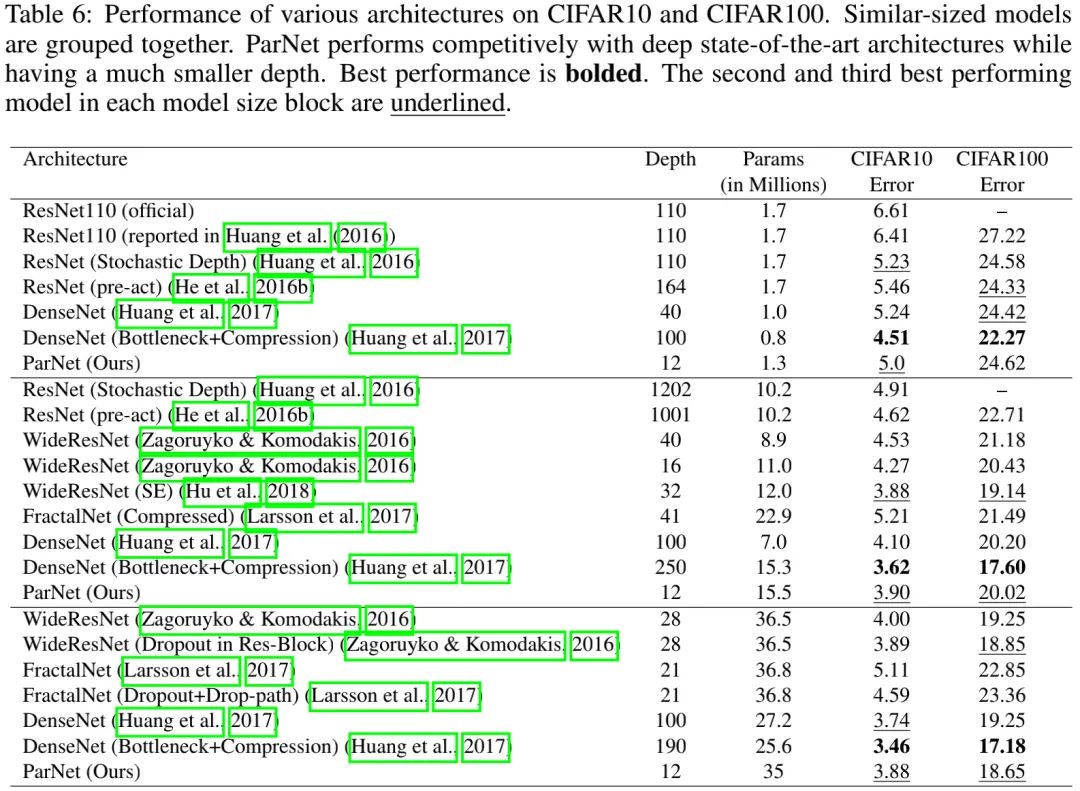
上表给出了CIFAR10与CIFAR100数据集上的性能对比,从中可以看到:
-
ParNet具有与ResNet、DenseNet相当的性能,同时更浅。
-
ParNet超越了深度为其10倍的ResNet(5.0vs5.3),同时具有更低的参数量(1.3Mvs1.7M);
-
ParNet超过了100倍深度的ResNet(3.90vs4.62),但同时参数量多50%;
-
ParNet与DenseNet的表现相当,参数量稍多,但深度少3-8倍。
-
总而言之,ParNet仅需12层即可取得96.12%@CIFAR10、81.35%@CIFAR100。这进一步说明:非深度网络可以表现的像深度网络一样。
Ablation Study
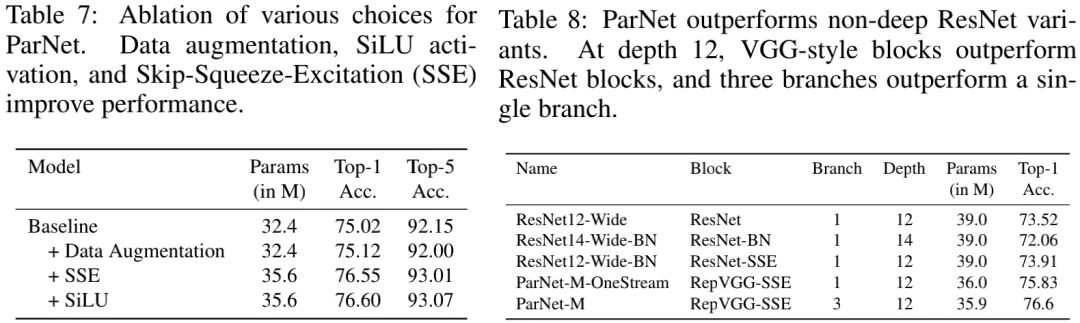
上表7给出了不同设计候选对于ParNet性能影响,可以看到:这三种设计候选均可导致更高的性能。
上表8给出了VGG风格与ResNet风格模块的性能对比,可以看到:VGG风格的模块更适合于本文目标。

上表给出了ParNet与模型集成的性能对比,可以看到:相比模型集成,ParNet性能更优,参数量更少。

上表给出了不同分支(参数量相同)模型的性能对比,可以看到:当固定模型总参数量后,3分支模型具有最高的精度 。
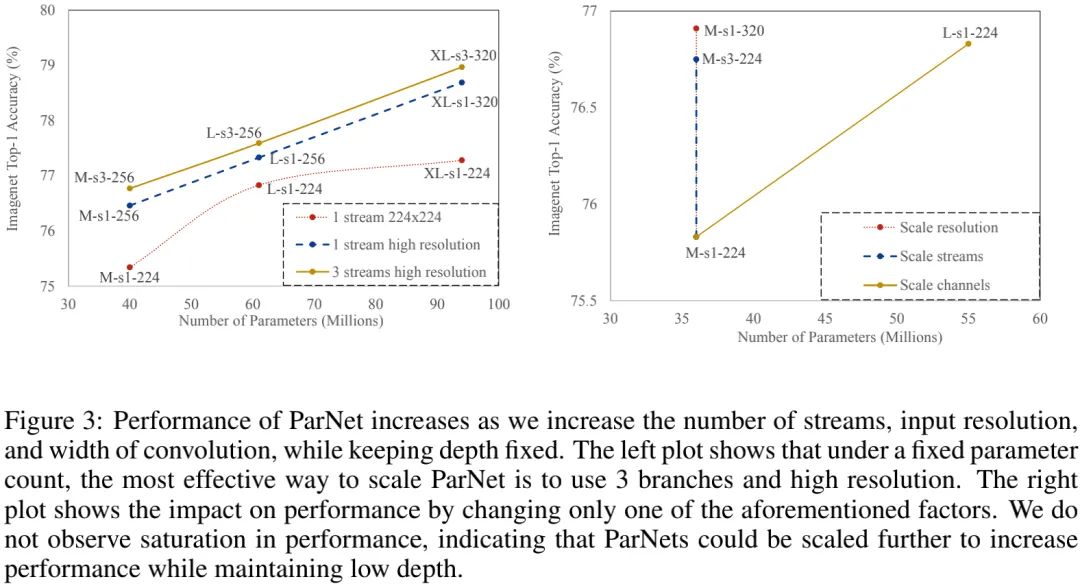
上图给出了模型缩放过程中不同维度的影响,可以看到:
-
相比提升通道数,提升streams可以更合理;
-
对于ParNet来说,同时提升三个维度是最有效的方式;
-
上图并未发现ParNet性能饱和,这说明:进一步提升计算量可以得到更高的性能,同时保持低深度。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV技术深度Follower、爱造各种轮子
研究领域:专注low-level,对CNN、Transformer、MLP等前沿网络架构
保持学习心态,倾心于AI技术产品化。
公众号:AIWalker
作品精选


