

论文链接: https://www.zhuanzhi.ai/paper/113f24612d0cab5c4df98534bc719ebc 代码链接:https://github.com/GeWu-Lab/OGM-GE_CVPR2022
导读
多模态学习通过理解不同类型的数据实现全面的感知和理解。因此,人们一般认为增加输入数据的模态种类可以提升多模态学习模型的性能。本文作者发现,尽管多模态模型的性能一般均超越单一模态模型的性能,但多种模态的输入数据在模型中可能并未得到充分利用。作者指出,这是由于多模态模型在优化过程中倾向于利用损失函数数值较小的模态数据进行参数更新。为解决这一问题,本文提出了一种梯度控制模块来自适应地控制不同模态数据对损失函数和参数更新的贡献率。此外,本文提出在梯度中加入额外的动态高斯噪声能够避免梯度控制可能带来的泛化能力下降问题。上述方法在不同的多模态任务上均取得了有效的验证,并且可以有效、快捷地加入到已有多模态学习模型中来。
贡献
一般情况下,多模态模型的性能可以较大程度地超越单一模态模型的性能。因此,人们默认增加多模态数据似乎能够带来更大的性能提升,但并未有研究人员深入地探索了多模态数据之间的贡献平衡问题。 根据近期的研究,通过一个统一的学习函数进行更新的多模态模型在性能上仍可能会逊于单一模态的模型。作者指出,这一问题可能是由模态间的主导地位导致的(dominated modality),即具有更好性能的模态数据会抑制其他模态数据在更新时产生的作用。
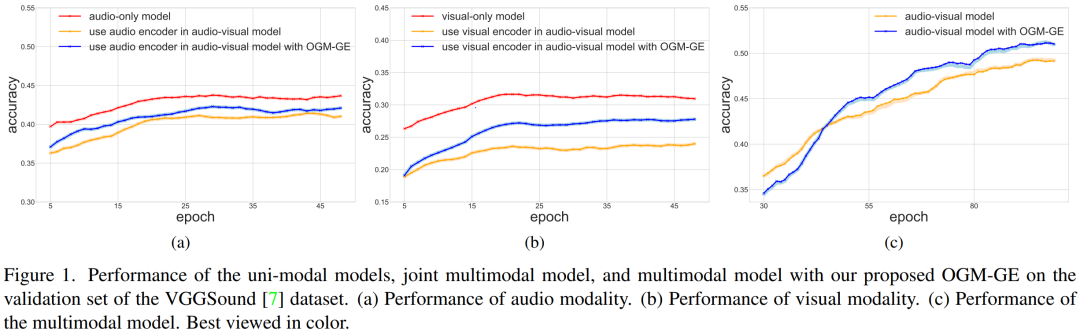
如上图(a)、(b)所示,audio-vision模型在VGGSound数据集的验证集上均逊于audio-only、vision-only这两个单一模态的模型。还有另一点值得注意的是,与audio-only模型相比,vision-only模型的准确度下降得更明显,这与 VGGSound (一个精心策划的面向声音的数据集)更喜欢音频模态的事实是一致的。一般来说,这样的数据集偏好通常会导致一种模态占主导地位,从而导致这种优化不平衡的现象。 为了解决上述问题,本文首先从优化的角度分析了模态间的贡献不平衡现象,发现性能更好的模态有助于降低联合判别损失,然后通过传播优于其他模态的梯度来主导优化过程。因此,本文提出了一种梯度控制模块来自适应地控制不同模态数据对损失函数和参数更新的贡献率。此外,本文提出在梯度中加入额外的动态高斯噪声能够避免梯度控制可能带来的泛化能力下降问题。 本文的主要创新点可以总结如下: * 发现了联合多模态模型的性能由于欠优化表示而受到限制的优化不平衡现象,然后从优化的角度对其进行了分析;
- 提出了OGM-GE方法,通过动态控制各模态的优化过程,增强泛化能力,解决优化不平衡问题;
- 所提出的 OGM-GE 不仅可以插入普通融合策略,还可以插入现有的多模式框架,并带来持续改进,表明其具有广阔的多功能性。
方法
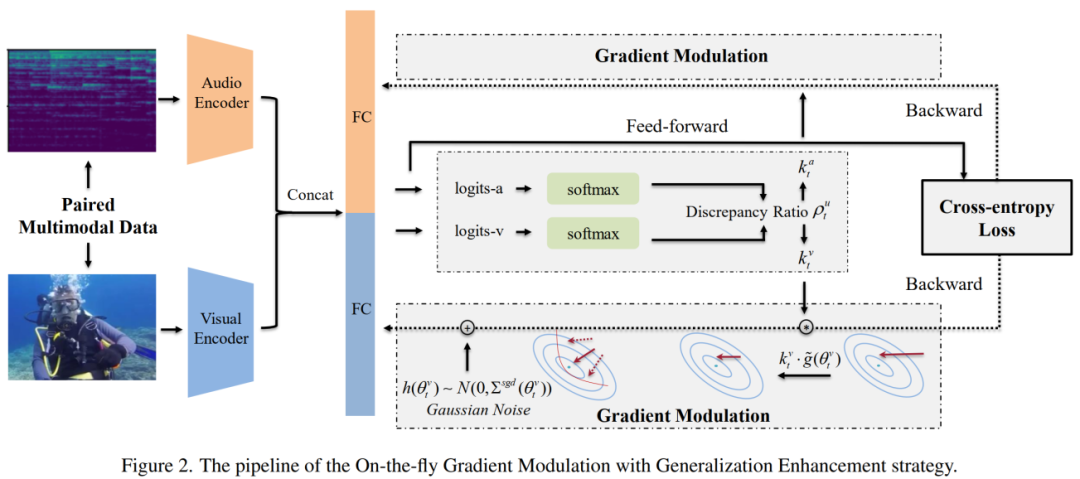
本文提出的OGM-GE方法流程如上图所示,给定视觉、音频两种模态的数据xa、xv,分别使用不同的编码器进行特征映射。因此,各解码器的参数优化过程可以根据梯度下降方法定义如下:
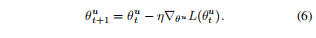
将其扩展为随机梯度下降后:
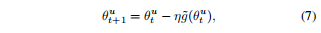
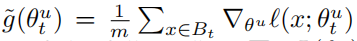
此时,OGM-GE通过计算模态间的差异比例调整不同模态用于更新参数的梯度大小:
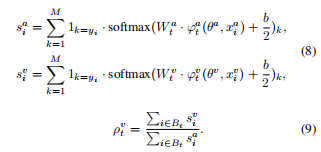
p通过对比不同模态数据造成的梯度影响,生成处于[0,1]数值范围的模块化参数k约束不同模态的梯度信息:
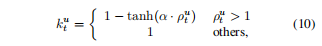
此时,参数的更新过程变化为下式:
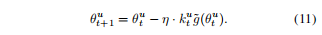
接着,作者发现公式7中定义的随机梯度下降优化过程实际上符合与高斯分布,即:
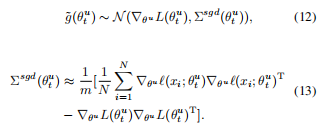
因此,公式7可以重定义为:
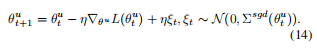
即添加了一项动态的噪声项。总的来说,OGM-GE可以用如下伪代码进行概括:

实验
本文在CREMA-D、Kinetics-Sounds、VGGSound、AVE四个数据集上进行实验验证。首先将OGM-GE应用于几种普通的融合方法:基线、连接和求和,以及专门设计的融合方法:FiLM[32],然后评估在多个数据集上的性能,如表1所示。
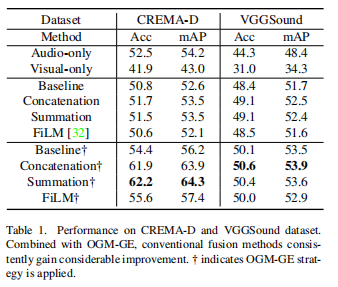
在与OGM-GE结合后,所有融合方法在不同数据集上的性能都得到了显著的提高,这表明了该方法的有效性和令人满意的灵活性。
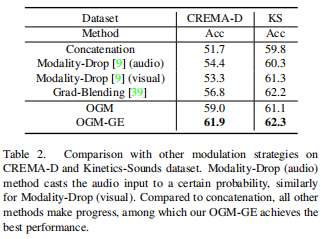
表2所示的结果表明,所有的比较方法或多或少都优于串联基准的性能,这表明不平衡现象确实影响了结果,但也证实了这些方法的有效性。

在表3中,可以发现OGM-GE加强了这两种方法。此外,如前所述,OGM-GE并不局限于音频和视觉编码器在融合过程之前没有交互作用的模型配置。
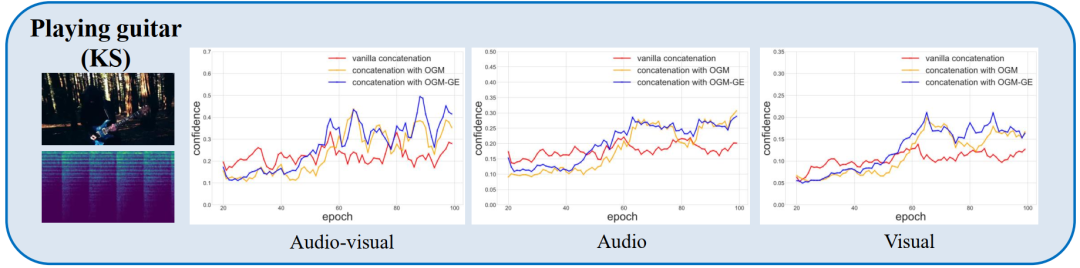
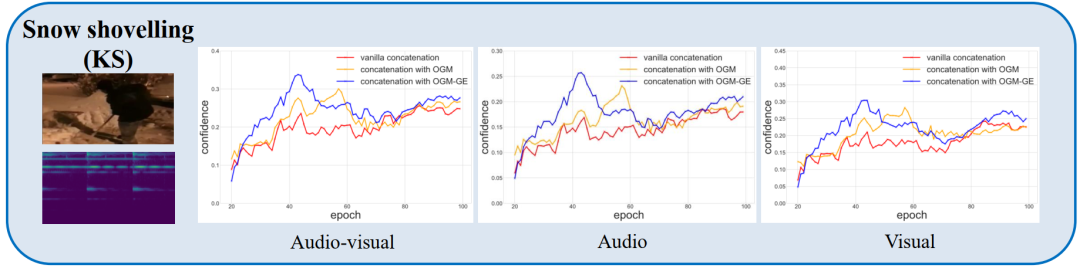
如上图所示,对于大多数样本来说,“弹吉他”是一个音频超过视觉模态的类别(“铲秀”正好相反),我们可以说音频实现了更充分的训练,并引领了优化过程。我们的OGM-GE(以及OGM)在多模态和多模态性能方面都获得了改进,并且弱视觉获得了更好的效果。“音频”和“视觉”中使用的评估指标是仅来自一个特定模态的分类分数的预测准确度。

