编辑:好困 袁榭
【新智元导读】人工智能科学伊始,让机器「像人一样学习」始终是所有从业者的目标。人的智能基于多种感官与语言的通用处理能力,一直有研究者致力让机器做到此效果。
人的智识是「多模态学习」的总和,也就是可以跨越分类界限,理解和移用不同来源或形式的讯息与经验。
好比方,一个人看过自然频道的虎类纪录片,再听到他人描述「白额大猫呼啸生风」时,能据此语言描述结合之前的观影结果,知道别人在描述猛虎,不会贸然跑去滑铲。
让人工智能做到同样的多模态学习效果,是高挑战而高回报的工作。
单独处理声音、图像、文字数据的单个算法再如何亮眼,若不能在不同模态的数据间移用,终究比不上一个算法,单一基础框架能通用于图像识别、音频模态探测、自然语言处理的各种数据。
而Meta AI研究组的data2vec算法就做到了。研究组在自己的博客中称,为了让机器学习更接近人智,有必要克服现有的自监督学习算法对不同模态数据的隔阂。
论文链接:https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
开源项目:https://github.com/pytorch/fairseq/tree/main/examples/data2vec
为此,LeCun也发文表示祝贺:「data2vec在ImageNet(视觉)、LibriSpeech(语音识别)和GLU(NLP)上的结果均优于现有SOTA。」
目前主流的人工智能仍然依靠着基于标注数据进行的监督学习。
这种「监督学习」在训练专门的模型方面性能极好,在它们训练的任务上往往性能表现极高。
然而,拄着「拐杖」的AI在标注数据不足的的领域很容易翻车,而且要悉心地为AI打造一根又一根「拐杖」,有点太费科学家了。
就比如,各国的研究人员在为本国的语音和文本创建大规模的标记数据集方面都做了大量工作,但要为地球上的成千上万种语言做到这一点是不可能的。
自监督让计算机能够通过自己的观察来找出图像、语音或文本的结构从而了解世界,而不需要利用标注的图像、文本、音频和其他数据源。但目前自监督学习算法从图像、语音、文本和其他模态中学习的方式存在很大差异。
算法会为每种模态预测不同的单位:图像的像素或视觉标注,文字的单词,以及语音的声音学习目录。
一组像素与一个音频波形或一段文字是非常不同的,正因为如此,算法设计一直与特定的模态相联系,也就意味着算法在每种模态下的运作方式也各不相同。
这种差异一直是自监督学习想要在更大范围中应用的重要障碍。因为一个为理解图像而设计的强大算法不能直接应用于另一种模态,例如文本,所以很难以同样的速度推动几种模态的发展。
而data2vec是第一个适用于多种模态的高性能自监督算法,可分别应用于语音、图像和文本,它的性能超过了以前最好的计算机视觉和语音的单一用途算法,而且在NLP任务上也具有竞争力。
data2vec的提出代表了一种新的整体自监督学习范式,不仅改进了模型在多种模态下的表现,同时也不依赖于对比性学习或重建输入实例。
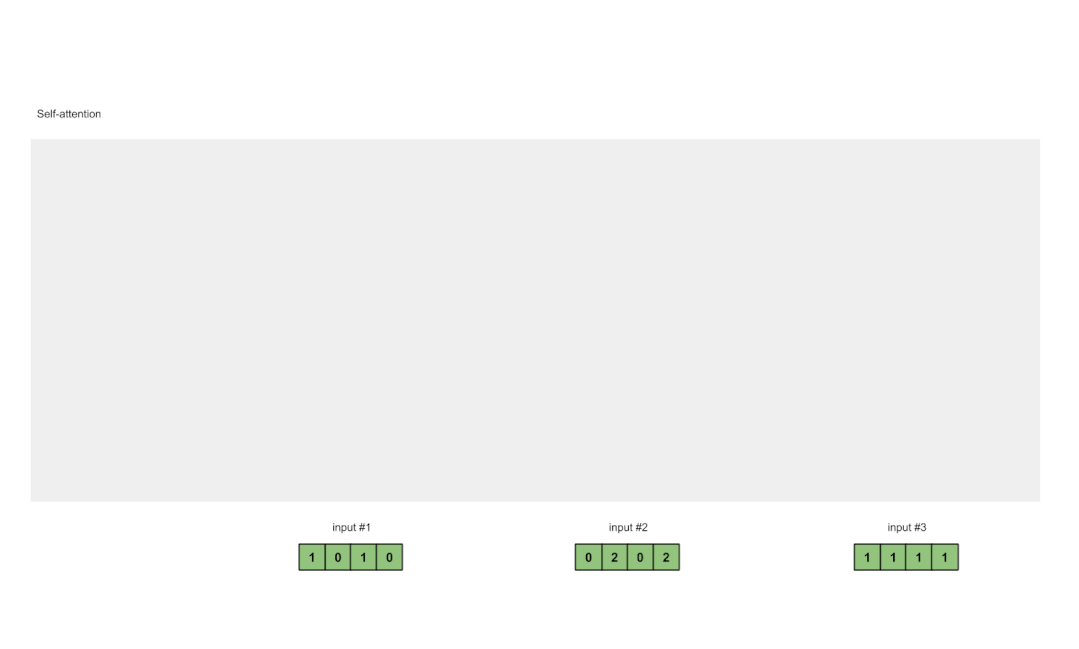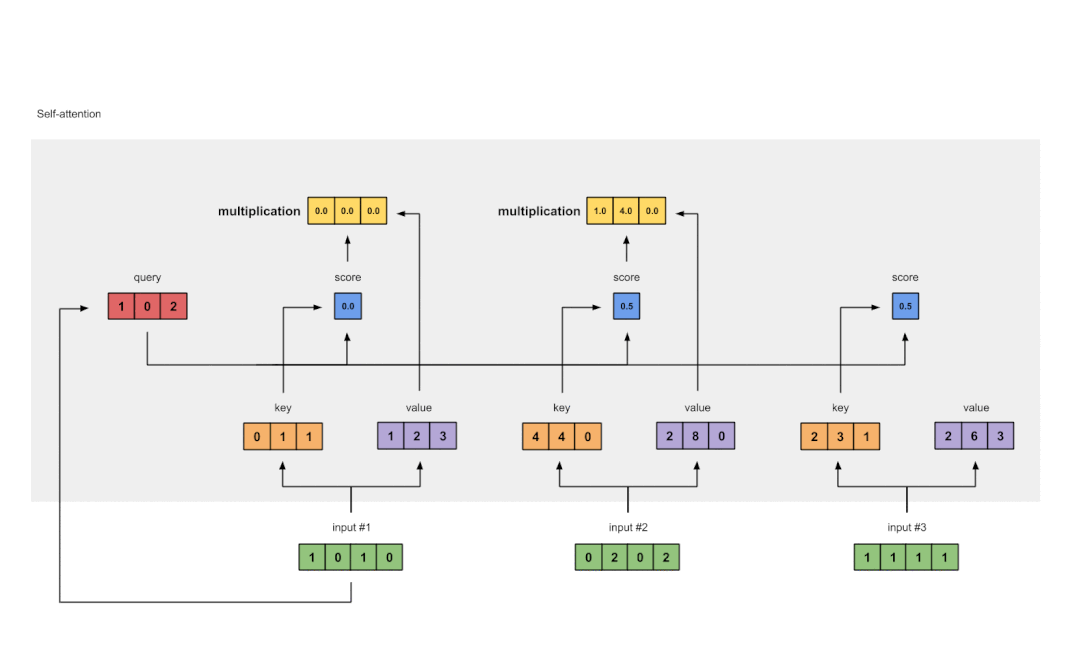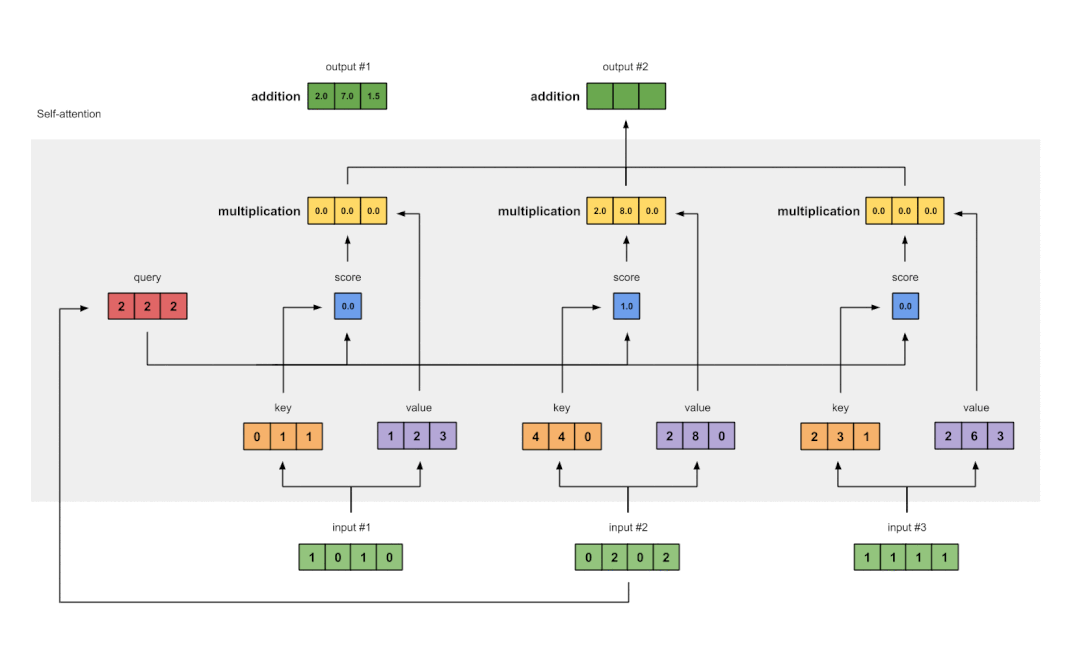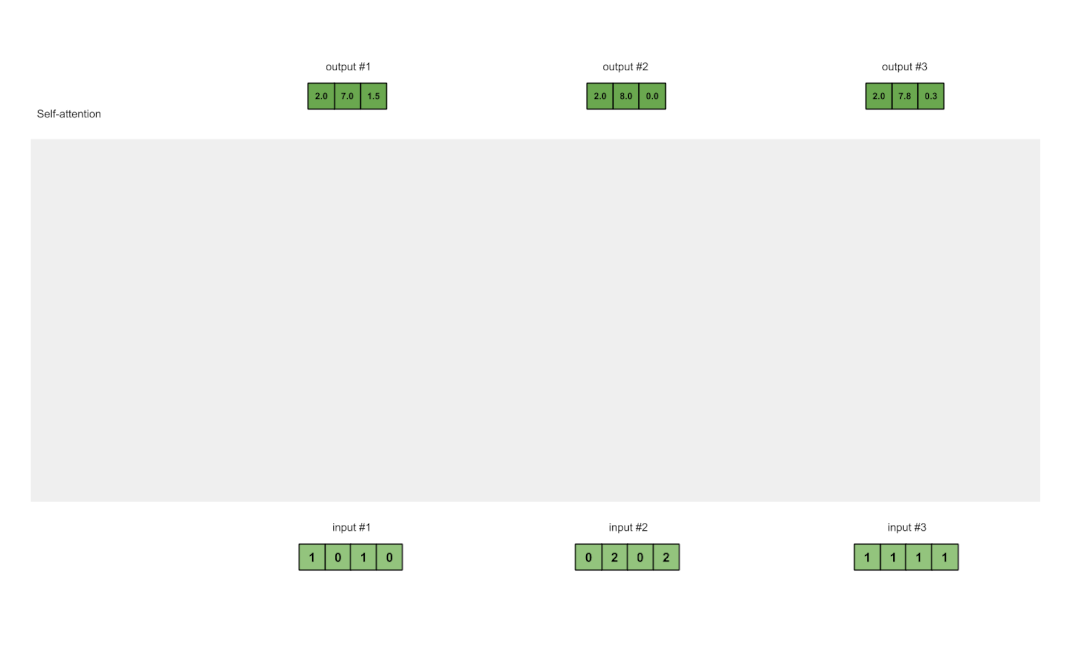
data2vec通过训练模型来预测它们自己对输入数据的表征,而不考虑模态。
通过这些表征,而不是预测视觉标注、单词或声音,单一的算法就可以处理完全不同类型的输入,从而消除了学习任务中对特定模态目标的依赖。
然而,想要预测表征之前,还需要为任务定义一个在不同的模态下都能达到稳健的规一化特征。
data2vec使用一个教师模型,首先从图像、文本或语音语调中计算出目标表征。接下来,掩码部分输入,用学生模型重复这一过程,然后预测教师的潜在表征。
学生模型必须预测全部输入数据的表征,尽管它只看到了部分信息。
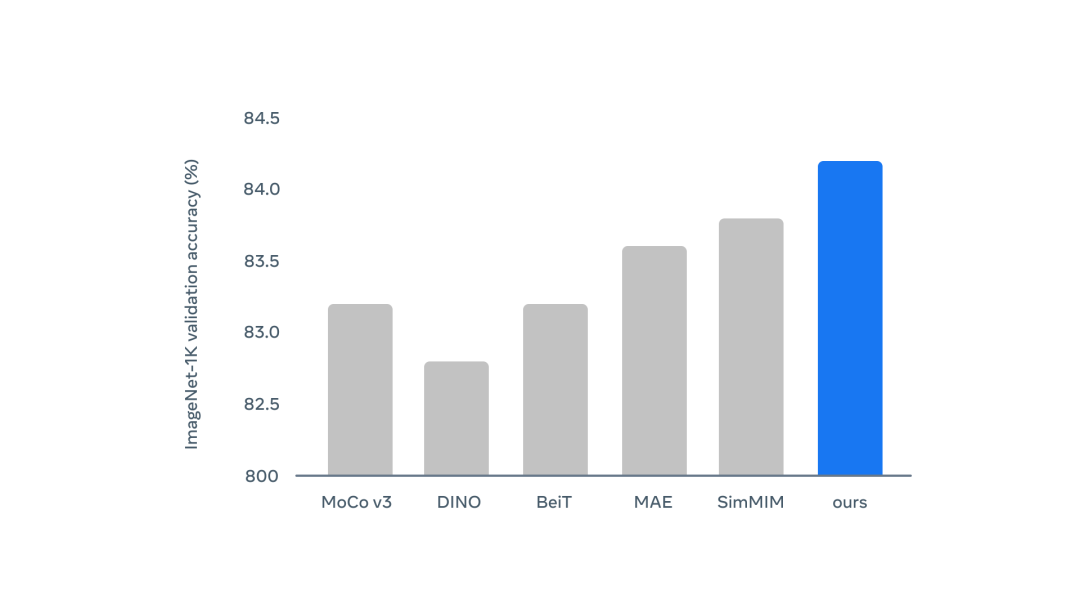
作者在ImageNet-1K训练集的图像上对data2vec进行了预训练,并使用同一基准的标记数据对得到的图像分类模型进行了微调。
对于需要预测每张图片单一标签的下游任务,作者通过在均值池表征的基础上堆叠一个softmax归一化的分类器来实现。
结果显示,data2vec超过了之前使用ViT-B和ViT-L的工作。与预测原始输入像素、工程图像特征或视觉标注等局部目标的方法相比,在掩码预测设置中预测语境化潜在表征的表现非常好。
此外,data2vec也优于目前SOTA的自蒸馏方法。
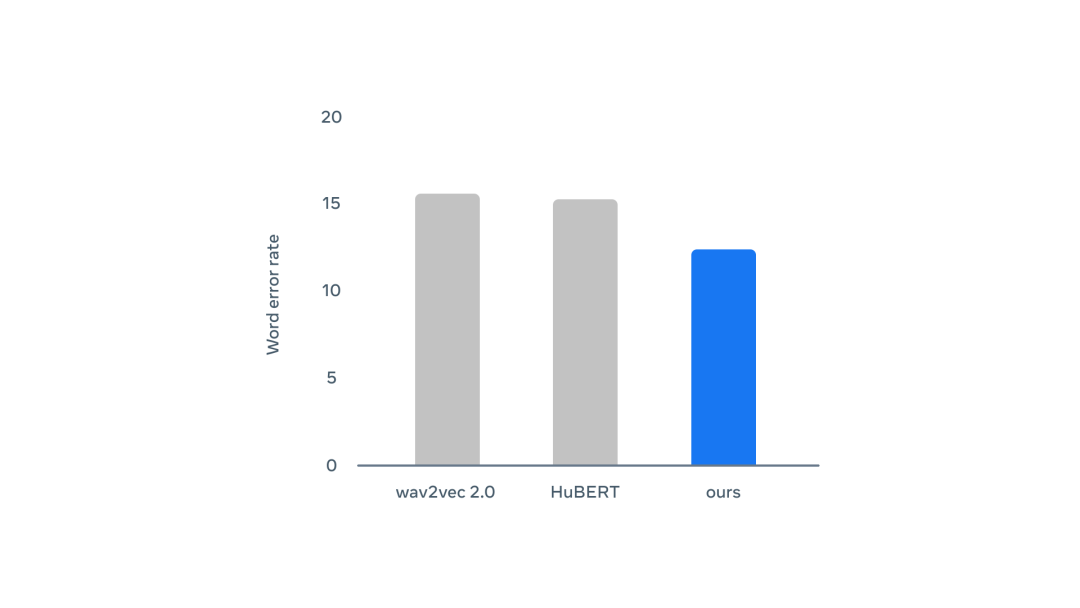
团队在来自Librispeech(LS-960)的960小时的语音音频数据上对data2vec进行预训练。这个数据集包含了来自英语有声读物的相对清晰的音频。
为了了解不同资源环境下的性能,作者使用不同数量的标注数据对自动语音识别模型进行了微调,范围从10分钟到960小时。
通过和两种依赖于离散语音单元的语音表征学习算法wav2vec 2.0和HuBERT进行比较。结果显示,data2vec在所有的标注数据设置中都有了改进,其中10分钟标注数据的收益最大(相对误码率提高20%)。
此外,当使用丰富的语境化目标时,在预训练期间学习语境化目标就可以提高性能,而不需要学习离散的单元。
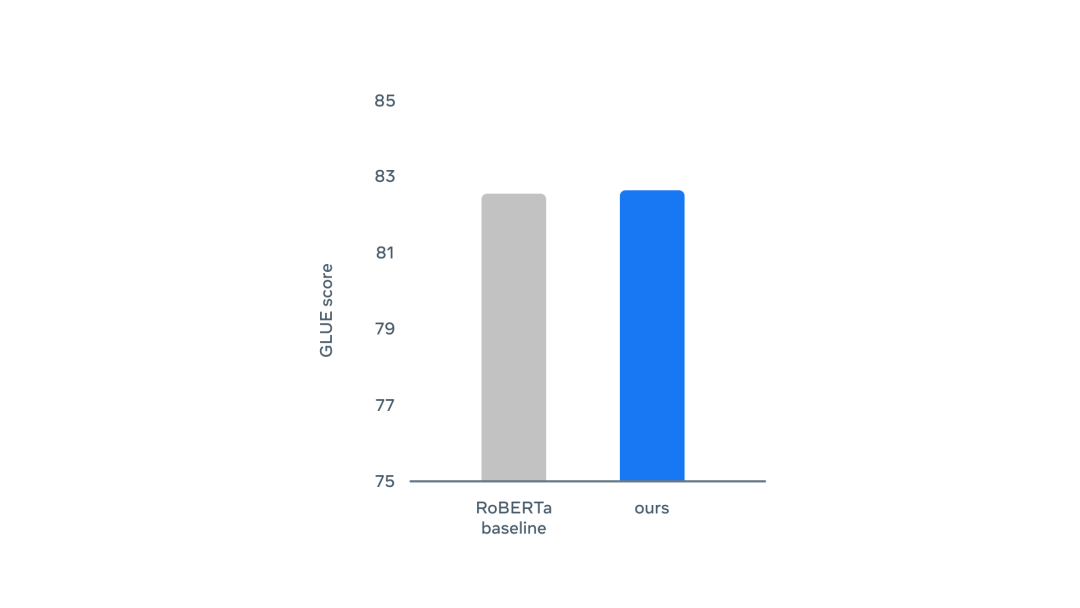
data2vec采用了与BERT相同的训练设置,在书籍语料库和英语维基百科数据上进行预训练,更新量为100万,batch大小为256个序列。
团队通用语言理解评估(GLUE)基准上进行测试,其中包括自然语言推理(MNLI、QLNLI、RTE)、句子相似性(MRPC、QQP和STS-B)、语法性(CoLA)和情感分析(SST-2)等任务。
作者在每个任务提供的标注数据上分别对data2vec进行微调。结果显示,data2vec优于RoBERTa的基线。
data2vec是第一个成功的预训练NLP模型,它不使用离散单位(词、子词、字符或字节)作为训练目标,而是预测在整个未掩码的文本序列中,从自注意中出现的上下文潜在表征。
这使得学习任务中,模型需要预测具有当前文本序列特定属性的目标,而不是对特定离散单元出现的每个文本序列通用的表征。
此外,训练目标不是一个封闭的词汇表。由此,模型可以自己定义它认为合适的目标类型。
相较于2021年谷歌为达到类似目标,7月推出的Perceiver与10月放风的Pathways,Meta的data2vec都有优势:Pathways是没具体细节与论文的行业公关动作,而Perceiver还在基于传统的标记数据、有监督学习的路径。
Meta AI研究组在总结研究时表示,data2vec有众多落地可能,让AI通过录像、录音、文章的结合,能学会之前对于机器而言太过复杂的技能,比如烤面包的各种方式、踢足球的各种技术。
这些技能如同语音识别地球上所有的语言一样,用标注数据来教会AI,成本太高。而AI未来用通行的架构,学会跨越数据模态的通用经验,来举一反三完成不同任务,这个目标让data2vec拉近了。
此外,研究团队还表示:「实验处理的潜在表征变量不是三模态数据的混合编码。我们还是在单一过程中处理单一模态数据的。不过本项目的主创新点,是data2vec对不同模态数据的处理过程基本一致。这是之前没人做到的,也更近于神经生物学家描述的人类视听学习过程。」
不过,data2vec的多模态通用神经网络并非没有短板:它得依赖数据的模态标记。图像、语音、文字这些数据,都得先预处理得到模态分类。然后将这些数据类型的线索喂给data2vec,用论文中的原话说,这叫「小型模态相关的编码器输入」。
而真正的人类智识是不需要先预处理数据、分类「此为文字来源知识、彼为二大爷口述讯息」的。
Wei-Ning Hsu 徐炜宁,Meta人工智能研究组高级研究科学家,博士毕业于MIT,研究方向为表征学习、自监督学习、语音识别。
Jiatao Gu 顾佳涛,Meta人工智能研究组研究科学家,香港大学电子工程博士,研究方向为自然语言处理与深度学习。
Qiantong Xu,Meta人工智能研究组高级研究工程师,研究方向为声波建模与对话模态识别的语言建模。
参考资料:
https://ai.facebook.com/blog/the-first-high-performance-self-supervised-algorithm-that-works-for-speech-vision-and-text/
https://www.zdnet.com/article/metas-data2vec-is-the-next-step-toward-one-neural-network-to-rule-them-all/
![]()