
大型的、预训练的基于Transformer的语言模型,如BERT,已经极大地改变了自然语言处理(NLP)领域。我们对最近的研究进行了调研,这些研究使用了大型语言模型来解决NLP任务,通过预训练、微调、提示或文本生成方法。我们还提出了使用预训练语言模型生成数据的方法,用于训练增强或其他目的。最后,我们讨论了局限性,并提出了未来研究的方向。
引言
近年来,大型预训练的基于Transformer的语言模型(PLMs),如BERT (Devlin et al., 2019)和GPT (Radford et al., 2018)系列模型席卷了自然语言处理(NLP),在许多任务中实现了最先进的性能。
这些大型PLM推动了NLP的范式转变。以分类任务p(y|x)(将文本输入x分类为标签y)为例:传统统计NLP方法通常设计手工特征来表示x,然后应用机器学习模型(如SVM (Cortes and Vapnik, 1995)、逻辑回归)来学习分类函数。深度学习模型通过深度神经网络(LeCun et al., 2015)。注意,每个新的NLP任务都需要重新学习潜在特征表示,而且在许多情况下,训练数据的大小限制了潜在特征表示的质量。考虑到语言的细微差别对所有NLP任务来说都是共同的,我们可以假设我们可以从一些通用任务中学习一个通用的潜在特征表示,然后在所有NLP任务中共享它。语言建模需要学习如何在给定前一个单词的情况下预测下一个单词,这是一项具有大量自然出现的文本的通用任务,可以预训练这样一个模型(因此得名预训练语言模型)。事实上,最新的、正在进行的范式转换从引入PLMs开始: 对于大量的NLP任务,研究人员现在来利用现有的PLMs通过对感兴趣的任务进行微调,提示PLMs执行期望的任务,或者将任务重新构造为文本生成问题,并应用PLMs来解决相应的问题。这三种基于PLM的范式的进步不断地建立了新的最先进的性能。
本文调研了最近利用PLM进行NLP的工作。我们将这些工作组织成以下三种范式:
-
先进行预训练,然后进行微调(§2): 先对大量未标记语料库进行通用预训练,然后对感兴趣的任务进行少量的任务特定微调。
-
基于提示的学习(§3):提示一个PLM,这样解决NLP任务就会减少到类似于PLM的训练前任务(如预测一个遗漏的单词),或一个更简单的代理任务(如文本包含)。提示通常可以更有效地利用PLM中编码的知识,从而产生“少样本”的方法。
-
NLP作为文本生成(§4): 将NLP任务重新定义为文本生成,以充分利用生成语言模型(如GPT-2 (Radford et al., 2019)和T5 (Raffel et al., 2020)中编码的知识。
-
生成式PLMs也可以用于文本生成任务。我们向读者推荐关于文本生成的优秀调研,如Li et al. (2021b) 和Yu et al. (2021b)。除非另有说明,本文主要关注非生成性任务(如分类、序列标注和结构预测),这些任务仍然涵盖广泛的NLP任务,包括文本的语法或语义解析、信息抽取(IE)、问答(QA)、文本蕴涵(TE)、情感分析、等等。除了这三种范式之外,还有另一种互补的方法:间接使用上述任何一种PLM范式来改善目标NLP任务的结果:
-
数据生成(§5): 运行PLM自动生成NLP任务的数据。生成的数据可以是银色标记的数据,通常生成的PLM是针对任务进行微调的,或者是一些辅助数据,如反例、澄清、上下文或其他。在第一种情况下,银色标记数据可以添加到现有的标记数据中。在第二种情况下,辅助数据以某种方式支持目标任务。
论文组织如下: 第2节提供了PLM的背景,并描述了第一种范式,即预训练然后微调。第三节讨论第二种范式,即基于提示的学习。第4节总结了第三种范式,即作为文本生成的NLP。在第5节中,我们将描述通过PLM为广泛的NLP任务生成数据的方法。我们将在第6节讨论局限性并提供未来研究的方向,并在第7节进行总结。
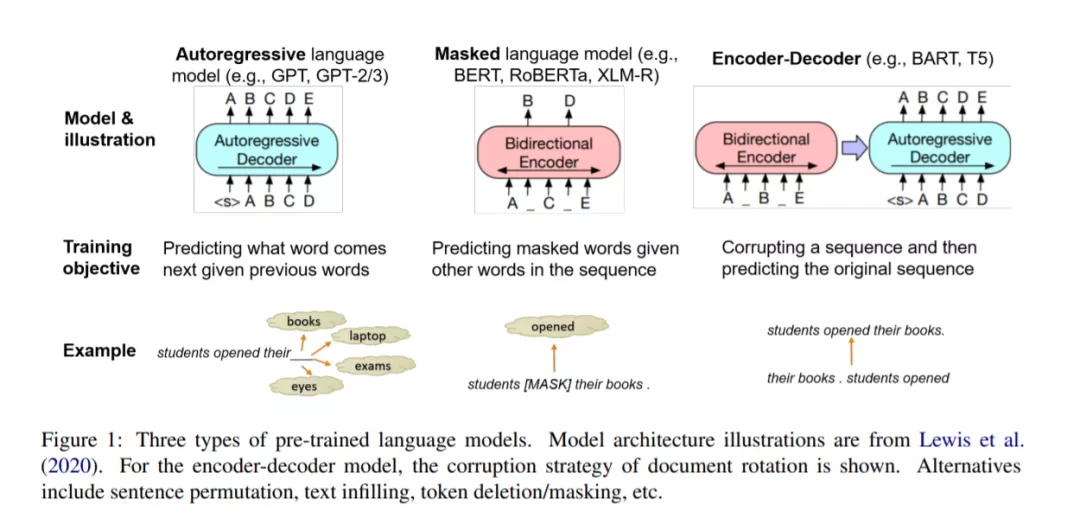
范式1: 先训练,然后微调
传统统计NLP的工作重点是在标记数据集上训练特定任务的模型,而这种模式转变为在一个共享的、“基本”的预训练任务上训练一个大型模型,然后在第二步中将其调整(“微调”)到各种任务。预训练任务几乎总是一种语言建模任务,它可以利用大量的未标记数据来学习有利于一系列NLP任务的表示(Rogers et al., 2020)。在本节中,我们首先提供关于预训练的大型语言模型(PLMs)的入门知识,然后描述使用冻结或微调PLM进行NLP任务的方法。

范式2: 基于提示的学习
我们使用提示指的是在输入或输出中添加自然语言文本(通常是短语)的做法,以鼓励预训练的模型执行特定任务(Yuan et al., 2021)。使用提示符有几个优点。提示,特别是上下文学习(例如Brown et al., 2020),可能不需要更新PLM的参数,与微调方法相比,或在2.4.4中描述的基础上,减少了计算需求。提示还能促使新任务的制定与预训练的目标更好地结合,从而更好地利用预训练获得的知识。更紧密的匹配还支持少样本方法(Liu et al., 2021b),特别是对于具有小训练数据集的任务;一个好的提示可以值几百个标签数据点(Le Scao and Rush, 2021)。最后,提示允许以一种不受监督的方式探索PLM,以评估PLM对特定任务所获得的知识(如Petroni et al., 2019)。
下面我们讨论三种基于提示的学习方法:从指令和演示中学习、基于模板的学习和从代理任务中学习。图3显示了这三种方法的说明。

范式3 NLP即文本生成
基于生成式Transformer的PLMs10(如GPT、BART和T5)的成功,最近激发了人们对利用生成式PLM解决各种非生成式NLP任务的兴趣。这些任务包括但不限于传统的判别任务,如分类和结构预测。例如,图4说明了Raffel等人(2020)所描述的这种“文本到文本”方法。与传统的NLP任务判别模型不同,这些任务被重新表述为文本生成问题,从而可以直接用生成式PLM解决。生成的输出序列通常包括给定任务所需的标签或其他辅助信息,从而能够准确地重构预期的类标签(即避免映射中的歧义),并促进生成/解码过程(即为预测提供足够的上下文)。

总结
在这篇文章中,我们介绍了三种使用预训练语言模型进行自然语言处理的趋势。我们对每一种方法都进行了深入的描述,并对其应用前景进行了总结。此外,我们还描述了使用预先训练过的语言模型来自动生成用于提高NLP任务性能的数据。我们希望这一调研将为读者提供关键的基本概念和对范式转变的全面看法。

