微信看一看强化学习推荐模型的知识蒸馏探索之路丨CIKM 2021


导语
强化学习(Reinforcement learning, RL)已经在真实世界的推荐系统中被广为验证。然而,基于强化学习的推荐算法常常会带来巨大的内存和时间成本。知识蒸馏(Knowledge distillation, KD)则是一种常见的有效压缩模型同时尽量保持模型有效性的方法。但是,推荐中的强化学习模型往往需要在极度稀疏的用户-物品空间中进行大规模的探索(RL exploration),而这增加了强化学习推荐模型进行蒸馏的难度。
在强化学习蒸馏中,老师(teacher)需要教给学生(student)哪些课程(例如老师对于有标签/无标签的user-item对的评分),以及学生需要从老师的课程中学习多少(即每个蒸馏样例的学习权重),需要被精细地规划和设计。在这个工作中,我们提出了一个全新的蒸馏强化学习推荐模型(Distilled reinforcement learning framework for recommendation, DRL-Rec),希望能够在压缩模型的基础上保持(甚至提升)模型的效果。
具体地,我们在模型蒸馏前加入一个探索/过滤模块(Exploring and filtering module),从老师和学生两个角度判断蒸馏中什么样的信息应该从老师传给学生。我们还提出一个置信度引导的蒸馏(Confidence-guided distillation),在list-wise KL divergence loss和Hint loss两种蒸馏目标学习中加入置信度的权值,以指导学生从老师更加擅长的课程中学习更多。目前,DRL-Rec已经部署于看一看推荐系统,服务千万用户。
模型背景与简介
现有的feed流推荐系统往往会采用list-wise的推荐方式:推荐模型对每一次用户请求提供一个item list(例如10个item)。Lise-wise模型会综合考虑用户对这个list的整体满意度进行推荐(点击、时长、多样性等)。这种list-wise推荐可以被建模成一个从前到后依次推荐item的序列化决策过程,而基于强化学习的模型则天然适配这种序列化决策建模,因此被广泛地应用于真实系统(如HRL-Rec、PAPERec等)。
然而,真实世界的推荐系统需要综合考虑大量特征和特征组合进行个性化推荐。随着深度神经网络的发展,更大更深的模型虽然带来了效果提升,也不可避免地带来了时间和空间复杂度的大幅提升。这种模型大小和计算成本的提升在list-wise RL-based推荐场景下更为明显,因为模型需要考虑整个item list的建模。因此,我们亟需一种高效的强化学习模型压缩方法。
知识蒸馏(Knowledge distillation, KD)是一种基于老师-学生机制的有效压缩模型且保持模型有效性的方法。它将知识从复杂的老师模型(teacher)中迁移到低成本的学生模型(student)中,学生可以通过真实标签或者老师预测的软标签(soft label)进行学习。Hinton et al. (2014) 的知识蒸馏经典工作证明,KD不仅能够压缩模型,降低空间时间复杂度,同时甚至能通过teacher预测的negative logits引入更多信息,反过来提升student的效果。另外,teacher模型也能基于海量无标注数据进行数据增强,作为弱监督信息进一步辅助student的学习。这种机制对于稀疏性问题严重的推荐系统尤为重要。
知识蒸馏在推荐中已被广泛验证,然而几乎没有工作探索在强化学习推荐模型之间的蒸馏。我们认为list-wise RL-based推荐模型的蒸馏主要存在以下两项挑战:
(1)teacher需要教给student怎样的课程?传统的知识蒸馏在分类任务上,基于softmax的negative logits为student提供额外的信息,这些分类任务一般不超过几百的量级。然而,在推荐强化学习,特别是list-wise推荐的场景下,RL模型探索全部可能的action(生成推荐的item,通常是百万级)空间并进行蒸馏,是既不可能也不必要的。我们认为一个高效的RL推荐蒸馏模型在选择蒸馏的样例(user-item对)时,需要先离线探索(explore)可能被点击的item,过滤(filter)掉不相关的点击概率不大的item,然后将teacher在精选item上的评分通过蒸馏(distill)传递给student,完成高效的基于蒸馏的数据增强(这类似于物理中蒸馏前的过滤操作)。
(2)student需要从过滤后的teacher的课程中学习多少知识?如前所述,在list-wise推荐中,一个teacher RL模型几乎不可能准确预测出整个state-action空间的全部样例。在这种情况下,teacher产生的reward很可能含有巨大的噪声,特别是对于没有真实用户反馈的user-item对,teacher的噪声更大。因此,过滤后的蒸馏样例的置信度也需要被考虑。
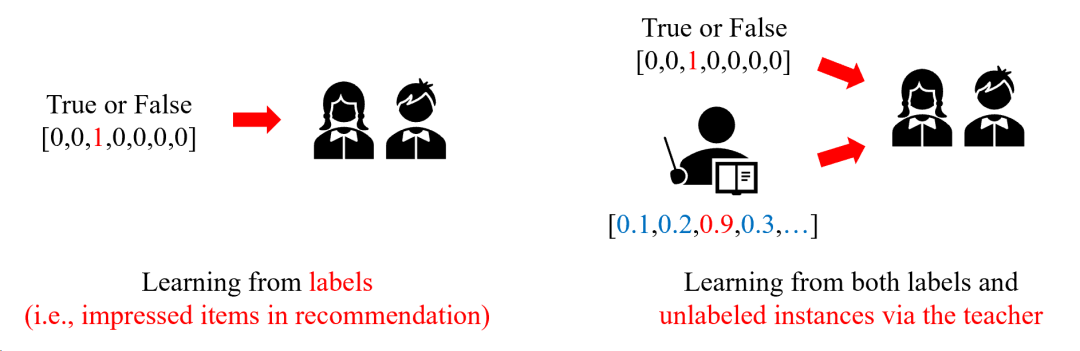
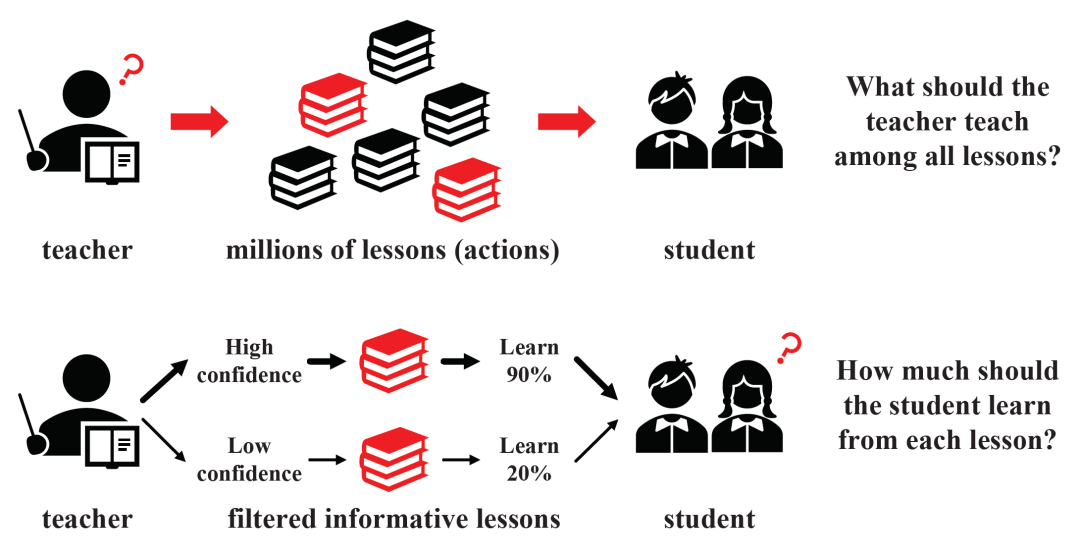
图1:强化学习推荐模型进行知识蒸馏的挑战
为了解决这些挑战,我们提出了一个全新的蒸馏强化学习推荐模型(Distilled reinforcement learning framework for recommendation, DRL-Rec),希望能够在压缩模型的基础上保持(甚至提升)list-wise推荐模型的效果。DRL-Rec主要包括三个模块:老师/学生(主推荐网络)模块(Teacher and student module),探索/过滤模块(Exploring and filtering module),置信度引导的蒸馏模块(Confidence-guided distillation)。
具体地:(1)我们首先参考HRL-Rec强化学习推荐模型(Xie et al. (2021))的网络结构,构建了相同网络结构、不同向量维度的teacher和student模型。我们使用了DDQN这种value-based RL进行训练,因为它在蒸馏下表现更加稳定。
(2)在探索/过滤模块,我们提出一个新的双向主导(dual-led)的学习策略。具体地,对于一个user,我们首先快速召回一批item作为候选,然后进行teacher-led和student-led filtering,从这些item候选中分别选择teacher和student关心的item进行后续蒸馏教学(DRL-Rec分别选择了teacher和student模型评分高的item作为待蒸馏的item,因为这些item的信息量和对于模型预测的影响最大)。这一个模块能够帮助模型从百万item候选中选择信息量大的item进行蒸馏,大幅增加了知识蒸馏数据增强的效率。
(3)在置信度引导的蒸馏模块,我们基于Hint loss和list-wise KL divergence loss,将teacher的知识迁移到student上,并将teacher的预测准确度作为蒸馏置信度,使得student能从teacher更擅长的课程上学到更多。
我们总结了DRL-Rec模型的优点如下:(1)探索/过滤模块能够智能地选择信息量大的item进行探索,解决了teacher的“what to teach”的问题;(2)置信度引导的蒸馏模块通过置信度,解决了student的“how much to learn”的问题。
DRL-Rec在离线准确率和模型效率上都有了显著提升。另外,我们还进行了消融实验,验证模块的有效性。
我们总结了模型的贡献点如下:
■ 我们提出了一个全新的DRL-Rec框架,关注推荐强化学习模型的蒸馏问题。据我们所知,这是第一个在推荐系统中考虑强化学习模型之间的知识蒸馏的方法;
■ 我们提出了一个探索/过滤模块,通过双向主导的学习机制,从teacher和student两个角度预先筛选高信息量的item进行蒸馏,解决了teacher在百万item候选中的“what to teach”的问题;
■ 我们还提出一个置信度引导的蒸馏模块,在list-wise推荐定制的list-wise KL divergence loss和Hint loss上引入置信度的概念,帮助student更关注teacher更擅长的、把握更大的知识;
■ DRL-Rec模型在离线和线上都取得了显著的效果和效率提升,并已部署于微信看一看推荐系统,服务千万用户。
具体模型
▍2.1模型基本概念
我们先介绍DRL-Rec中的关键概念如下。其中,对于一个user,我们将其未真实交互过的、经过探索/过滤模块过滤后,输给置信度引导的蒸馏模块进行蒸馏的item称为filtered exploration candidate。这些filtered exploration candidate将会作为有真实标签的user-item样例的弱监督补充信息,共同进行蒸馏。

▍2.2模型整体结构
图2给出了DRL-Rec模型的整体流程。
(1)探索/过滤模块在百万级候选item中选择一个item子集(可以看作一个小召回模块,主要是为了提高离线训练效率),然后teacher RL和student RL模型对这些item进行评分(user侧可以提前计算好,计算复杂度不高)。这一步可以看作是一种离线的RL exploration。
(2)Teacher-led lessons和Student-led lessons分别选择teacher/student模型关注的想要学习的item,作为待蒸馏的item。这一步可以看作蒸馏前的过滤,去除不相关的可能干扰蒸馏的“杂质”。
(3)在蒸馏模块,我们针对list-wise推荐,设计了基于Q value list的list-wise KL divergence loss进行蒸馏,并辅助以Hint loss进行embedding级别的蒸馏。最终,轻量级的student模型被部署于线上推荐系统。
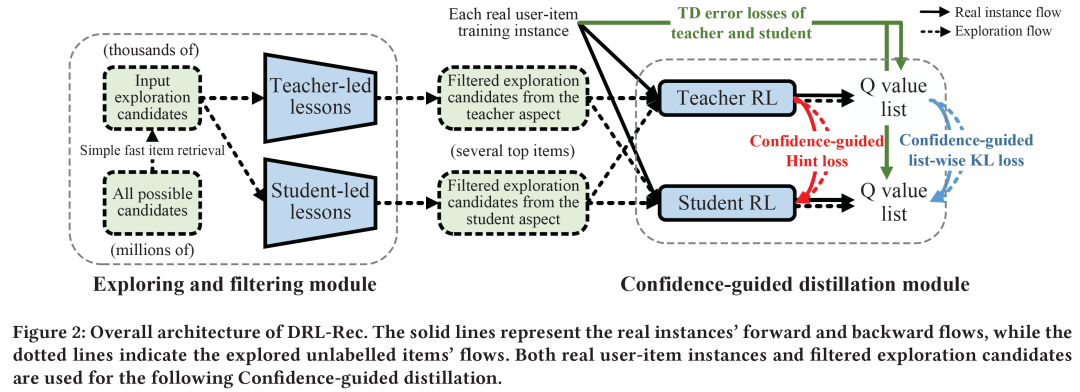
图2:DRL-Rec整体结构
▍2.3老师/学生模块
在老师/学生模块,我们使用了DDQN这种value-based RL进行训练,因为它比AC结构在蒸馏下表现更加稳定。

具体网络上,我们参考HRL-Rec强化学习推荐模型(Xie et al. (2021))的网络结构,构建了相同网络结构、不同向量维度的teacher和student模型。在预测user的list中的t位置的item时,模型首先使用Transformer分别进行前面t-1位置已经预测出的item的特征交互,然后使用GRU串联t-1个item的特征,得到当前state的表示:

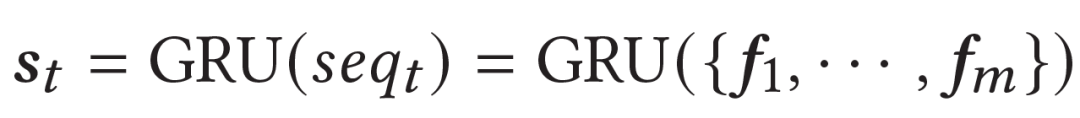
然后,模型联合state和action(即预测的item)的表示,基于MLP进行交互,得到q value的预测值:
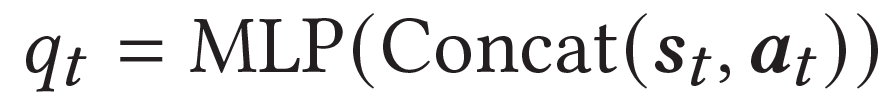
模型基于传统的TD error进行学习,不同位置的Q value有:
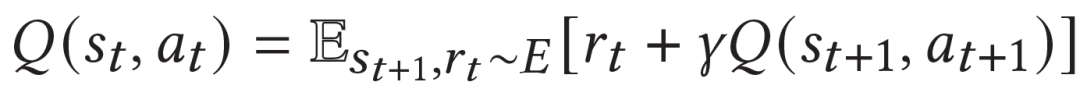
最后,teacher和student分别的训练目标如下:
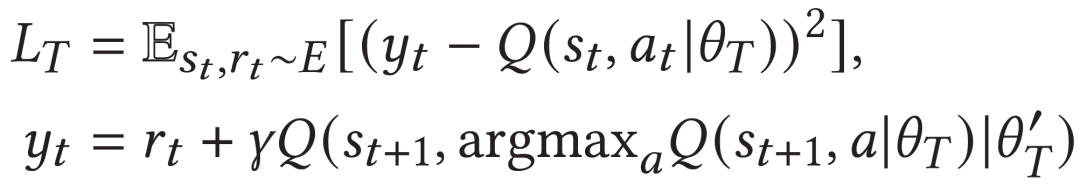
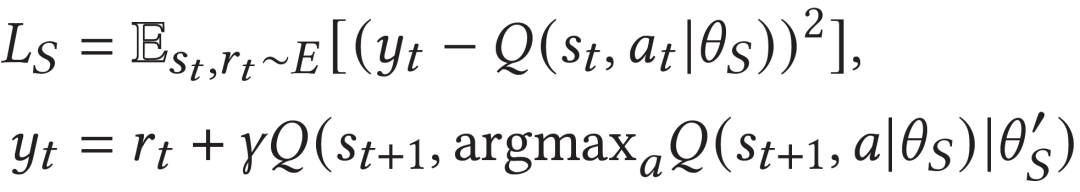
模型的整体网络结构如下图。
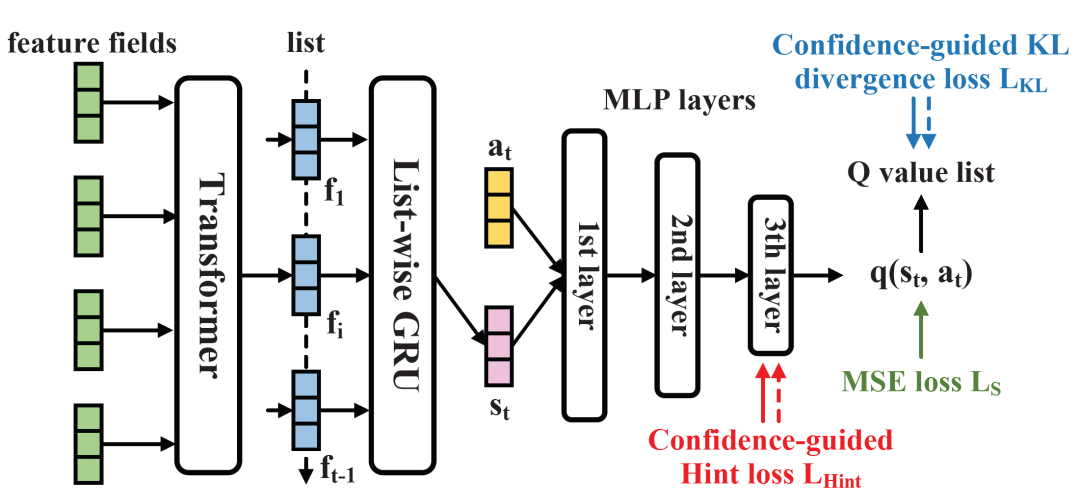
图3:学生模型的网络结构和训练目标
▍2.4探索/过滤模块
如前所述,我们认为和传统知识蒸馏在分类任务(约几百级)上不同,如果在推荐中简单使用user在所有可能未曝光item上(百万级)的得分分布进行蒸馏,引入的噪声可能远大于有效信息量。同时,我们也没有足够的算力穷尽所有user-item空间。因此,推荐强化学习蒸馏需要一个探索和过滤的机制,选择高信息量的无标签物品,作为有标签物品的补充进行蒸馏学习。具体地,探索/过滤模块会先选择一个千级别的item子集作为候选(可以通过简单召回模型选择,或者随机选择)。这个子集数量如果过少,则会影响过滤模块找到真正高信息量item的概率。然后,我们让teacher和student模型对所有item候选在当前state下进行打分(state提前计算好,因此训练时间可控)。过滤模块则根据teacher和student的评分选择高信息量的item,作为后续蒸馏的一部分输入。
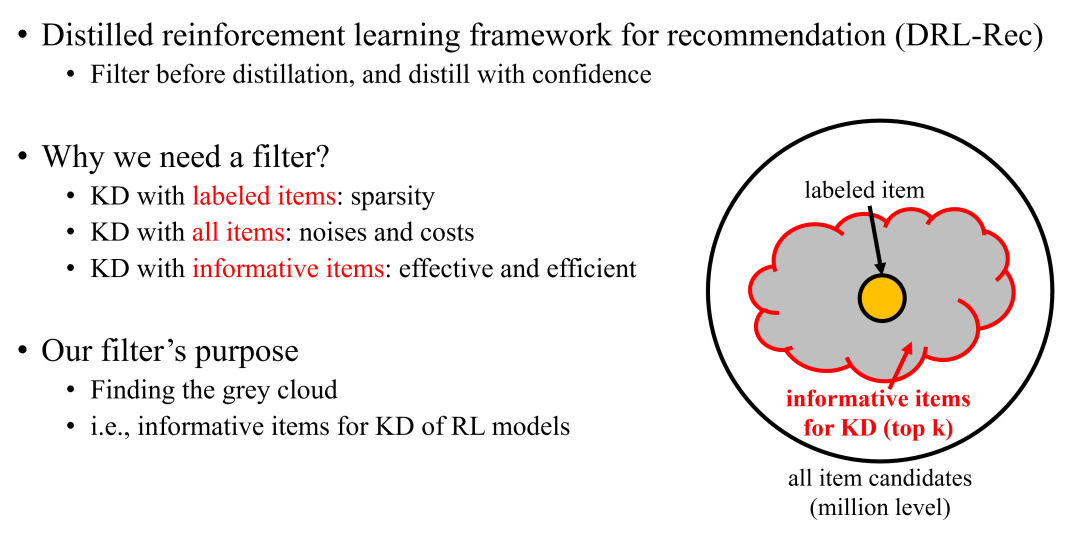
在具体的过滤阶段,DRL-Rec直接选择了teacher和student打分最高的top-k item作为蒸馏的item。这是因为在某个位置,推荐模型实际只关心评分最高的item。因此,选择上面两种top-k item进入蒸馏,能够直接提高student对于teacher的top-k item的评分,同时降低最可能是干扰项的student top-k item的评分,针对性地优化student的推荐目标。这种简单的策略起到了很好的迁移teacher知识的效果。当然,另外的过滤策略(例如基于teacher-student意见分歧程度的策略)也可以灵活部署。
▍2.5基于置信度的蒸馏模块
我们认为当teacher预测的q value和真实q value越接近,则此时teacher对此state-action的置信度更高。这个直观的置信度公式如下:
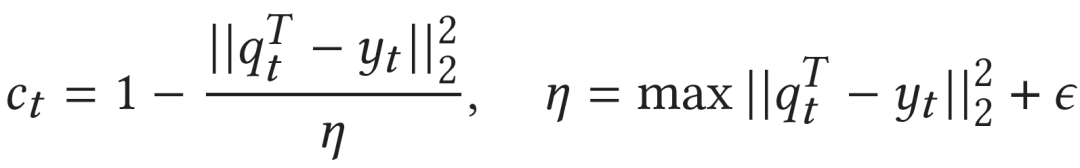
对于探索/过滤模块提供的无标签的item,我们使用了一个均值置信度。
我们联合使用了两种方式进行蒸馏。我们首先基于list-wise推荐,对teacher和student的Q value list进行蒸馏,公式如下:
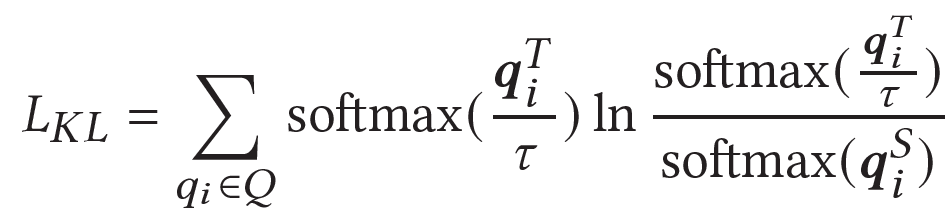
置信度用于各个q值BP到student模型时learning rate的权值(teacher进行了梯度block),使得student在不同位置不同置信度下能够进行不同权值的更新。另外,我们还设计了置信度引导的Hint loss,如下:
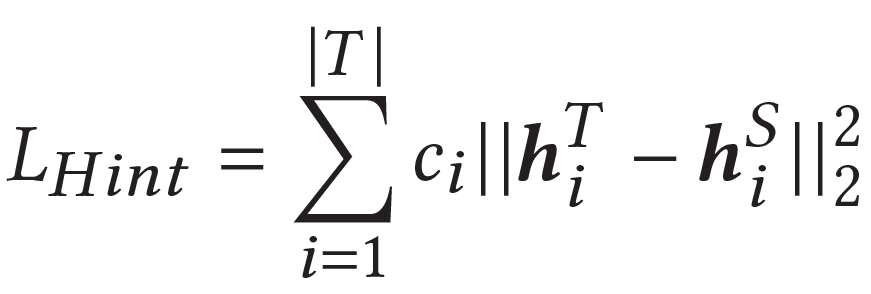
最终模型loss包括teacher/student RL loss和两个蒸馏loss:
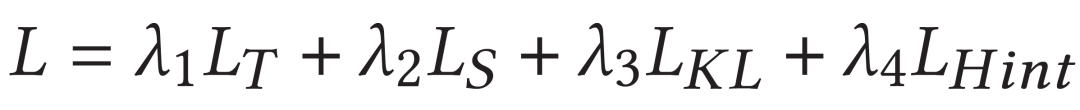
实验结果
我们进行了离线和线上实验。我们压缩了student模型的整体embedding size,模型大小和线上耗时是原teacher模型的49.7%和76.7%。模型的具体离线AUC结果如图4。我们发现蒸馏后的DRL-Rec在50%模型大小下,准确率有显著的提升。
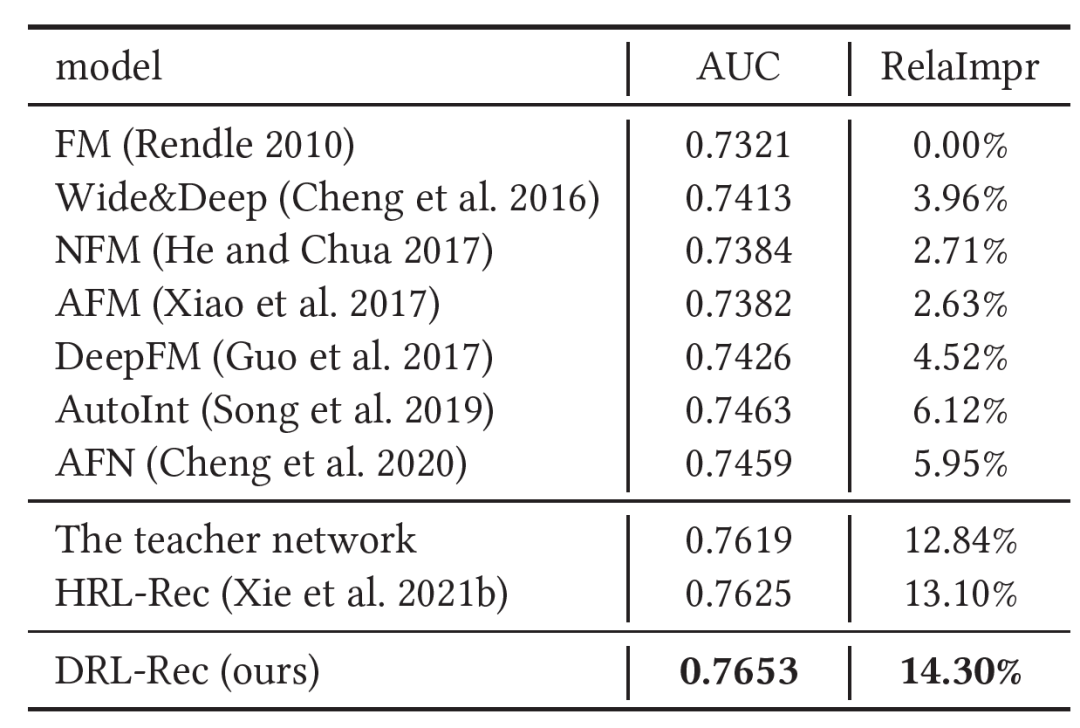
图4:DRL-Rec离线实验结果
我们还在线上进行了A/B实验,结果如图5。模型在点击相关指标上有显著提升。

图5:DRL-Rec线上实验结果
图6的消融实验也验证了模型的各个模块的有效性。
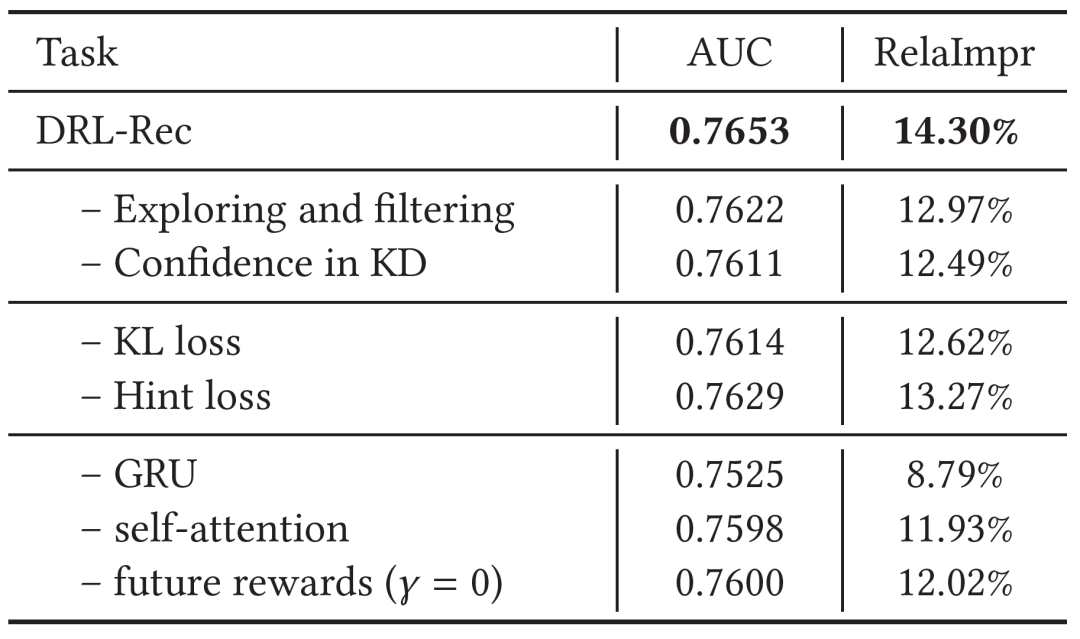
图6:DRL-Rec消融实验结果
最后,我们测试了DRL-Rec在不同压缩率下和在不同探索/过滤模块输出item数量下的结果。我们发现DRL-Rec在50%以上压缩率时都能保持AUC显著提升的效果。另外,探索/过滤模块输出item数量为3时效果最佳,这说明了探索/过滤模块对于噪声控制的重要性。
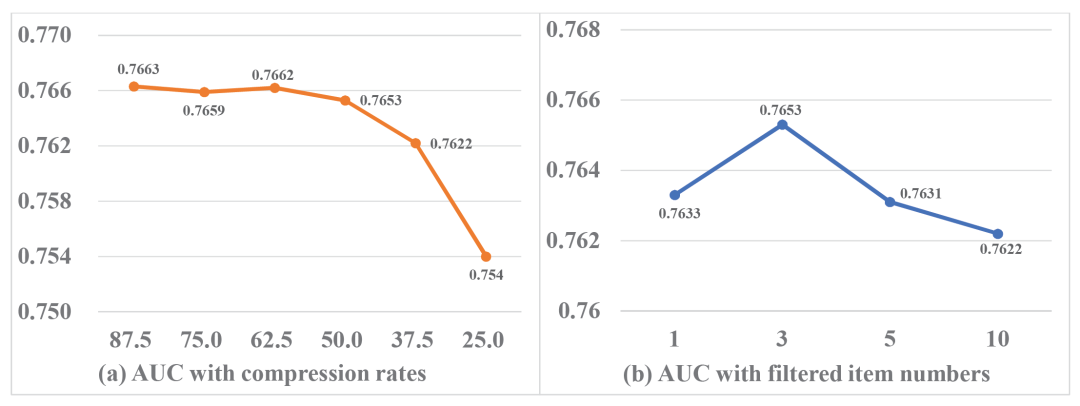
图7:(a)DRL-Rec在不同压缩率下的结果;
(b)DRL-Rec在不同探索/过滤模块输出item数量下的结果。
总结
在这篇工作中,我们探索了真实推荐系统中强化学习模型的知识蒸馏,提出了一个探索/过滤机制,保证模型选择高信息量的item进行蒸馏,同时通过置信度引导的两种蒸馏目标,从teacher置信度更高的样例上进行更多学习。DRL-Rec在离线和线上都获得了显著的准确率/效率提升,具有很大的工业使用价值。DRL-Rec模型目前已经部署于微信看一看系统,服务千万用户。在未来,我们会进一步研究探索/过滤机制与online exploration,RL bandit等的联动可能,并尝试探索联合模型。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。



