微信看一看系统中如何基于元学习预热冷启动?丨SIGIR-2021

导语
近年来,向量嵌入(embedding)的技术在推荐系统领域取得了广泛的应用。然而,向量嵌入技术需要大量训练数据,而现实中的长尾分布会导致严重的冷启动问题。对于只有极少数交互的冷启动物品,模型往往很难训练一个合理的值得信赖的物品ID embedding,因此也难以被推荐系统分发,形成负反馈。
这个问题被称作冷启动ID embedding问题。这篇文章针对冷启动ID embedding提出了一种基于元学习的方法,通过meta scaling and shifting技术,探索并解决了推荐系统中如何预热冷启动物品ID embedding的问题。

背景介绍
随着个性化线上app的增长,推荐系统被线上服务广泛采用,比如电商、线上新闻等等。传统的协同过滤的方法可以学习用户的兴趣偏好,并且在推荐系统上取得了显著的效果。
最近的研究表示深度神经网络可以进一步提升推荐系统的效果。这些深度推荐模型通常采用向量嵌入(embedding)的技术。这些模型可以分为两个部分,向量嵌入层和深度模型。向量嵌入层通常将原始特征转化为低维向量表示。
其中,物品的ID的向量表示称作ID embedding。每个物品都有一个独特的ID,因此ID embedding也是物品独一无二的向量表示。一个好的ID embedding可以大幅度提升推荐的效果。深度推荐模型将所有特征转化为向量后送入深度模块,给出最终的预测。
然而这些深度推荐模型需要大量数据,并且面临严重的冷启动问题。具体来说,冷启动的物品通常只有少量的交互数据,因此很难学到一个合理的物品ID embedding,我们把这样的表示称作冷启动ID embedding。由于冷启动ID embedding的问题,导致推荐系统很难将冷启动物品推荐给合适的用户。我们分析冷启动ID embedding主要存在两个问题:
1、冷启动ID embedding和深度模型之间存在着gap。在推荐系统中,存在一个众所周知的现象,少量热门物品占据了大量交互样本,而大量冷启动物品只有少量交互数据。深度模型是在所有数据上进行训练,因此这个模型会学到大量来自热门物品的知识。而冷启动ID embedding仅仅在特定物品的交互数据上训练,因此冷启动ID embedding很难拟合这个深度模型。所以针对冷启动物品如何加速模型的拟合是至关重要的(fast adaptation)。
2、冷启动物品ID embedding会受到噪声的严重影响。在推荐系统中,随时都在出现错误的交互,比如错误点击。而物品ID embedding完全取决于该物品的交互数据。而冷启动物品通常只有很少的交互数据,因此很小的噪声也会对冷启动物品ID embedding造成严重的影响。
现在已经有一些尝试解决冷启动问题的方法。DropoutNet[1]将dropout用于控制推荐模型的输入,随机扔掉用户embedding或者物品embedding来模拟冷启动,并且使用所有交互过的用户表示来取代物品ID embedding。MetaEmb[2]学习一个生成器来使用物品特征来生成物品的初始化ID embedding。MeLU[3]学习一个全局参数来初始化个性化推荐模型,基于该初始化参数,在特定用户的交互数据上进行更新,得到个性化的模型。然而这些方法都没有同时考虑上述两个挑战。
为了解决上述的两个挑战,我们采用了两个关键点:(1)最近一些研究表明cold和warm的embedding特征空间不同[4],因此我们希望将冷启动ID embedding转换到warm特征空间中。(2)为了减缓噪声的影响,我们使用全局交互的用户表示来加强冷启动ID embedding。
在这篇文章中,我们将冷启动问题划分为两个阶段,cold-start阶段和warm-up阶段,cold-start阶段表示完全没有样本的情况,而warm-up阶段表示有少量样本的情况。
为了解决这两个阶段的冷启动问题,我们提出了Meta Warm Up Framework(MWUF),该框架可以用于不同的深度推荐模型。该框架包含一种公共初始化ID embedding以及两个meta networks。对于任何新来的物品,我们使用现有的物品embedding的均值来作为初始化。
另外,Meta Scaling Network使用物品的特征作为输入,生成一个定制化的拉伸函数将冷启动ID embedding转化为warmer embedding。Meta Shifting Network使用全局的交互过的用户作为输入,来生成一个偏移函数,来加强物品表示。
模型方法
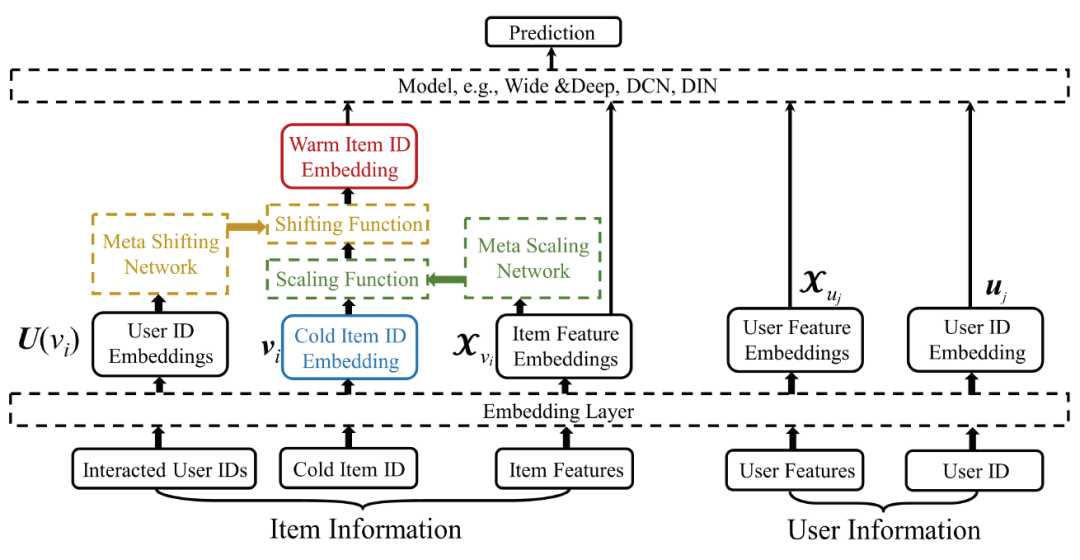
整体框架如上所示,深度模型的输入包含4个部分,物品ID embedding,物品其他特征embedding,用户ID embedding,用户其他特征embedding:
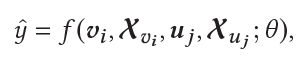
Common Initial Embeddings: 我们提出了一种公共初始化embedding,使用现有的所有物品的ID embedding均值作为新加入的物品的初始化embedding。
Meta Scaling Network:我们希望将冷启动物品ID embedding转换到一个更好的特征空间,能更好地拟合深度模型。对于每一个物品,冷启动ID embedding和warm ID embedding之间存在一定的联系,我们认为相似的物品,这个联系也应该相似,因此Meta Scaling Network以物品的其他特征做为输入,输出一个拉伸函数:

Meta Shifting Network: 所有交互过的用户均值可以有效的减轻异常用户的影响,因此Meta Shifting Network以交互过的用户的均值表示作为输入,输出一个偏移函数:
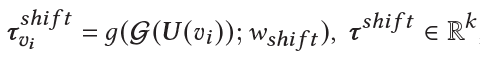
最后转换后的物品ID embedding表示为:
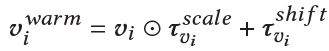
整个训练流程分为两个阶段,第一个阶段训练推荐模型,第二个阶段训练两个meta network,流程如下所示:

实验
我们在三个数据集上进行了实验:
MovieLens-1M: 该数据集包含一百万条电影打分数据,我们将评分大于3的转换为标签1,评分小于等于3的为标签0.
Taobao Display Ad Click: 改数据包含1,114,000个用户在淘宝网上8天的两千六百万广告点击记录。
CIKM2019ECommAI: 这是一个电商推荐数据,用于CIKM2019挑战赛。
我们比较了三类方法,包括常见的协同过滤方法FM、Wide & Deep、PNN、DCN、AFN。冷启动方法DropoutNet、MeLU、MetaEmb。以及序列推荐的方法GRU4Rec、DIN(我们把序列模块用到item侧)。并且我们把冷启动根据样本量分为了四个阶段。实验结果如下所示,可以看到我们的方法在不同数据集,不同设定下都取得了最优的结果。
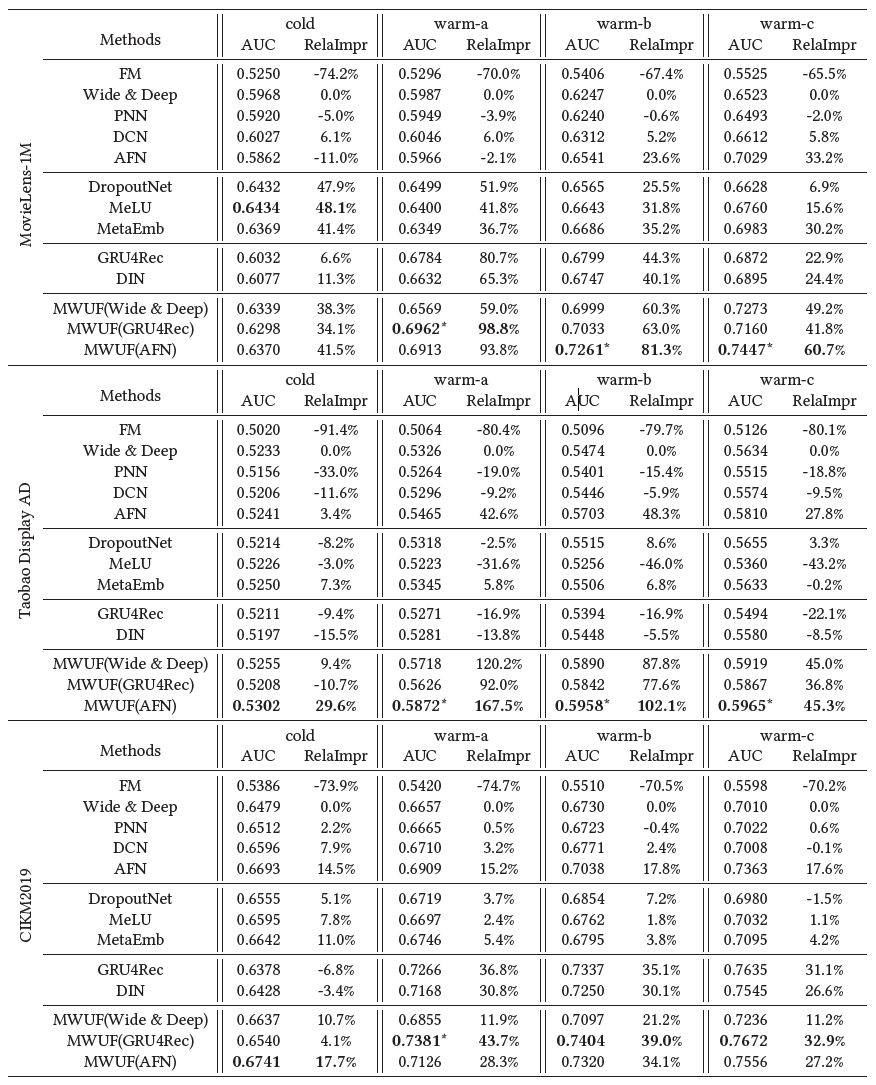
另外,我们的方法和MetaEmb都是通用的方法,可以用于不同的深度推荐模型。因此,我们把这两个方法用不同的模型作为base model进行实验,得到结果如下,可以看到在不同任务下,我们的方法都是优于MetaEmb的。实验证明了我们方法的通用性和有效性。
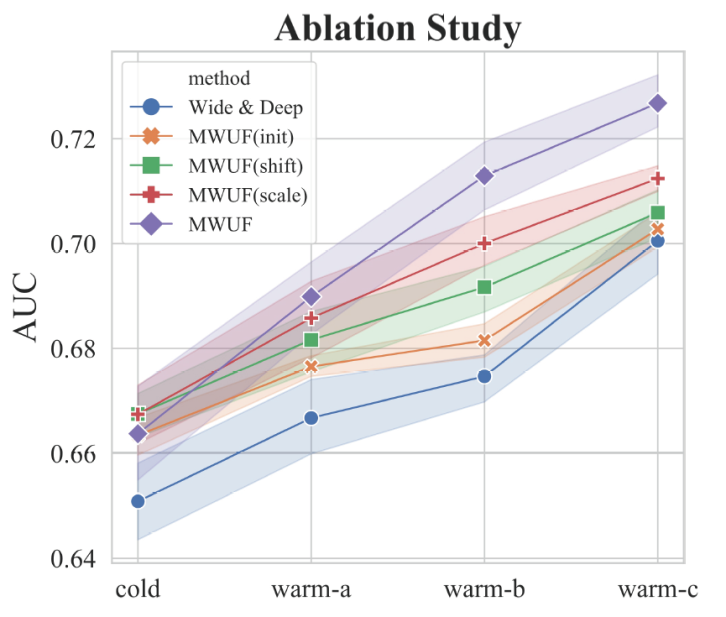
最后,我们做了消融实验,验证了我们提出的每个部分都是有用的。
总结
这篇文章我们研究了推荐冷启动中的item预热问题。我们发现冷启动ID embedding和深度模型之间存在着gap,并且冷启动ID embedding会受到噪声的影响。
因此我们提出了一种通用普适的冷启动item embedding预热初始化的方法,同时提出了两个meta networks来将冷启动ID embedding转换到更好的特征空间。多个数据集上的实验证明我们的方法是一种高效且通用的方法,值得在线上冷启动系统中进行尝试。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。




