【微信@CIKM2021 】 强化学习推荐模型的知识蒸馏探索之路

强化学习(Reinforcement learning, RL)已经在真实世界的推荐系统中被广为验证。然而,基于强化学习的推荐算法常常会带来巨大的内存和时间成本。知识蒸馏(Knowledge distillation, KD)则是一种常见的有效压缩模型同时尽量保持模型有效性的方法。但是,推荐中的强化学习模型往往需要在极度稀疏的用户-物品空间中进行大规模的探索(RL exploration),而这增加了强化学习推荐模型进行蒸馏的难度。
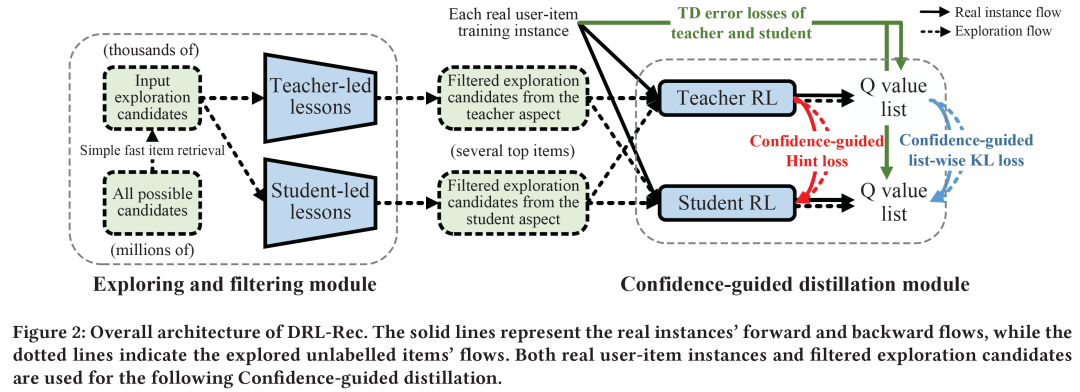
在强化学习蒸馏中,老师(teacher)需要教给学生(student)哪些课程(例如老师对于有标签/无标签的user-item对的评分),以及学生需要从老师的课程中学习多少(即每个蒸馏样例的学习权重),需要被精细地规划和设计。在这个工作中,我们提出了一个全新的蒸馏强化学习推荐模型(Distilled reinforcement learning framework for recommendation, DRL-Rec),希望能够在压缩模型的基础上保持(甚至提升)模型的效果。
具体地,我们在模型蒸馏前加入一个探索/过滤模块(Exploring and filtering module),从老师和学生两个角度判断蒸馏中什么样的信息应该从老师传给学生。我们还提出一个置信度引导的蒸馏(Confidence-guided distillation),在list-wise KL divergence loss和Hint loss两种蒸馏目标学习中加入置信度的权值,以指导学生从老师更加擅长的课程中学习更多。目前,DRL-Rec已经部署于看一看推荐系统,服务千万用户。
论文链接:
https://dl.acm.org/doi/abs/10.1145/3459637.3481917
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DRLRE” 就可以获取《【微信@CIKM2021 】 强化学习推荐模型的知识蒸馏探索之路》专知下载链接






