微信看一看对抗特征转移简述丨KDD-2021

导语
互联网平台(如Google,WeChat等)往往有不同的推荐场景,需要为用户提供不同种类的物品(如文章、视频、小程序等)以满足用户多样化的需求。多领域推荐(Multi-domain recommendation, (MDR))任务需要基于用户在多个领域上的行为和特征,同时优化多个领域的推荐效果,其关键之处在于如何抓住不同领域中的关于目标领域的有效特征。
针对多领域推荐任务,我们提出了一个全新的Adversarial Feature Translation (AFT)模型,基于生成对抗网络(GAN)学习不同领域之间的特征转移(feature translation)。具体地,在multi-domain generator中,我们提出了一个domain-specific masked encoder,用以强调跨领域的特征交互建模。
然后,我们基于transformer层以及domain-specific attention层聚合这些跨领域交互后的特征,学习用户在目标领域下的表示,以生成虚假的物品候选(fake clicked items)输入到判别器中。
在multi-domain discriminator中,我们受到知识表示学习(KRL)中的基于三元组的建模方法(如TransE)的启发,构建了一个两阶段特征转移(two-step feature translation)模型,对领域、物品和用户不同粒度/不同领域的偏好进行可解释的建模。
在实验中,我们在Netflix和微信多领域推荐数据集上进行了测试,模型在离线和在线实验的多个结果上都获得了显著的提升。我们也进行了充分的消融实验和模型分析,以验证模型各个模块的有效性。AFT模型已经部署于微信看一看的多领域推荐场景,影响千万用户。
模型背景与简介
推荐系统已经融入我们生活的方方面面,为我们提供个性化的信息获取及娱乐。在马太效应的影响下,Google、WeChat、Twitter这样的平台应运而生。它们往往拥有着多种多样的(推荐)服务,能够为用户推荐多样化的物品(如文章、视频、小程序等),满足用户需求。
用户在不同推荐服务上的行为(在用户允许下)会基于用户的共享账号产生关联。这些多领域用户行为能够在目标领域行为之外提供额外信息,从而帮助推荐系统更加全面地了解用户,辅助提升各个领域的推荐效果。
多领域推荐(Multi-domain recommendation, (MDR))任务需要基于用户在多个领域上的行为和特征,同时优化多个领域的推荐效果,其关键之处在于如何抓住不同领域中的目标领域特化的特征。一个直观的方法是将用户的多领域行为当作额外的输入特征,直接输入给ranking模型。
但是这种方法没有针对领域间的特征交互进行优化建模。近期,有一些工作基于多任务学习(Multi-task learning, MTL)的思路,将一个领域的推荐当作一个任务进行处理,取得了不错的效果。
然而,多领域推荐的效果仍然严重地受限于其固有的稀疏性问题。多领域推荐的稀疏性体现在以下两个方面:(1)user-item点击行为的稀疏性(这个是推荐系统本身拥有的稀疏性问题);(2)跨领域特征交互的稀疏性(这个是多领域推荐特有的稀疏性问题)。
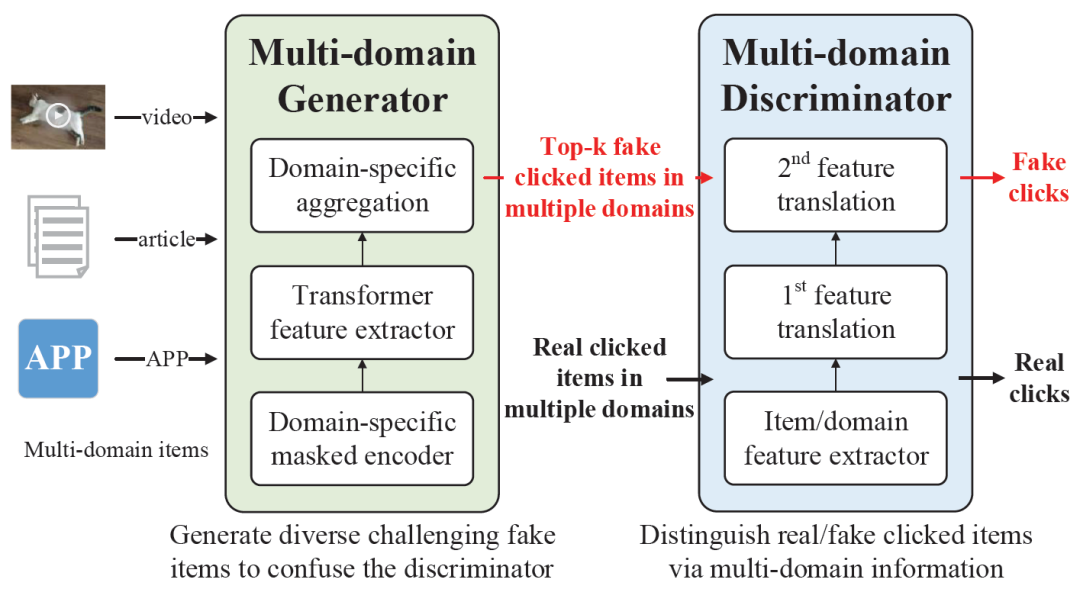
图1:多领域推荐及AFT模型的框架图
为了解决以上挑战,使模型能够同时提升多领域上的推荐效果,我们提出了一个Adversarial Feature Translation (AFT)模型。如图1所示,AFT提出了domain-specific masked encoder以及two-step feature translation,着重关注跨领域、多粒度的特征交互的建模。
具体地,在生成器(generator)部分,我们首先设计了一个domain-specific masked encoder,通过mask掉目标领域的历史行为特征(historical behaviors),加强其它领域历史行为特征和目标领域点击行为之间的交互特征权重。它驱使着AFT模型学习如何基于其他领域特征进行目标领域上的推荐。
Transformer层和Domain-specific attention则用来抽取目标领域相关的用户特征,用于生成top-k虚假点击的物品(fake clicked items)。这些fake clicked items将被输入判别器,迷惑判别器的判断,在对抗中相互提升所有领域的推荐能力。
在判别器(discriminator)中,我们受到知识表示学习模型(KRL)的启发,希望能够显式地对用户、物品和领域进行建模。
具体地,我们首先使用transformer,从多领域特征中分别抽取用户的细粒度item和粗粒度domain的偏好特征,标记为user item-level preference和user domain-level preference。随后,我们构造了一个三元组(user item-level preference, user domain-level preference, user general preference),进行第一次特征转移,学习用户通用领域的偏好特征(user general preference)。
这里的物理含义是(以KRL中的经典模型TransE为例),对于(Hamlet, writer, Shakespeare)三元组关系,有Hamlet+writer=Shakespeare。
那么我们也同样认为,在多领域推荐中,用户不同粒度的偏好相加(item-level preference+ domain-level preference),约等于用户通用领域的偏好(user general preference)。
在得到user general preference后,我们又构建了第二个三元组(user general preference, target domain information, user domain-specific preference),并进行第二次特征转移。这个三元组的物理含义是,用户的通用领域偏好+目标领域的特征=用户在目标领域的偏好(user domain-specific preference)。
我们基于一个成熟的知识表示学习模型ConvE进行了两层特征转移(two-step feature translation),得到了用户在目标领域上的表示用于推荐。
AFT模型的优势在于:(1)AFT的GAN框架在domain-specific masked encoder的帮助下提供了充足且高质量的多领域推荐负例,缓解了数据稀疏和过拟合的问题;(2)生成器中的domain-specific masked encoder能够加强模型的跨领域特征交互,而这正是多领域推荐的核心要素;(3)判别器中的two-step feature translation提供了一种大胆的、显式化可解释的建模用户、物品和领域的方式,对多领域推荐提供了更深层次的理解。
在实验中,我们将AFT和多个有竞争力的baseline模型进行了离线和线上对比。实验结果显示,我们的模型在多个领域上全面显著地超出所有baseline。我们还进行了详尽的消融实验和模型分析实验,用以加深我们对AFT各个模块和参数的理解。AFT模型已经部署于微信看一看的多领域推荐场景,服务千万用户。我们这篇工作的贡献点可以总结如下:
具体模型
如前所述,模型基于GAN训练框架,主要分为生成器和判别器两个部分。如图2,生成器输入用户多领域行为特征,并基于domain-specific masked encoder、Transformer层和Domain-specific attention,抽取目标领域相关的用户特征,用于生成top-k虚假点击的物品(fake clicked items)。判别器则基于两阶段特征转移,获得用户向量,然后预测真实/虚假点击物品的得分。
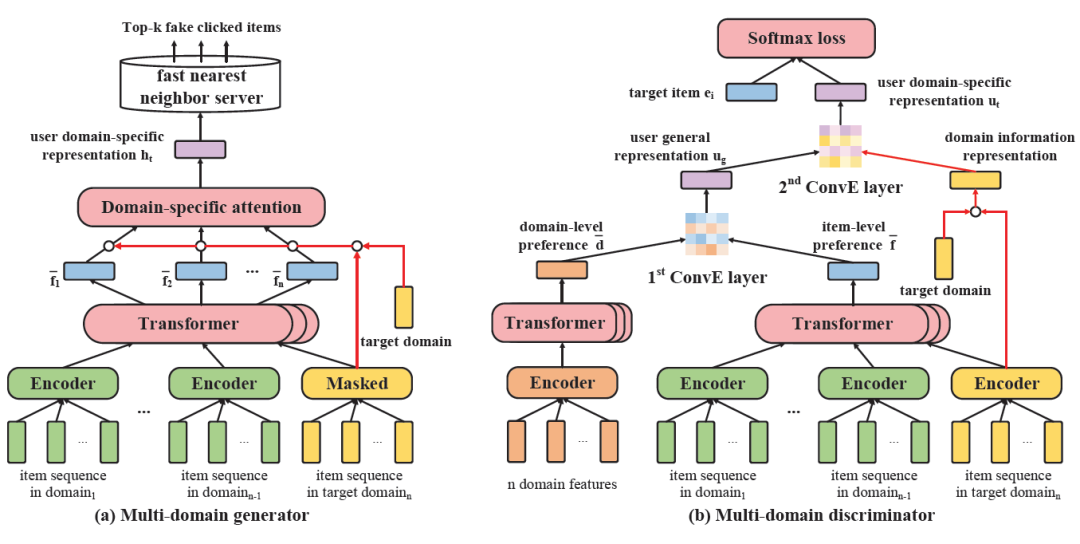
图2:AFT具体模型,包括(a)多领域生成器和(b)多领域判别器
▍2.1 多领域生成器
多领域生成器旨在为用户生成每个领域上的fake clicked items,其输入是某个用户在所有n个领域上的行为序列X={X_1, …, X_n},其中X_t是第t个领域上的行为序列特征矩阵。
不失一般性,我们假设生成器正在生成目标领域d_t上用户可能点击的物品。我们首先使用domain-specific masked encoder处理目标领域序列X_t,随机对目标领域d_t中的行为进行mask,如下所示:
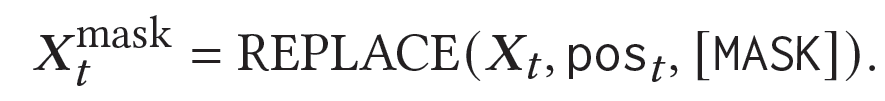
公式表示序列中pos_t这些位置上的行为被[mask]的token替代。这样,domain-specific masked encoder强制生成器在生成目标领域的候选物品时,更多地考虑其它领域的用户行为。这样虽然会导致生成器更难生成最合适的fake clicked items(因为丢失了关键的目标领域的历史行为),但是也会加强跨领域历史行为和点击的特征交互,有助于多领域推荐,特别是稀疏行为的领域上的推荐效果,瑕不掩瑜。
随后,我们使用average pooling分别聚合各个领域上(mask后)的行为序列,然后基于Transformer和domain-specific attention得到用户在目标领域上的表示h_t如下:
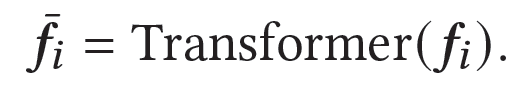
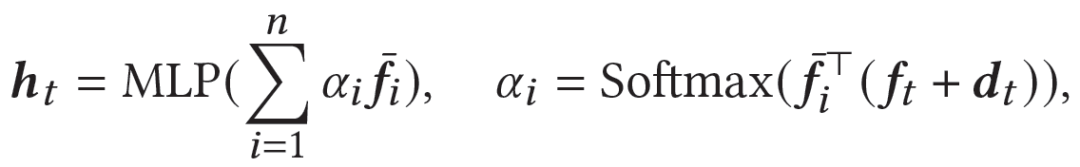
对每个候选物品e_i,生成器计算的点击概率p为:

我们基于生成概率p选择目标领域上的top k的近邻物品(剔除训练集中的真实正例),作为生成器生成的负例输入判别器。
▍2.2 多领域判别器
在判别器中,我们首先基于Transformer特征抽取器,获得用户在细粒度的具体行为(item)上和在粗粒度的领域(domain)上的特征表示:
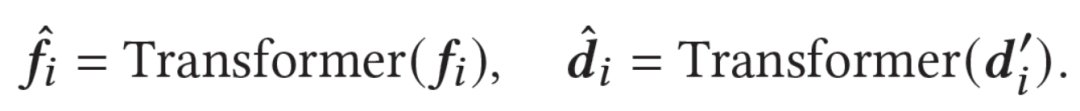
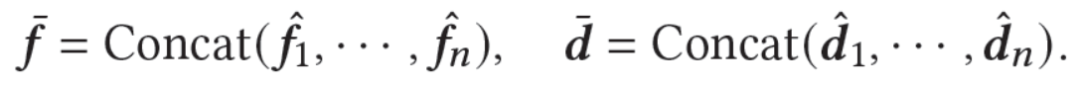
然后,我们基于知识表示学习中三元组的学习范式,设计了一个两阶段的特征转移:先基于用户在多领域的细粒度和粗粒度上的偏好,得到用户整体偏好;然后基于用户整体偏好和目标领域信息,得到用户在目标领域上的偏好。
传统的知识表示学习方法(如TransE)显式建模三元组关系。对于(Hamlet, writer, Shakespeare)这个三元组关系,TransE认为:Hamlet+writer=Shakespeare。于是,我们也认为用户细粒度的偏好加上用于粗粒度的偏好,应该等于用户通用领域上的全局偏好(user general preference)。我们基于ConvE模型(因为他能够挖掘element-wise的特征交互),对于三元组(e_h, r, e_t),有:

类似地,在第一次特征转移中,我们构造了一个三元组(user item-level preference, user domain-level preference, user general preference)。我们计算用户通用领域上的全局偏好u_g如下:
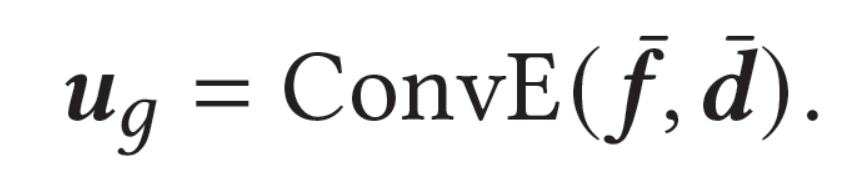
在得到user general preference后,我们又构建了第二个三元组(user general preference, target domain information, user domain-specific preference),并进行第二次特征转移。这个三元组的物理含义是,用户的通用领域偏好加上目标领域的特征,约等于用户在目标领域的偏好(user domain-specific preference)。我们有:

其中目标领域特征综合考虑了领域向量和行为向量。与生成器类似,我们基于用户在d_t的特征表示u_t,计算物品e_i的点击概率p如下:

▍2.3 模型优化
模型判别器的优化如下:
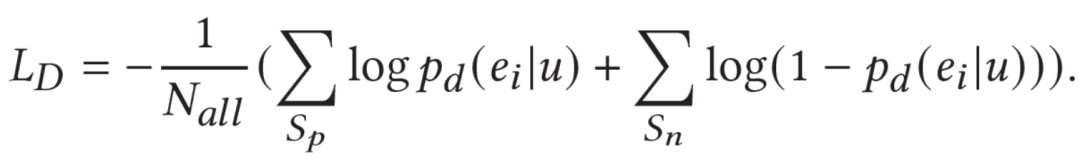
生成器则是基于REINFORCE强化学习进行优化:
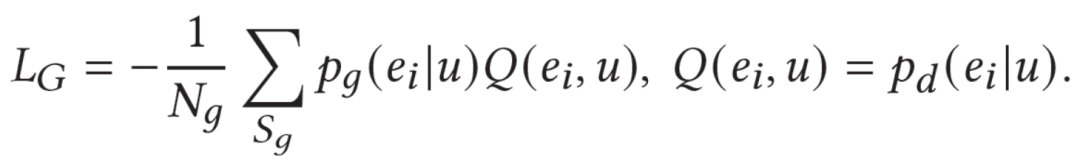
我们还提出一项MMD loss,希望生成器产生的物品和真实物品不要完全一致(会干扰判别器的训练)。具体如下:
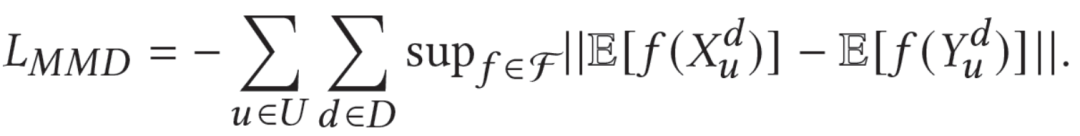
这种MMD loss是基于推荐系统的特质设计的。在推荐系统中,绝大多数物品其实并未被曝光,我们仅仅是假设所有未被用户点击的物品均为负例。和点击物品特别相似的fake clicked items也有很大概率同样被用户点击(例如不同自媒体号发表的同一主题的新闻/视频等),这也是推荐系统item-CF的本质。因此,我们选择加入了MMD loss,使得GAN能够生成更加多样化的、相似但又不完全一样的物品作为判别器的负例。
最后,我们综合三项loss获得最终AFT的loss,如下:
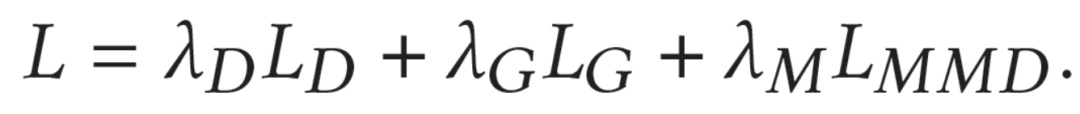
discriminator被部署于线上。更多模型和线上细节请参考论文Sec. 3和Sec. 4。
实验结果
我们在公开数据集和微信看一看数据集上进行了实验,在多领域推荐上获得了显著提升:
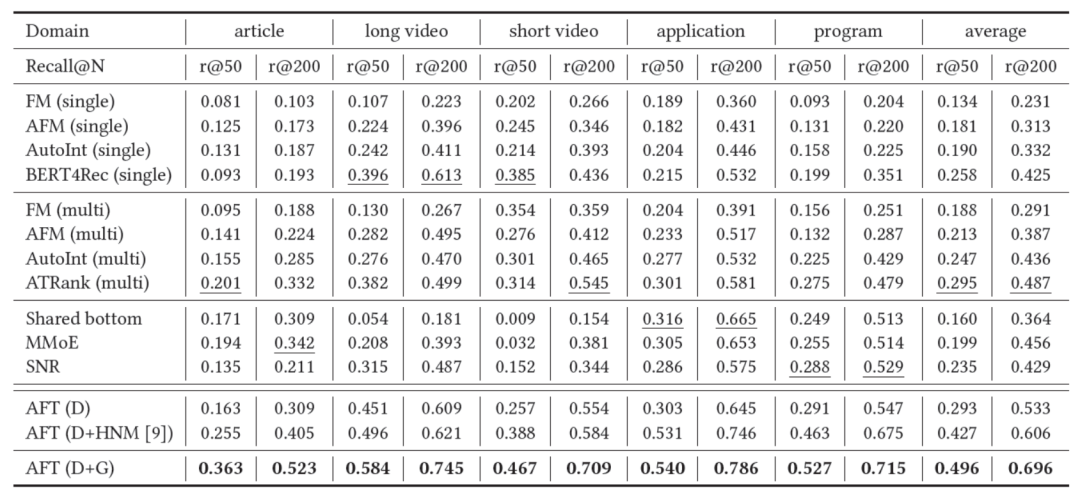
图3:AFT离线结果
另外,我们也在微信看一看多个线上推荐场景进行了A/B实验,获得了显著的提升:
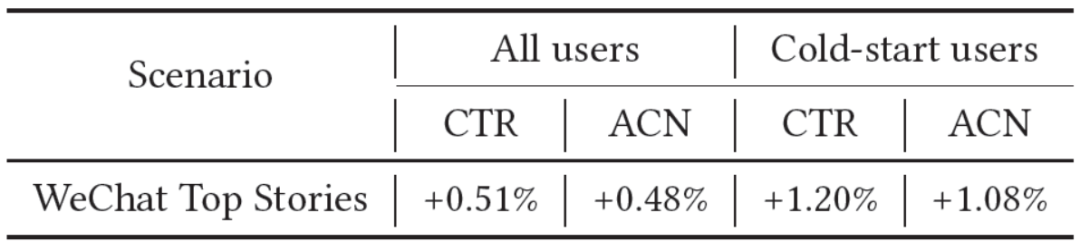
图4:AFT线上实验结果
消融实验也证明了模型各个模块的有效性:
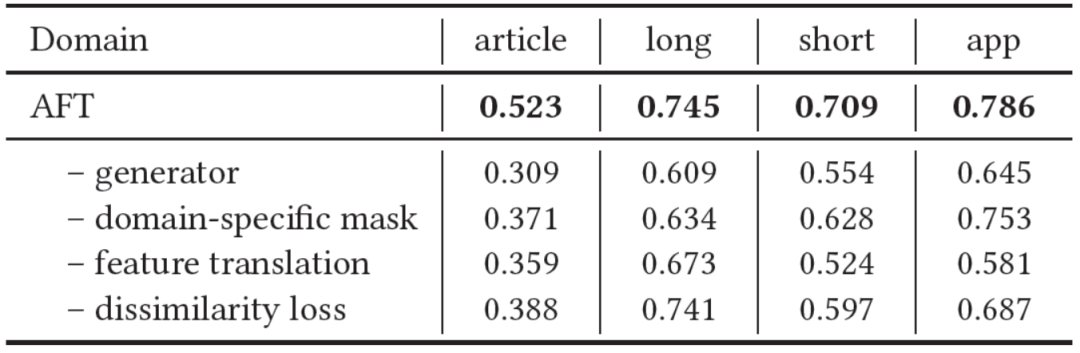
图5:AFT消融实验
最后,我们也做了详尽的模型参数分析,探索了不同mask ratio和fake clicked item number对模型效果的影响:
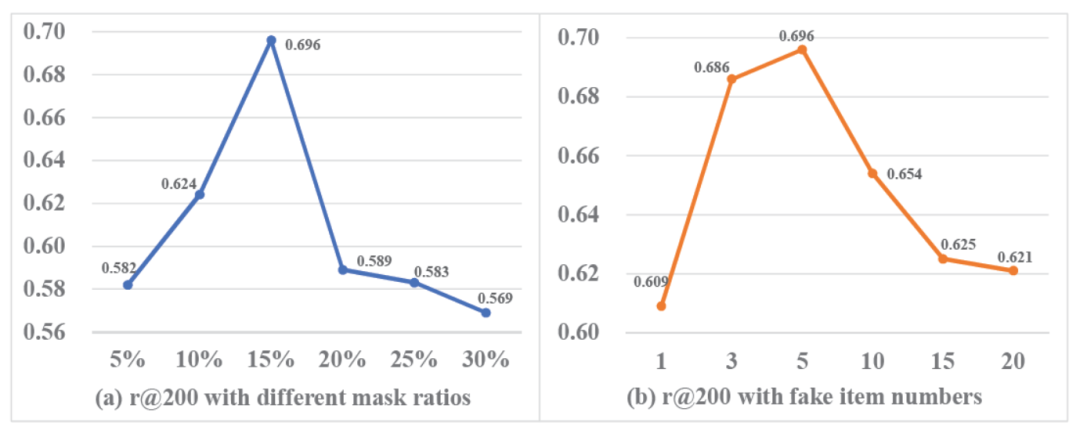
图6:AFT参数实验
总结
我们针对多领域推荐任务,提出了一个对抗特征转移的AFT模型。它基于domain-specific masked encoder加强了跨领域特征交互,也设计了一种two-step feature translation,能够显式可解释地对多领域下用户不同粒度的偏好、物品和领域进行建模。
AFT已部署于微信看一看多领域推荐模块中,影响千万用户。我们也十分看好基于对抗和知识表示学习的跨领域特征交互思路,未来会展开进一步探索。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。