关于微信看一看基于元学习的跨领域冷启动推荐丨SIGIR-2021

导语
冷启动问题是推荐系统中亟待解决的问题。跨领域推荐旨在利用一个信息丰富的辅助领域来帮助提升目标领域推荐系统的推荐效果,是一种有效地缓解冷启动问题的方法。在跨领域推荐的方法中,EMCDR是非常流行的一类方法。这类方法基于两个领域重叠的用户,学习一个从源领域到目标领域的映射函数。
但是这类方法面临着两个严重的问题:(1)这个映射函数很可能在重叠的用户上过拟合,导致泛化能力差;(2)这类方法使用一种映射导向的函数来学习,这样的学习方式对目标领域的用户表示的质量有要求,而事实上推荐系统学到的用户表示(特别是冷启动领域的用户表示)通常不够好。
这篇文章针对以上两个问题,提出了一种Transfer-Meta的基于元学习的框架来增强映射函数的泛化能力,另外,这个框架采用一种任务导向的优化方式。我们在豆瓣和亚马逊数据集上的实验结果验证了我们方法的有效性。

背景介绍
在这个信息爆炸的时代,如何高效地从大量数据中获得有效的信息变得尤为重要。推荐系统在缓解信息过载问题中起着重要的作用。然而,推荐系统在冷启动推荐上的效果并不令人满意,比如冷启动用户和冷启动物品。
跨领域推荐旨在利用一个信息丰富的辅助领域来帮助提升目标领域推荐系统的推荐效果。有一类跨领域推荐旨在提升目标领域推荐的整体效果[1,2,3,4]。另外一类跨领域推荐的方法旨在提升冷启动推荐的效果[5,6]。在这类方法中,EMCDR是一种广为使用的代表性方法。EMCDR将源领域和目标领域的用户偏好编码为向量,然后学习一个映射函数,该映射函数将源领域中的用户向量映射为目标领域上的用户向量,基于两个领域重叠的用户,使用MSE损失来进行学习。
然而,这类方法基于重叠的用户直接最小化映射后的对齐的源领域用户向量和目标领域用户向量的距离,往往存在如下问题:(1)通常两个领域重叠的用户只是一小部分用户。比如在亚马逊和豆瓣数据集中,源领域和目标领域中重叠的用户占比很低。因此,这样学习到的映射函数会在重叠用户上过拟合,降低模型的泛化能力;(2)使用映射导向的损失函数(MSE),对目标向量的质量有很高的要求。然而在冷启动场景中,目标向量的质量往往不尽如人意,这样会导致向量表示学习中被噪声影响。
因此,我们提出了一种Transfer-Meta的框架,将跨领域推荐分为两个阶段,transfer阶段和meta阶段:
transfer阶段:在EMCDR中,仅仅使用了重叠的用户来分别学习源领域和目标领域的模型。这里我们使用所有的数据来学习领域和目标领域的模型,然后将训练好的模型作为预训练模型,固定不动,再学习meta network。
meta阶段:以前的方法直接基于两个领域重叠的用户,使用映射导向的损失函数(MSE)学习映射函数。事实上,我们希望学到的映射函数在没见过的用户上有很好的效果。我们分析跨领域推荐中的冷启动问题,可以分为这样两个阶段,在已有的重叠的用户上学习知识,然后在冷启动用户上测试。因此我们将训练任务进行相应的划分,来模拟这个过程,每个训练任务分为两批,两批包含的用户是不重叠的,这两批分别来模拟在重叠用户上学习知识和在冷启动用户上测试这两个阶段,使用MAML[7]进行训练。另外我们提出了一种任务导向的优化方法,不使用MSE来优化meta network(mapping),而是直接使用任务标签来优化,比如评分数据就使用评分来进行优化。
模型方法
整个框架包含两个阶段,transfer阶段和meta阶段,整个训练流程如下:

以前的方法(例如EMCDR)采用映射导向的优化目标直接拉进映射后的用户向量和目标用户向量的距离,如下所示:
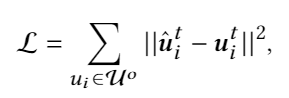
而我们的方法具体损失函数由最终任务优化目标确定。假设模型使用MF作为目标函数,我们的loss以MF的评分预测函数为目标进行优化。这样的好处使得模型迁移的跨领域知识能够在目标函数层级相似。
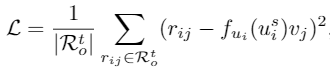
实验
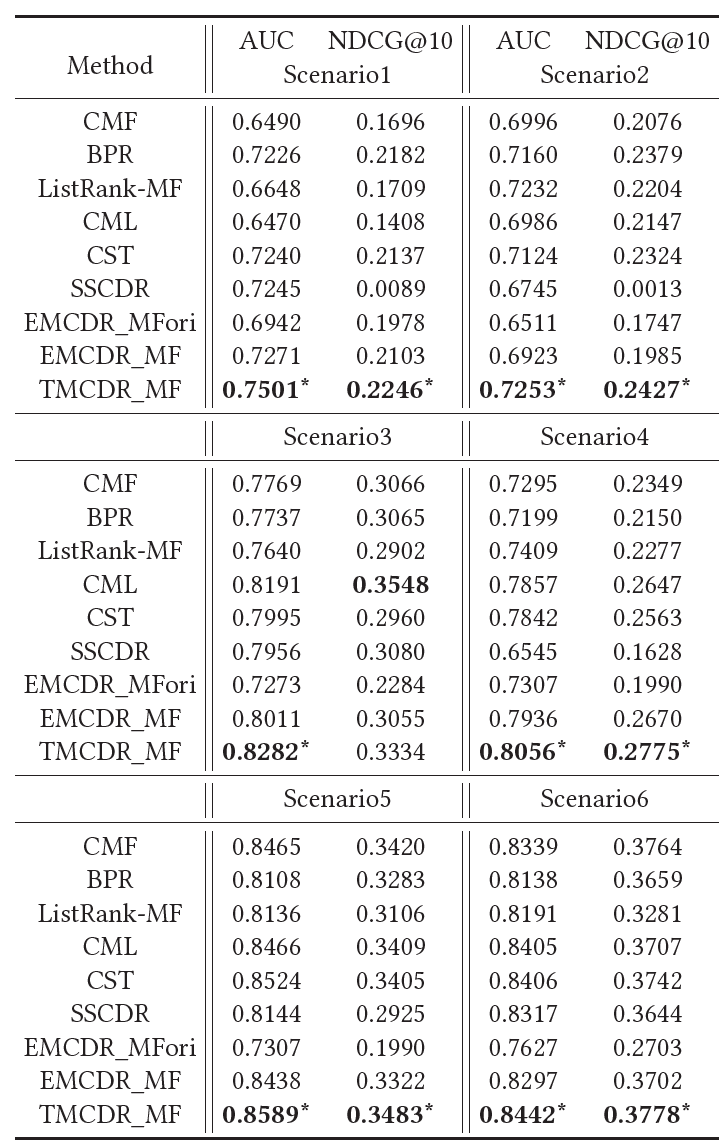
我们使用了两个数据集:Amazon和Douban。这两个数据集被广泛地在跨领域推荐的研究中采用。我们在Amazon数据上构造了4个跨领域推荐任务,在Douban数据上构造了两个任务。具体结果如下:
总结
在这篇工作中,针对现有的跨领域推荐的方法的不足,我们提出了一种新的transfer-meta的框架。该框架分为transfer和meta两个阶段。
Transfer阶段主要获取源领域和目标领域的预训练模型。在meta阶段我们采用MAML训练meta network(映射函数),这样得到的映射函数有更强的泛化能力。另外我们还提出了一种任务导向的优化方法,相比现有的映射导向的方法有更好的效果。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。



