AAAI2022@腾讯 | 多任务推荐系统中的跨任务知识蒸馏
Title:Cross-Task Knowledge Distillation in Multi-Task Recommendation
Link:https://arxiv.org/pdf/2202.09852
From:AAAI 2022

1. 导读
hard label:知识蒸馏中的数据原有真实标签,本文直译为硬标签
soft label:知识蒸馏中教师模型输出的软标签
多任务学习被广泛应用于推荐系统,先前的工作专注于设计底部层的结构来共享输入数据的信息,但是由于它们采用特定任务的二分类标签作为训练的监督信号,因此关于如何准确排序商品的知识并未在任务之间完全共享。
本文旨在增强多任务个性化推荐优化目标的知识迁移。本文提出了一个跨任务知识蒸馏(CrossDistil)框架,它由三个过程组成。
-
1) 任务增强:引入具有四元组的损失函数的辅助任务来捕获跨任务细粒度排名信息,通过保留跨任务一致知识来避免任务冲突,从而为知识蒸馏提供先决条件; -
2) 知识蒸馏:设计了一种基于增强任务的知识蒸馏方法,用于共享排名知识,其中任务的预测与校准过程保持一致; -
3) 模型训练:教师和学生模型采用端到端的方式进行训练,采用新颖的纠错机制,加快模型训练速度,提高知识质量。
2. 方法
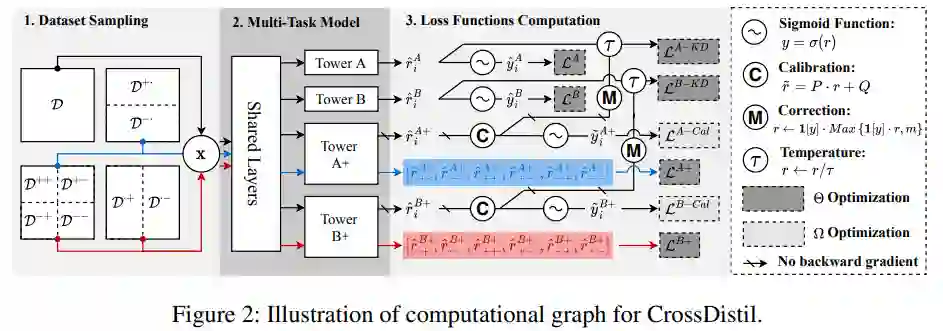
2.1 任务增强
本文专注于多任务学习来预测不同的用户反馈(例如点击、喜欢、购买、浏览)。为了简化说明,文中用两个任务来说明相关内容,任务 A 和任务 B (一个用于学生,另一个用于教师)。首先,根据多个任务标签的排列,将训练样本分成多个子集。如图 2 所示,它们被定义为:
其中x是输入向量,y是对应任务的标签,任务的目标就是让正样本排在负样本的前面,对于任务A表示为 ,对于任务B表示为 ,其中 ,其他的x也类似。**在不同的任务中,可能出现矛盾的情况,例如,任务 A ** 而任务 B 的 。这种冲突将为共享参数的反向梯度提供不一致的信号。
给定四元组 ,对任务A考虑一个顺序关系 ,这里显示的控制+-和-+之间的关系,从而避免上述冲突给任务A的训练带来负面影响。将这种四元组关系视为细粒度排名,他考虑了额外的顺序信息 并且仍然包含原始的顺序关系 。基于此,引入了一种新的基于排名的任务,称为增强任务 A+,通过额外最大化以下目标来增强知识转移,其中r为最后一层的logit输出, ,σ表示sigmoid函数。
则A+的损失函数可以写为下式,他由对应于三个成对关系的三个项组成(即前面包含的三个不等式关系),β是超参数,用于平衡不同部分的作用,同理可以得到B+的损失函数。
增强任务的计算图在图 2 中以蓝色和红色突出显示。这些增强的基于排名的任务与 MTL 框架中的原始的任务堆叠并联合训练。原始任务可以表示为下式,
引入的辅助任务可以避免任务冲突,因此是通过 KD 进行知识迁移的先决条件。此外,任务增强本身是有益的,因为在训练中引入更多相关任务可以增强主任务的泛化性。
2.2 校准的知识蒸馏
为了解决主流 MTL 框架的局限性,本节通过跨任务的知识蒸馏在优化目标级别上传递细粒度的排序知识。由于另一个任务的预测结果可能包含有关相同标签的样本之间未见排名的信息,因此一种直接的方法是使用另一个任务的软标签通过蒸馏损失来教导当前任务,公式如下,其中CE为交叉熵损失函数。
但是正如上一小节中所述,因为不同任务的标签可能具有相互矛盾的排名信息,这会损害其他任务的学习。处理方法是仅传输由增强任务捕获的不冲突的排名知识。具体来说,将基于增强排序的任务视为教师,将原始任务视为学生,并采用以下蒸馏损失函数,其中 , 表示软标签。
根据上式,学生模型训练时不会被误导,其损失函数如下,
然而,上述方法的一个问题是,增强任务是用成对损失函数优化的,因此不能预测概率,即只考虑排序关系而不考虑预测概率是都准确。直接使用教师模型的软标签可能会误导学生模型,导致性能下降。作者采用经典的校准方法 Platt Scaling 对预测概率进行校准。形式上,为了获得校准的概率,我们通过以下等式转换教师模型的 logit 值,对于B+的任务采用同样的方法,其中P,Q是可学习参数。
因此损失函数如下,
2.3 模型训练
有两组用于优化的参数,即用于预测的 MTL 主干中的参数(表示为 Θ)和用于校准的参数,包括
,
,
,
表示为 Ω。为了联合优化预测参数和校准参数,采用一个双层训练过程,其中 Θ 和 Ω 在每次迭代中依次优化,如训练算法所示。

2.4 错误纠正机制
在基于 KD 的方法中,学生模型根据教师模型的预测进行训练,而不考虑它们是否准确。然而,与硬标签相矛盾的教师模型的不准确预测可能会在两个方面损害学生模型的性能。
-
首先,训练早期,教师模型训练不充分,软标签中会有较多错误标签,这会分散学生模型的训练过程,导致收敛缓慢)。 -
其次,训练后期,教师模型相对较好,教师模型仍然可能偶尔会提供可能导致性能下降的错误预测。
本文提出一种方法使得校准后的输出 和硬标签y对齐,裁剪教师模型的输出logit公式如下,其中 可以是 或 ;如果y=1则 ,否则其为-1,m为阈值超参数。
-
对于正确预测,或者说高于阈值的预测,此操作不会修改结果。只有低于阈值的错误预测才会被修正。 -
调整操作仅针对教师模型计算没有后向梯度的蒸馏损失进行,如图2所示,这表明它不影响教师模型的训练过程。
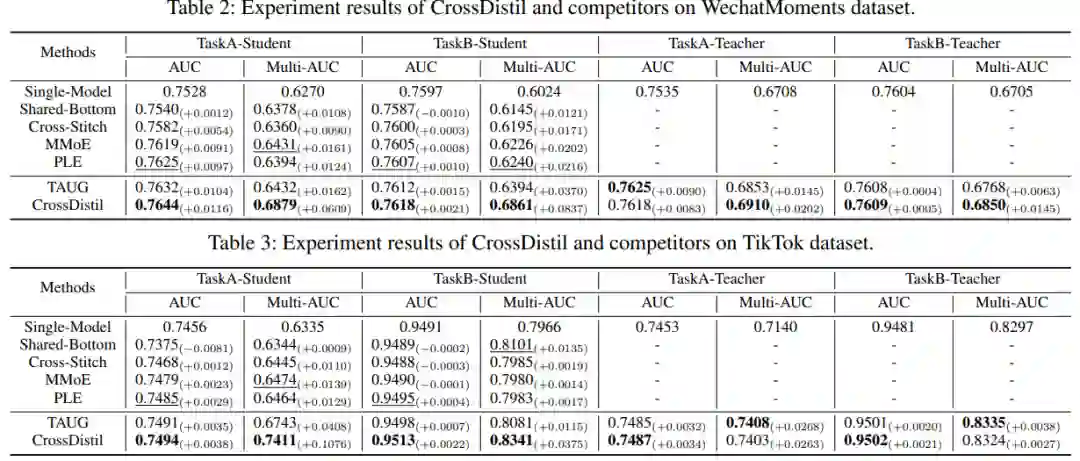
3. 结果
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
TKDE2022 | 最新深度学习推荐系统综述:从协同过滤到信息增强的推荐系统
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


