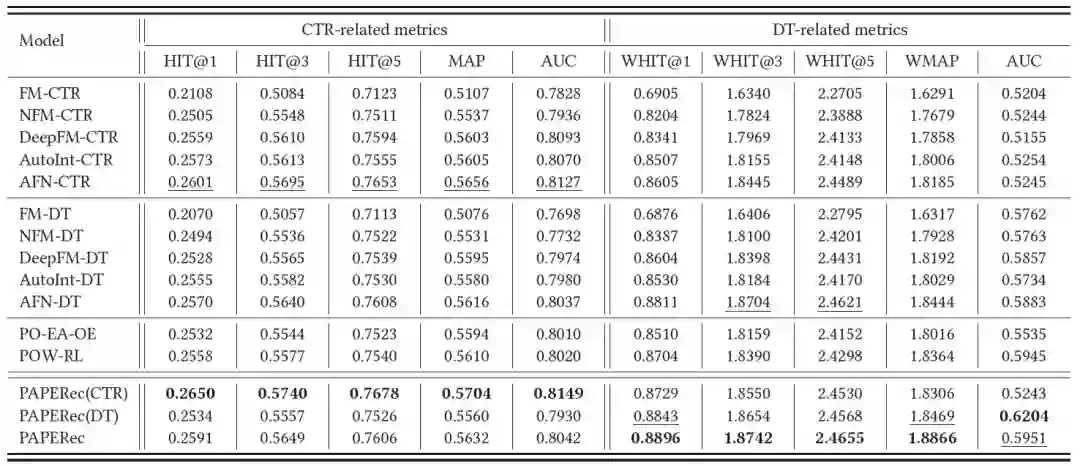
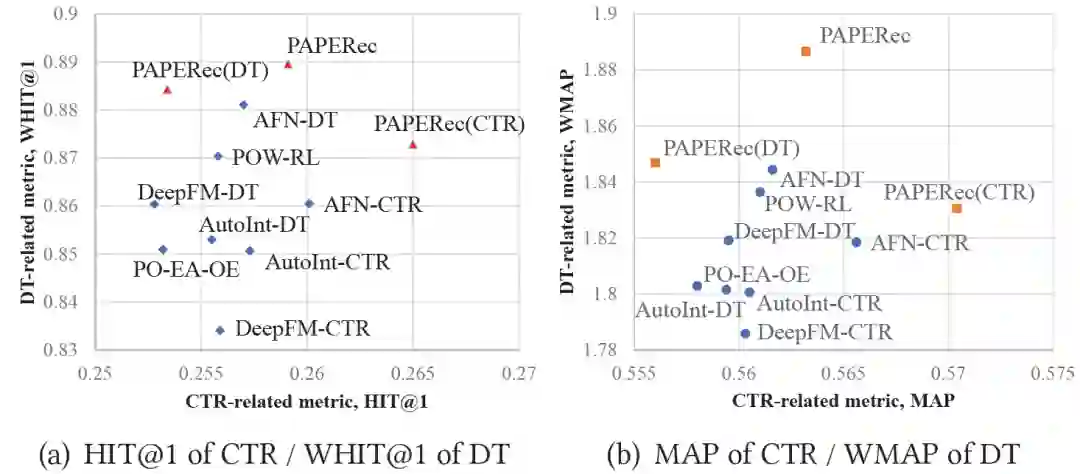
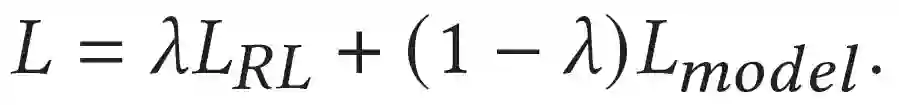参考文献
[1] Désidéri J A. Multiple-gradient descent algorithm (MGDA) for multiobjective optimization[J]. Comptes Rendus Mathematique, 2012, 350(5-6): 313-318.
[2] Sener O, Koltun V. Multi-task learning as multi-objective optimization[C]. NeurIPS, 2018.
[3] Lin X, Chen H, Pei C, et al. A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation[C]//Proceedings of the 13th ACM Conference on Recommender Systems. 2019: 20-28.
[4] Xie R, Ling C, Wang Y, et al. Deep Feedback Network for Recommendation[C]. Proceedings of IJCAI-PRICAI, 2020.
[5] Ruobing Xie*, Shaoliang Zhang*, Rui Wang, Feng Xia and Leyu Lin. Hierarchical Reinforcement Learning for Integrated Recommendation[C]. AAAI, 2021.
[6] Guo, Huifeng, et al. "DeepFM: a factorization-machine based neural network for CTR prediction." Proceedings of IJCAI, 2017.
[7] Song, Weiping, et al. "Autoint: Automatic feature interaction learning via self-attentive neural networks." Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019.
[8] Ribeiro M T, Ziviani N, Moura E S D, et al. Multiobjective pareto-efficient approaches for recommender systems[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2014, 5(4): 1-20.
[9] Cheng W, Shen Y, Huang L. Adaptive factorization network: Learning adaptive-order feature interactions[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(04): 3609-3616.
[10] Xiao L, Min Z, Yongfeng Z, et al. Fairness-aware group recommendation with pareto-efficiency[C]//Proceedings of the Eleventh ACM Conference on Recommender Systems. 2017: 107-115.