总结 | 基于知识蒸馏的推荐系统
↑↑↑关注后"星标"机器学习与推荐算法
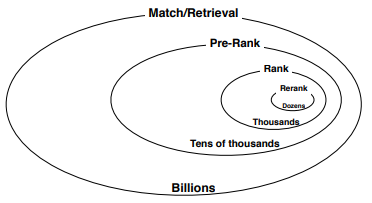
无论是商品推荐,还是广告推荐,都大致可以分为召回,预排序(粗排),精排等阶段,如上篇<淘宝搜索中基于embedding的召回>的图所示:
-
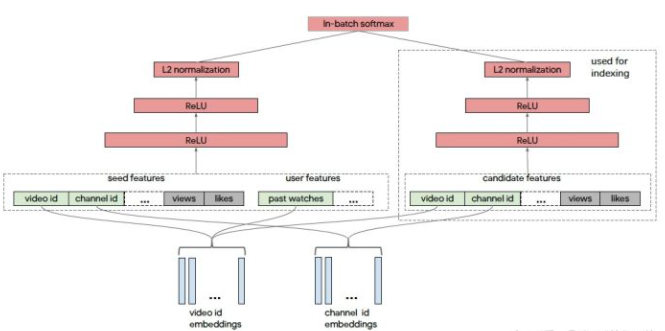
由于training阶段不要求实时操作,允许训练一个复杂的模型,蒸馏模型可以在training阶段用复杂度高的网络(teacher network)-学到的知识指导较为简单的网络(student network)学习,在serving阶段以较小的计算代价来使用简单网络,同时保持一定的网络预测能力。 对于一些线上serving阶段无法获取的但又对目标有实际意义的特征,如用户与广告或商品的交互特征等,可以在training阶段将这类特征都加入teacher network学习,而线上serving阶段只需获取用于训练student network的基本特征,serving过程只使用student network结构。
可以将集成的知识压缩在简单的模型中。对于一个已经训练好的复杂的模型,如果要集成的话要带来很大的计算开销,而使用蒸馏模型可以用复杂模型指导一系列简单模型学习,根据复杂的大网络和一系列简单模型的输出作为目标,训练一个最终的模型,可不用对复杂模型进行集成。
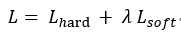
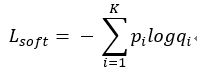
也可以用带温度的softmax函数控制teacher信号的传输:
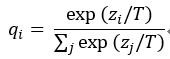
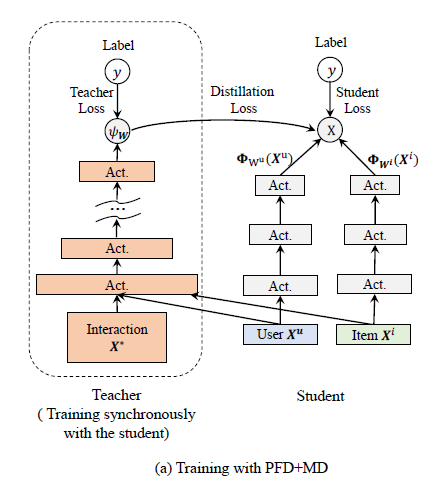
Lsoft也可以用logit直接的mse loss进行学习。大致框架如下图所示:
喜欢的话点个在看吧👇
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月15日
Arxiv
11+阅读 · 2019年6月13日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日
Arxiv
11+阅读 · 2019年6月13日