
腾讯健康,腾讯医典有多个个性化推荐场景,为了提高推荐效果,使用预训练机制学习更完整的用户表示。
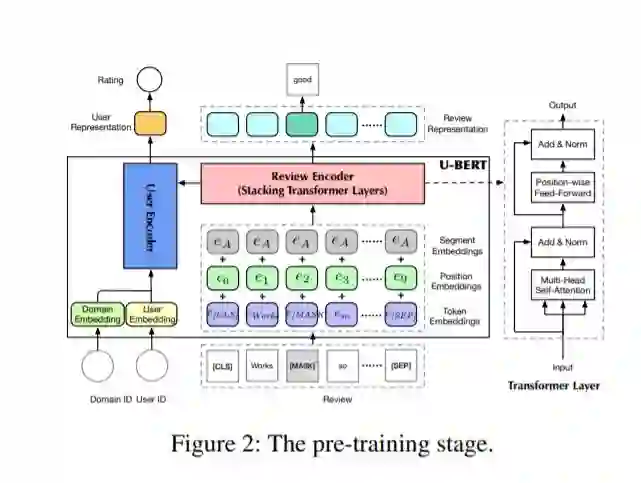
用户表示的学习是推荐系统模型中的重要一环。早期的方法根据用户和项目之间的交互矩阵来学习用户表达,但这些交互矩阵非常稀疏且矩阵中的值通常是粗粒度的,导致系统很难学习到准确的用户表达。近期一些工作利用信息更加丰富的评论文本来增强用户的表示学习,但对于冷门的领域或场景,评论文本的数量也不足以帮助其学习到完整准确的用户表示。用户的一些偏好(如评论习惯等)是在不同的领域或场景间共享的,我们可以利用数据丰富的场景下的评论帮助数据不丰富的场景的推荐。同时,受到近期自然语言处理领域中预训练技术的启发,本论文提出了一种基于预训练和微调的两阶段推荐模型。如图(a)所示,U-BERT包含两个主要模块能够建模评论文本并将其语义信息和用户的嵌入表达进行融合。在预训练阶段,我们设计了两种新的预训练任务能够充分地利用不同场景下积累的评论文本来学习通用的用户表达。如图(b)所示,在微调阶段,我们会根据特定场景下的评论数据对预训练的用户表示进行微调以适应当前场景下的特点。此外,在进行评分预测时,我们还设计了一个co-matching模块以捕捉细粒度的语义匹配信息来更好地预测用户对项目的打分。实验结果表明,本文提出的推荐模型在多个开放数据集上取得了性能提升。
http://34.94.61.102/paper_AAAI-2116.html
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文