CentripetalNet:目标检测新网络,COCO 48 % AP超现所有Anchor-free网络
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:AI深度视线
引言

思路创新点
-
传统方法:
主要采用关联嵌入(associative embeding)法对角点进行配对,需要网络对每个角点额外学习一个嵌入(embeding),判断两个角是否属于同一个边框。以这种方式,如果两个角来自同一个box,它们将有类似的嵌入,否则,它们的嵌入将是非常不同的。基于关联嵌入的检测器在目标检测中取得了良好的性能,但也存在一定的局限性。
-
缺点:
首先,传统方法在训练过程中运用推拉损失来学习每个点的嵌入。推损(Push loss)将在不属于同一物体的点之间计算,以使它们彼此远离。而拉损(Pull loss)只考虑来自同一物体的点之间的拉损。因此,在训练过程中,网络实际上是被训练来寻找对角线上所有潜在点中唯一的匹配点。它对异常值高度敏感,当一个训练样本中有多个相似对象时,训练难度会急剧增加。
其次,嵌入预测是基于外观轮廓,没有使用位置信息,因此如图1所示,如果两个物体有相似的外观,即使相距很远,网络也倾向于预测它们的相似嵌入。
-
基于上述考虑, 作者 提出 两点创新:
-
一种新颖的向心偏移角匹配方法
向心偏移 : 给定一对角 点 , 作者 定义一个二维向量,即向心位移,对于每个角,向心位移编码空间偏移从角 点 落到盒子中心点。这样,每个角都可以根据向心位移产生一个中心点,如果两个角属于同一个 边框 ,那么它们产生的中心点应该是相近的。匹配的质量可以用两个中心之间的距离和匹配的几何中心来表示。结合每个角点的位置信息,与关联嵌入方法相比,该方法对异常值具有较强的鲁棒性。 -
一种能够更好地预测向心偏移的交叉星形可变形卷积模块
CentripetalNet
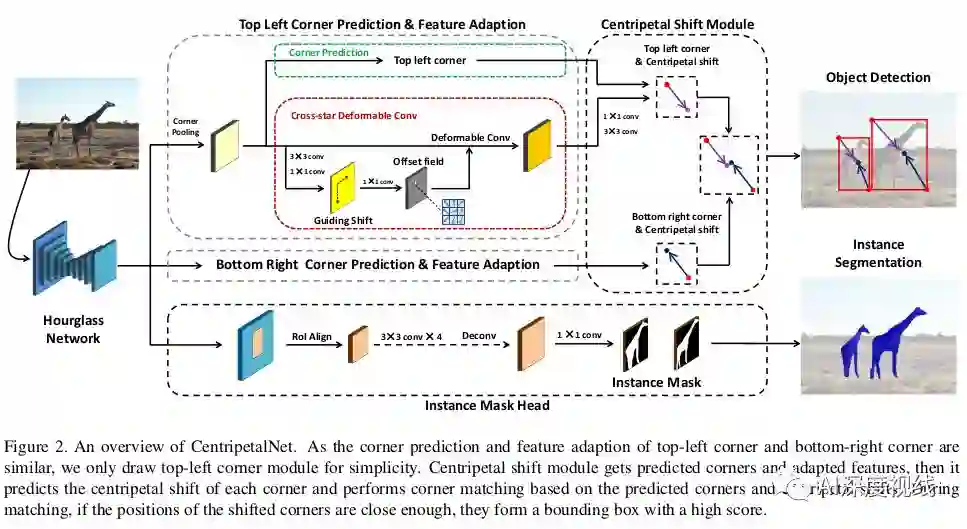
网络结构
上图为centrpetalnet的核心结构。Centrpetalnet由四个模块组成,分别是角点预测模块、向心移位模块、交叉星可变形卷积模块和实例掩码头模块。
工作原理
首先基于Centernet pipline生成角点候选对象。对于所有的角点候选项,引入向心移位算法来追求高质量的角点对并生成最终的预测边界框。向心偏移模块预测角点的向心偏移,并匹配角对,这些对角对的偏移结果从其位置解码,并且向心偏移对齐。
然后,交叉星可变形卷积,它的偏移场是从角到相应中心的偏移中学习,进行特征适应,丰富角位置的视觉特征,这对于提高向心位移模块的精度是很重要的。
最后,添加了一个实例掩码模块来进一步提高检测性能,并将该方法扩展到实例分割区域。该方法以向心位移模块的预测边框为region proposals,利用RoIAlign提取region特征,并利用小型卷积网络对分割掩码进行预测。centrpetalnet是端到端训练的,可以使用或不使用实例分割模块进行推理。
3.1 Centripetal Shift Module
-
Centripetal Shift 向心偏移:
对于一个box:
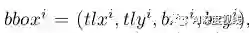
它的中心为:
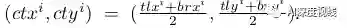
作者定义它两个角点的向心偏移为:
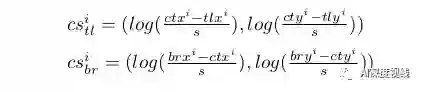
这里作者使用对数函数来减少向心位移的数值范围,使学习过程更容易。
在训练中,作者在地面真值角的位置应用平滑的L1损失:
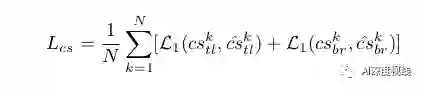
Corner Matching.
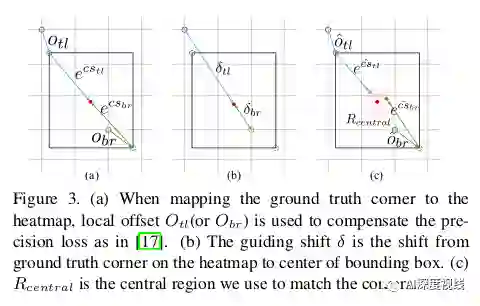
为了匹配角点,作者设计了一种利用角点向心位移和位置的匹配方法。一个属于同一边界框的一对角应该共享该框的中心,至少直觉上来说这是合理的。由于我们可以从预测角的位置和向心偏移中解码出相应的中心,因此很容易比较一对角的中心是否足够靠近并接近由角对组成的边界框的中心,例如如图3(c)所示。
基于以上观察,作者的方法如下,一旦从角热图和局部偏移特征图中获得角点,作者将相同类别的角进行分组,满足(tlx < brx)∧(tly < bry)的条件,构造预测边框。对于每个边界框bboxj,作者将其得分设置为其角点得分的几何平均值,这些分数是通过在预测的角点热图上应用softmax得到的。然后,如图3所示,作者将每个边界框的中心区域定义为公式3,以比较解码中心和边界框中心的接近度。
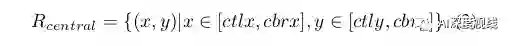
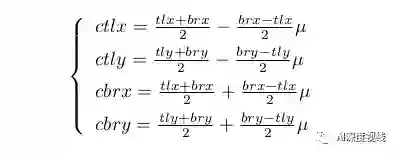
其中0<µ≤1表示中心区域的宽度和高度是边界框的宽度和高度的µ倍。通过向心偏移,可以分别解码左上角和右下角的中心(tlctx, tlcty)和(brctx, brcty)。
然后作者计算每个预测边界框的得分权重wj,这意味着回归的中心更接近,预测的box有更高的得分权重。
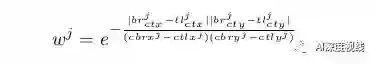
对于其他边界框,作者设置wj=0。最后,作者可以通过乘以分数权重对预测的边界框进行重新评分。

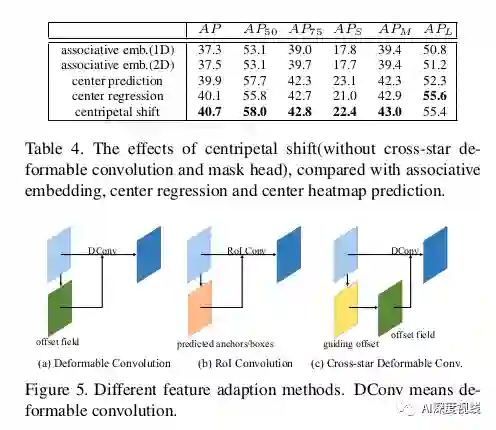
作者提出的可变形的交叉星卷积如图2所示。
首先,作者将角池的特征映射输入到可变形的交叉星卷积模块中。为了学习可变形卷积的“十字星”的几何结构,使用对应目标的大小来显式地引导偏移场分支,因为“十字星”的形状与包围盒的形状有关。然而,以左上角为例,他们应该少注意“十字星”的左上角,因为有更多的无用信息在目标之外。
因此,作者嵌入了一个导向偏移——从角落到中心的偏移到偏移场分支,如图3(b)所示,它包含了形状和方向信息。具体来说,偏移场是在三个卷积层上进行的。前两个卷积层将角池输出嵌入到feature map中,其Loss如下:
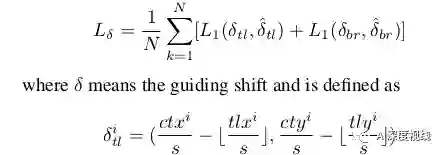
第二个卷积层将上述特征映射到偏移量字段,偏移量字段显式地包含上下文和几何信息。作者的cross-star deformable convolution通过将学习到的偏移场可视化,如图7c所示,可以有效地学习' cross star '的几何信息,提取' cross star '的边界信息。

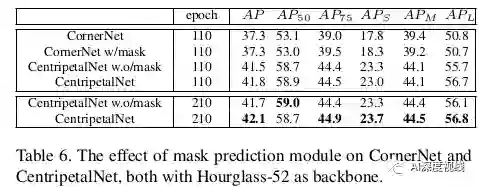
为了得到实例分割掩码,作者将soft-nms前的检测结果作为region proposals,并利用全卷积神经网络对掩码进行预测。为了保证检测模块能够产生方案,作者首先对中心网进行了几个时代的预训练。选择得分最高的k个提案,然后在主干网的特征图上进行RoIAlign,得到它们的特征。作者将RoIAlign的尺寸设置为14×14,并预测得到一个28×28的掩模。在得到RoI的特性后,作者应用连续四个3×3层卷积,然后用一层反卷积upsample特性映射到28×28 mask地图。在训练过程中,作者对每个区域的方案应用交叉熵损失。
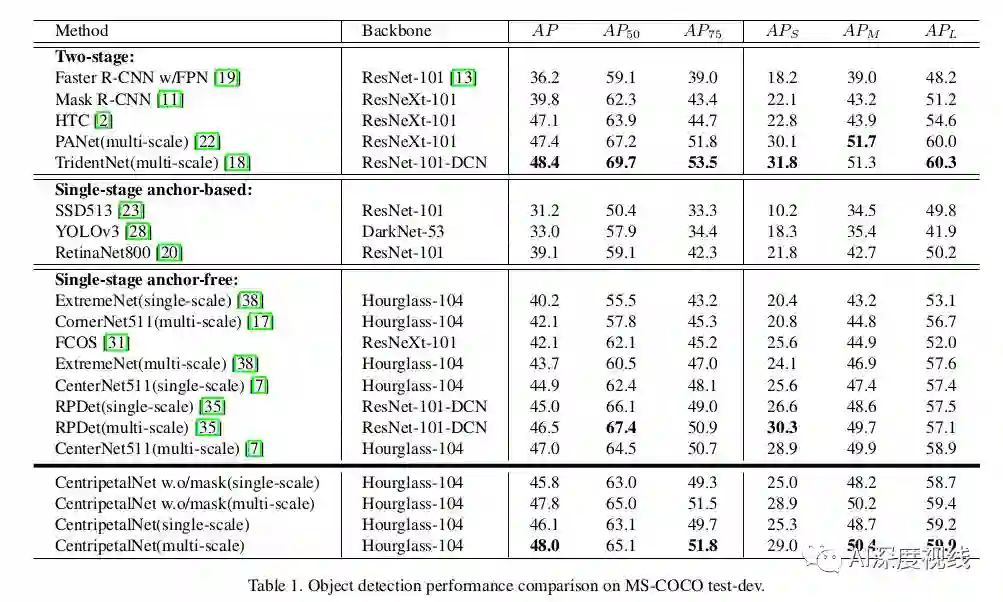
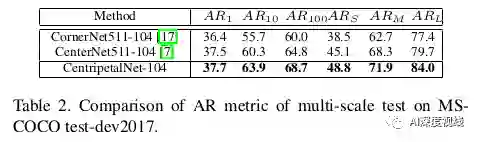
实验和结果
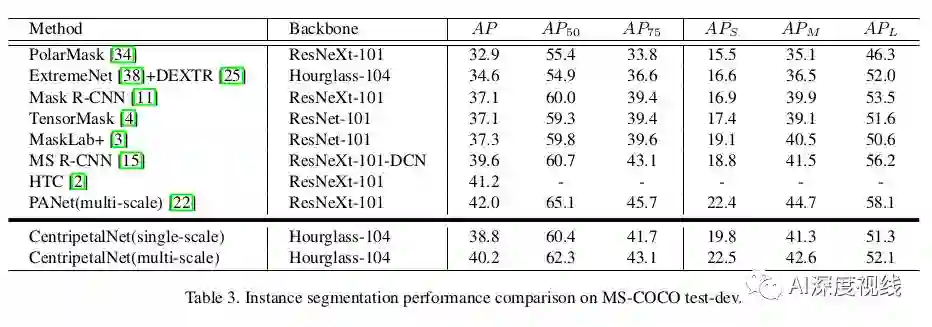
COCO数据集比较:
实例分割:



重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集3500人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!

