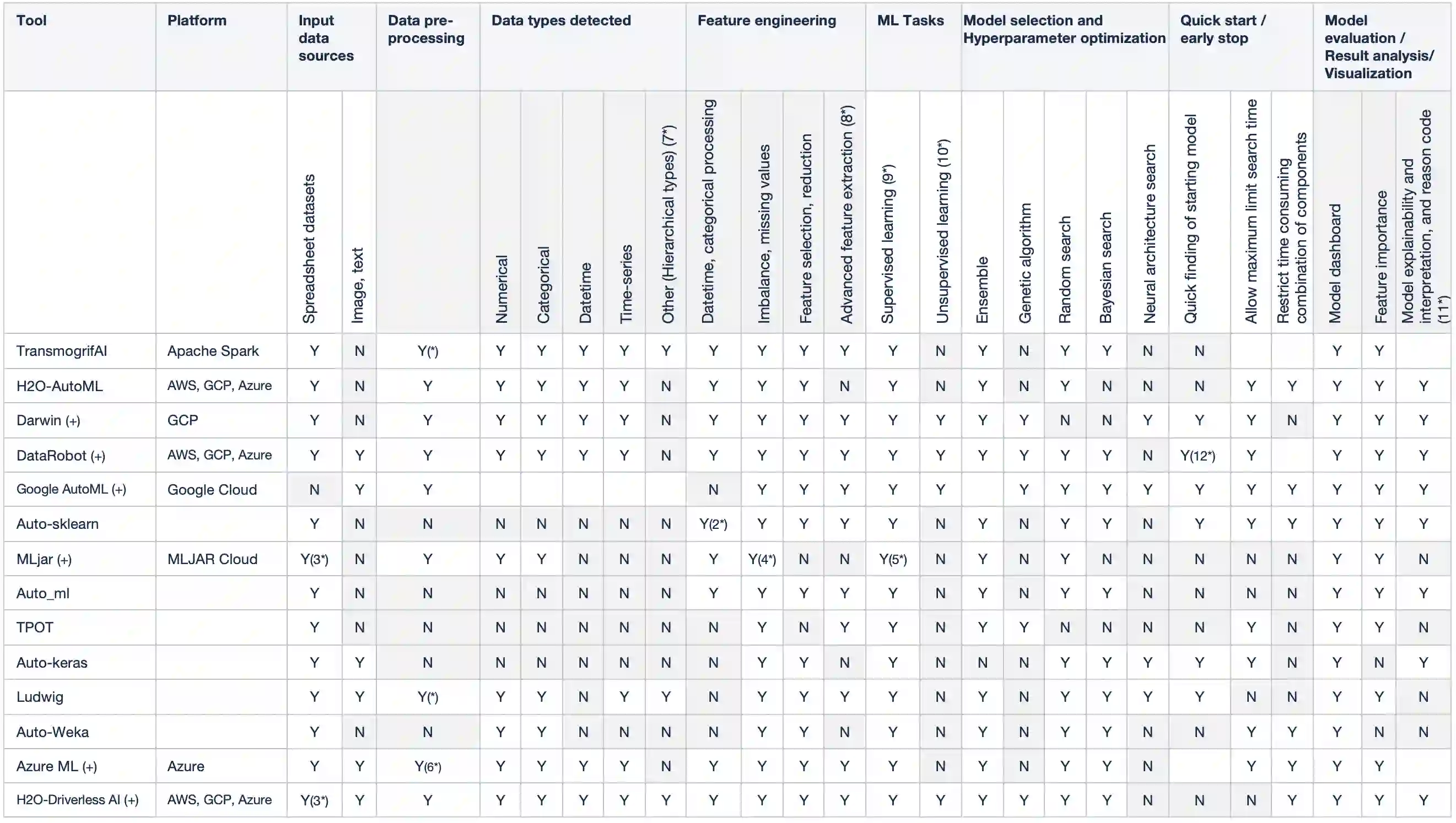
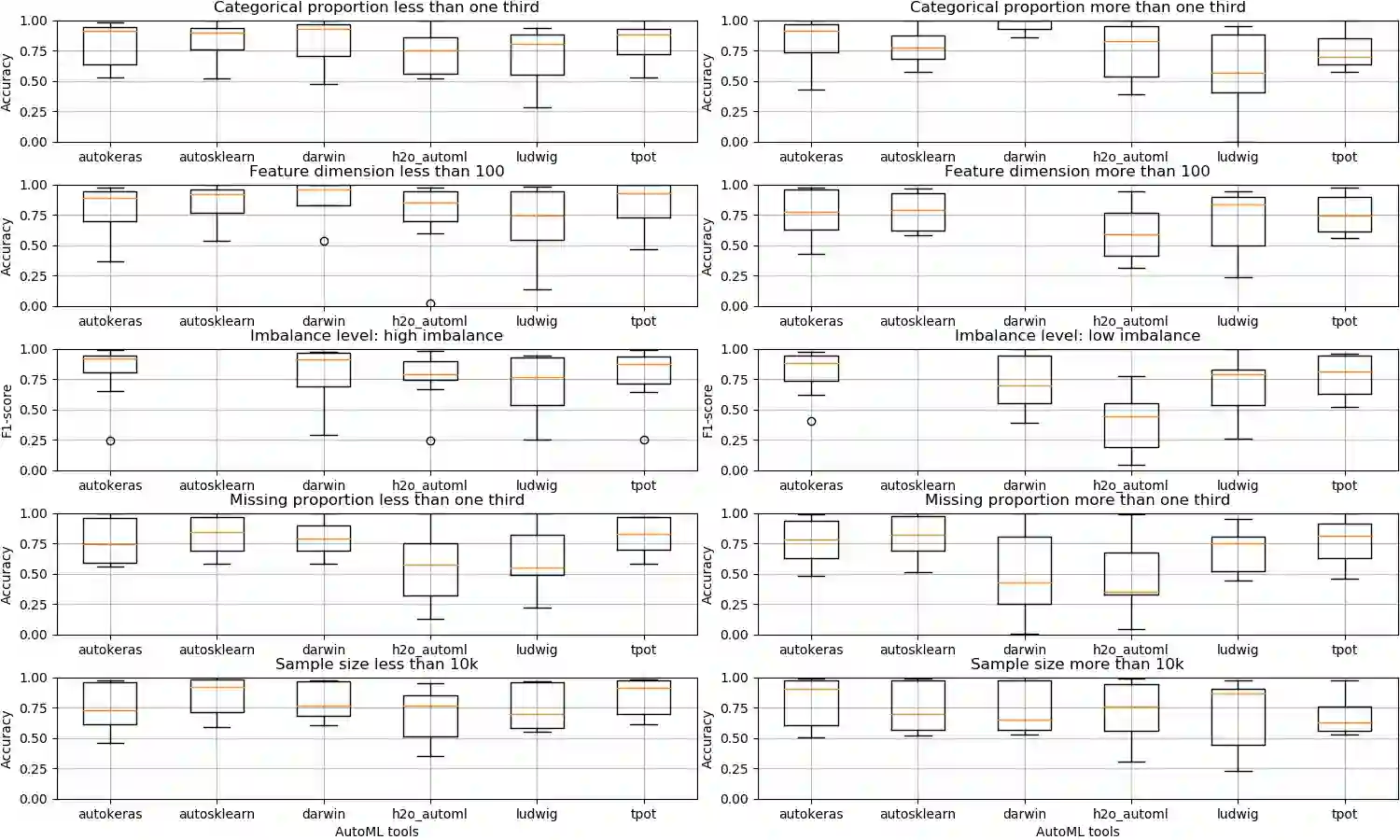
There has been considerable growth and interest in industrial applications of machine learning (ML) in recent years. ML engineers, as a consequence, are in high demand across the industry, yet improving the efficiency of ML engineers remains a fundamental challenge. Automated machine learning (AutoML) has emerged as a way to save time and effort on repetitive tasks in ML pipelines, such as data pre-processing, feature engineering, model selection, hyperparameter optimization, and prediction result analysis. In this paper, we investigate the current state of AutoML tools aiming to automate these tasks. We conduct various evaluations of the tools on many datasets, in different data segments, to examine their performance, and compare their advantages and disadvantages on different test cases.
翻译:近年来,在机器学习的工业应用方面出现了相当大的增长和兴趣,因此,制造业的工程师在整个工业中需求很大,但提高制造业工程师的效率仍是一项基本挑战,自动机器学习(自动ML)已成为节省时间和精力的方法,以完成诸如数据预处理、地物工程、模型选择、超参数优化和预测结果分析等机械学习管道中的重复任务。我们在本文件中调查了旨在将这些任务自动化的自动ML工具的现状。我们对不同数据部分的许多数据集工具进行了各种评估,以检查其性能,并比较不同测试案例的优缺点。