RTM3D:面向自动驾驶场景的首个实时单目三维目标检测方法
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:李培玄 编辑:Amusi(CVer) https://zhuanlan.zhihu.com/p/105554165 本文已由作者授权转载,未经允许,不得二次转载
题目:《RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving》

论文链接:https://arxiv.org/abs/2001.03343
GitHub:https://github.com/Banconxuan/RTM3D
Introduction
三维检测在自动驾驶中至关重要,目前SOTA方法大多利用激光雷达或者结合图像进行检测。但其激光雷达价格昂贵而且在车顶放着消费者很难接受,相反单目价格便宜并且可以无痛嵌入当前车型。当然单目在三维检测主要评价指标IoU=0.7上还远远落后LiDAR-based的方法。不过三维检测在自动驾驶中毕竟属于较前端的感知部分,后端未必需要如此高的IoU,而且在保证一定精度的情况下,效率更重要。毕竟车是一个高速运动的物体,30码一秒就冲出8米了。然而目前还没有很好的实时(fps>24)单目系统,这是由于大多数三维检测方法基于成熟的二维检测器,在目标的RoI中添加额外的回归分支预测三维参数。当然这种直接回归的方法由于搜索空间过大很难取得好的效果。从Deep3DBox之后,大部分都会将投影几何引入作为一种约束。由于2D BBox只能提供四个约束,这就要求BBox的预测相当精准,因此他们大多利用two-stage的2D detector(Faster-RCNN居多)。这就很难使得整个检测过程实时。另外还有一部分单目方法会利用其它stand-alone网络预测额外的数据如深度图、实例分割、CAD模型等。特别是利用深度图的方法获得了很好的效果。这些方法当然是很难实时,并且训练这些网络大多也需要额外的标注,同时在推理过程中也会耗费更多的资源,不利与单目的落地。
现在面临的问题是,效率和精度怎么样才能同步提升?我们先分析精度,几何融入深度学习的方法一个局限在2D bbox的四条边所能提供的约束实在有限,我们进而考虑特征点的方法,特征点方法对遮挡和截断的物体具有良好的特性。这非常好理解,即使检测出几个特征点,其它的也可以根据物体的表示模型推断出来。目前基于特征点的方法大多采用wire-frame模型的顶点去重新标注,而且大多采用2D detector提供的RoI去回归顶点坐标。仍然使用two-stage的方法速度很难提升,同时human pose estimation已经给出明显信号,即直接回归特征点一般没有heatmap的精度高。因此拟采用one-stage生成heatmap的方法,同时由于有限的wire-frame模型不能穷尽所有的车型,我们考虑只预测3D BBox的八个顶点和一个中心点。在符合我们要求的结构中,我们筛选出cornernet和centernet两种,但是考虑到9个特征点尽管可以提供18个约束,但尺度还没办法确定,所以需要一些额外的先验信息。而centernet这种一个中心若干的基本点的结构更适合我们。至此大致结构已经出来了(图1),下面就是实施的细节。
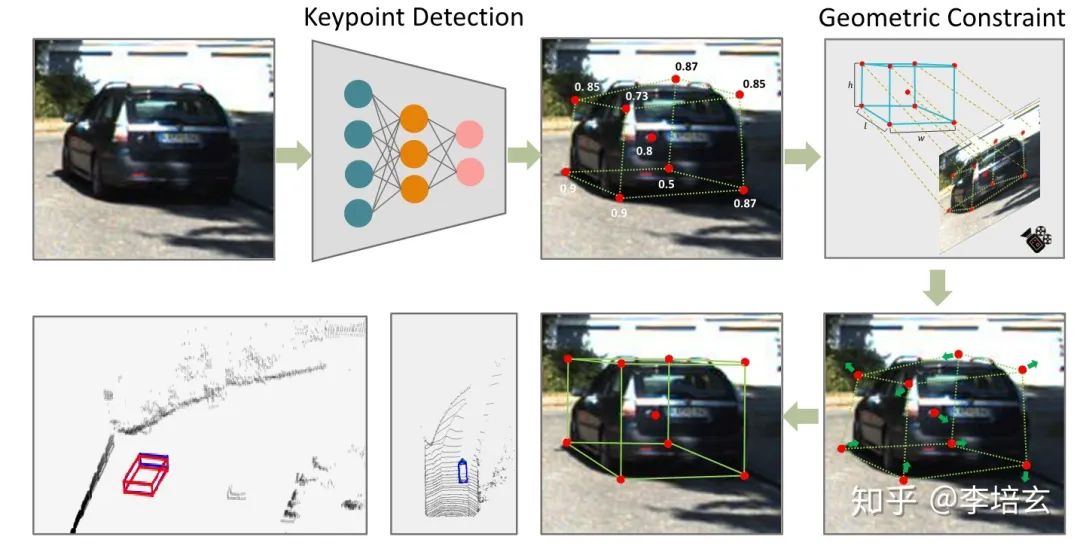
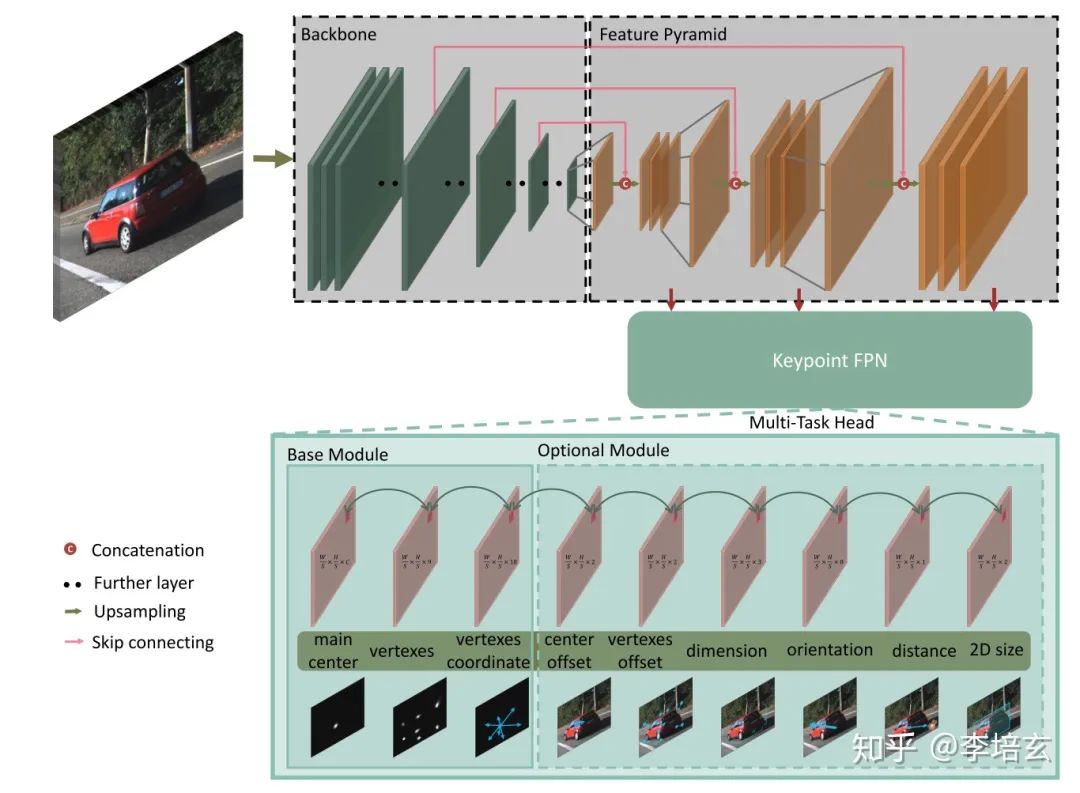
特征点检测网络
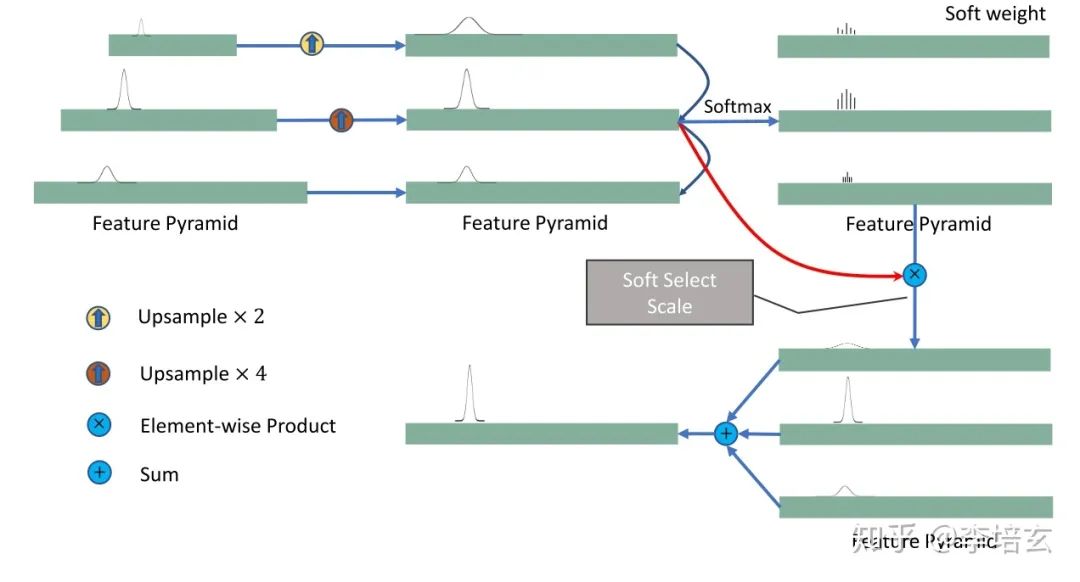
如图2,特征点检测网络的主要结构和centernet相似,分为backbone和检测头。backbone我们因为在速度方面的取舍,只用了ResNet18和DLA-34。其中上采样过程用了跨连接和双线性插值。同时我们也提出了针对keypoint的FPN层(图2),没有采用二维检测器的FPN是因为特征点有很多靠的比较近,这些点在FPN的大多层中会互相重叠,对检测不利。根据速度要求检测头由三个基本单元和6个可选的单元组成。在基本单元中,中枢点负责各数据的association。尽管会增加一点计算量,但仍然用2DBBox的中心点而不用3D中心点的投影。因为截断的物体3Dcenter可能会超出图像范围,对检测不利。其它基本单元还有9个关键点的heatmap和回归坐标,和centernet预测joint一样用来做点之间的grouping。其它可选的部分有量化误差的补偿、物体的大小、方向,中心点的depth和2D bbox的大小。训练方法和loss可以结合原论文和centernet看,在此不做粘贴。
3D Bounding Box Estimate
由特征点检测网络给出9个特征 




其中 


结果
两种验证集上结果:
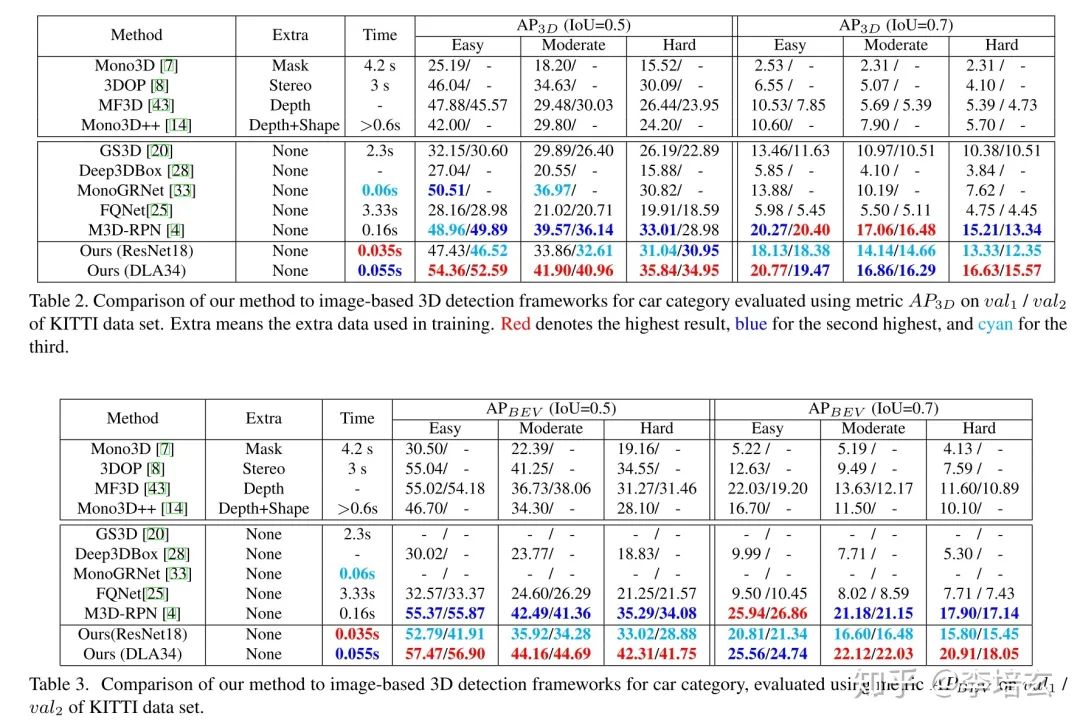
测试集上结果:
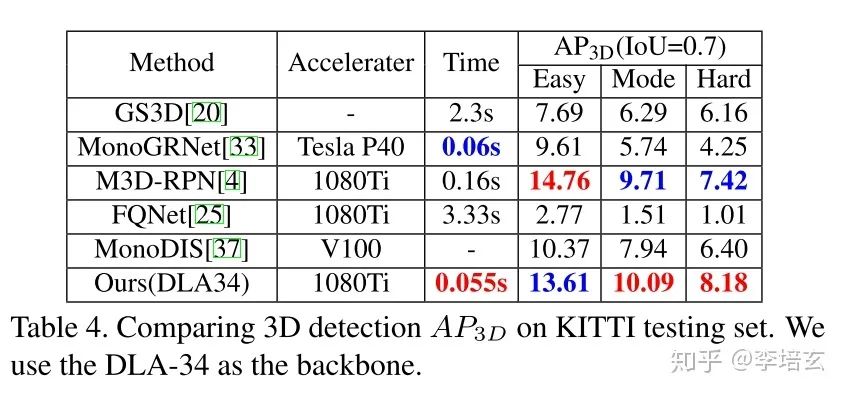
ResNet18作为backbone的时候速度最快,精度已经超过大多数甚至某些双目方法。但仍弱于M3D-RPN(目前不利用其它训练数据最好的网络)。当采用DLA-34时速度仍然比别的方法快,而且精度超过M3D-RPN。
可视化结果:

绿色框为检测的特征点直接连接,蓝色为最终的3D BBox投影到图像上的框。可以看到特征点检测其实已经相当准确。同时BEV图可以看到即使是遮挡和截断区域也能获得很好的效果,这得益于特征点法的优点。这也使得反投影回图像外接的2D BBox也比直接得到2D BBox的效果好(表3)。
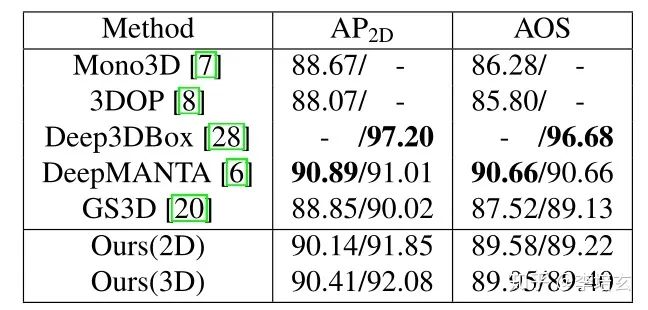 表 3
表 3
为了方便下载,我已经将这篇论文打包,在 CVer公众号 后台回复:20200223 即可获得打包链接。
重磅!CVer-3D目标检测交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、3D目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如3D目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




