告诉我我在哪?——目标级别的场景上下文预测(文末附有原文)
计算机视觉领域,利用局部特征、全局特征、深度特征以及上下文特征已经是大家习以为常的操作,尤其是前三种特征的使用,近期对上下文及显著性特征关注较多,今天和大家分享的一个技术,其也是利用了目标所在场景的上下文特征,更精确去得到目标的位置。
【导读】
背景介绍
场景上下文是指感兴趣的对象与周围环境的关系。语境信息在现代计算机视觉系统中起着重要的作用。最近的工作利用场景上下文来改进目标检测、识别和分割:
[1] H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei. Relation networks for object detection. In CVPR, 2018.
[2] Y. Liu, R. Wang, S. Shan, and X. Chen. Structure inference net: Object detection using scene-level context and instancelevel relationships. In CVPR, 2018.
[3] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A.Efros. Context encoders: Feature learning by inpainting. In CVPR, 2016.
先前的工作试图利用图像中存在的上下文信息来推断图像中某些感兴趣的对象的属性。然而,一个未探索的问题是预测图像中某些对象的未知上下文(即,预测丢失对象的内容和位置)。考虑到几个前景物体,人类凭借对视觉世界的广泛的常识知识,能够很好地推断出他们未知的整个场景背景。例如,给出相框中的前景对象(如下图所示),我们可以推断出围绕它的多个可信环境。给定对象的属性提供了有关场景环境的强烈提示,以及其他对象可能出现在场景中的内容和位置。
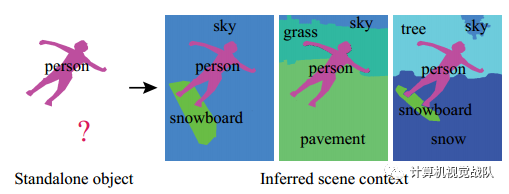
因此,作者对机器是否能够复制这样的场景上下文推理能力这一基本问题感兴趣。相信机器预测物体在哪里的能力可以帮助很多场景的生成和识别任务。然而,由于自然场景中包含着丰富的语义对象,它们之间具有复杂的空间关系,因此开发场景上下文预测模型具有一定的挑战性。对象可以位于不同的位置,具有不同的尺度和形状。此外,这个问题本质上是模棱两可的,因为相同的对象可能有多个语义上合理的场景上下文。
相关工作
Modeling scene context
图像的上下文包含关于对象和场景彼此相关的丰富信息。认知科学研究显示出了背景信息在人类中起着至关重要的作用,尤其在视觉识别领域。有许多类型的上下文信息,包括:
可视上下文[N. Dvornik, J. Mairal, and C. Schmid. Modeling visual context is key to augmenting object detection datasets. In ECCV,2018.],全局场景上下文[A. Torralba, K. Murphy, and W. Freeman. Using the forest to see the trees: Object recognition in context. Comm. of the ACM, 2010.]、相对位置[C. Desai, D. Ramanan, and C. C. Fowlkes. Discriminative models for multi-class object layout. IJCV, 95(1):1–12, 2011.]和布局[A. G. Schwing, S. Fidler, M. Pollefeys, and R. Urtasun. Box in the box: Joint 3d layout and object reasoning from single images. In ICCV, 2013. ]。
随着深度学习,许多任务现在正在开发上下文信息,以学习视觉特征并提高视觉理解性能。一方面,语境对于特征学习是必不可少的。例如,Pathaketal提出了一种用于学习高级的上下文编码器,图像在绘画中的语义特征。另一方面,已经证明上下文在许多视觉任务中是有效的,例如识别、检测和分割。还可以组合多个上下文以提高性能。Choi等人就提出了一种利用多个上下文的图形模型来识别场景中的非上下文对象.。Izadia等对场景类别进行编码,对象的上下文特定外观及其布局学习场景结构。Chien等人建立了一个ConvNet,预测行人在某一位置的概率图像中的位置。Wang等使用了变分法自动编码器显示场景中存在合理不存在的人体姿态的可能性。所有这些作品都使用图像的现有上下文作为原因的附加提示关于感兴趣的前景对象的属性。
今天分享的目标与以前的工作有根本的不同。从概念上讲,在给定的前景对象中,试图解决一个逆问题,即从属性推断缺少的场景上下文。
Unsupervised representation learning via context prediction
在无人监督的情况下已经做出了一些努力通过上下文预测学习视觉表示。所需的Skip-gram模型通过预测单个单词的周围单词来学习单词表示。Doersch等人通过预测图像中的面片的相对位置来学习图像表示(即空间上下文)。Vonrick等人获悉在未标记视频的将来帧(即时间上下文)中预测视觉表示。
在新技术的工作中,最终目标不是视觉表示学习,是对一些独立对象的周围环境的预测。
Context-based image manipulation
许多作品研究了如何在图像处理任务中使用上下文。有些作品使用上下文作为先前检索和组合资产的前提。Tan等人利用CNN捕捉个人构成的背景。通过联合编码前景对象和背景场景的上下文,赵等学习了基于给定背景图像的兼容前景对象检索的特征表示。然而,生成的图像的质量取决于检索数据库。检索到的资产可能无法满足用户的要求并产生不现实的组合。其他作品将语境表示为场景布局,并学习了生成网络来操纵合成图像。
这些方法的一个主要缺点是它们需要完整的语义布局或文本描述作为输入。我们的场景上下文预测模型只需要用户提供包含少量对象的部分语义布局,我们的方法就可以生成各种可能的场景布局,用于合成真实的全场景图像。因此,我们的模型可以被认为是对现有图像合成方法的补充。
新模型
目标是开发一个深度神经网络,它以一个或多个独立对象的属性作为输入,生成对象周围的场景上下文,其中包含可能与给定对象同时发生的其他对象。如下图所示,使用对象级语义布局对输入对象和预测场景上下文进行编码,该语义布局可以简洁地描述场景布局中对象的类、形状和位置。
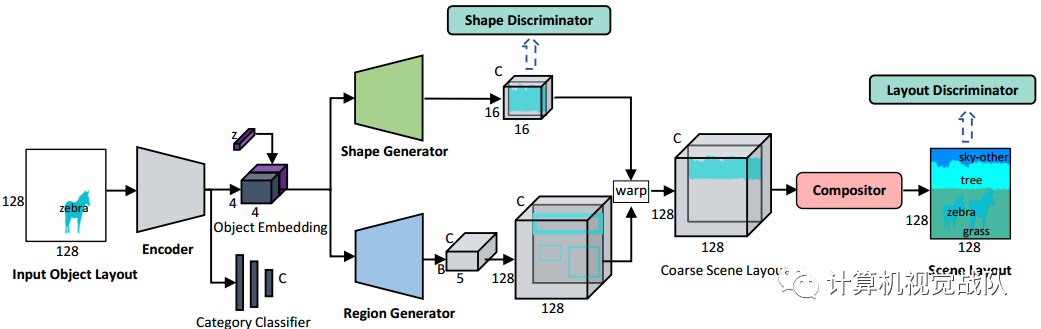
Training
由于上下文预测的复杂性,很难直接对新模型端到端进行训练。因此,首先对类别分类器进行预训练,以获得对象嵌入特征。然后一起训练所有的模块。
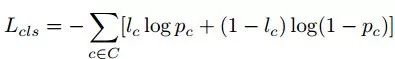
对于区域生成器,定义如下:
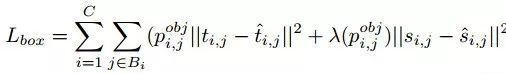
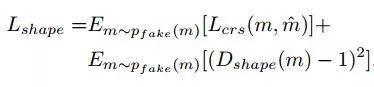
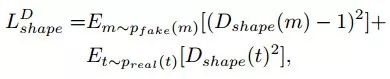
实验结果
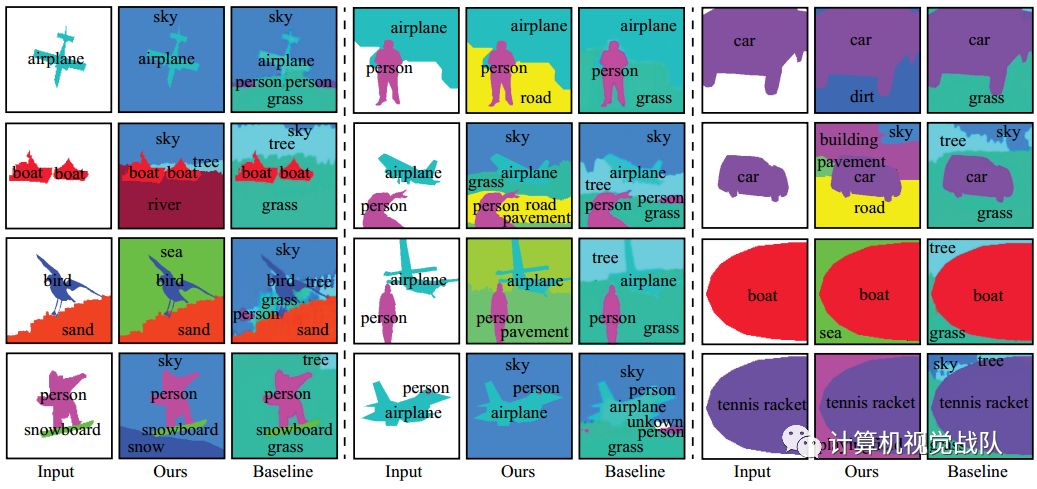
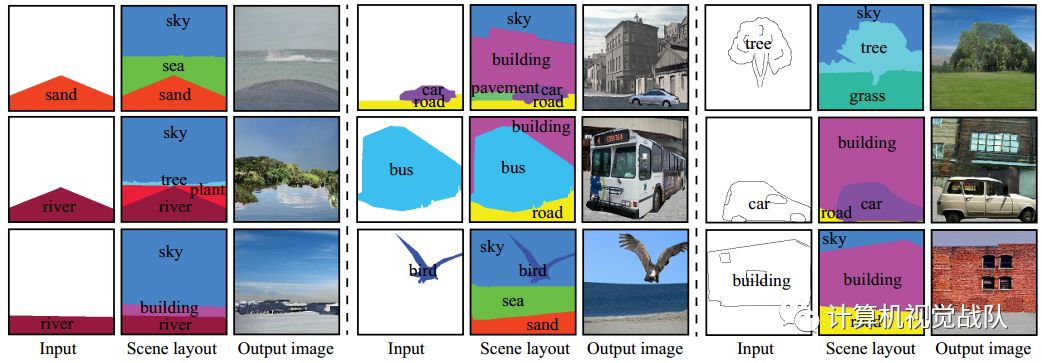
新模型和基线的定性结果。给定输入对象布局(每列中的左图),其中包含一个或两个独立对象,使用新模型(每列的中间图)和基线(每列中的右图)生成输出场景布局。
Quantitative Evaluation
我们利用对象成对关系Priors对生成的场景布局的合理性进行了定量的评价,并在室内场景合成中得到了广泛的应用。特别地,从自然场景图像的数据集计算对象类之间的成对关系的概率,并评估每个生成的场景布局在度量其质量的概率下的可能性。
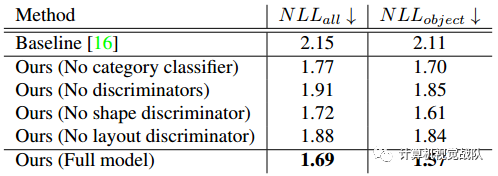
上表比较了新模型与基线的性能。在这两个指标中,新方法都比基线好得多。这再次证实了与基线相比,新方法在预测可信和合适的场景上下文方面具有优越的性能。
在上图,展示了部分语义布局和草图产生的一些图像合成结果。可以看出,新方法可以从稀疏的用户输入中合成复杂的、语义上有意义的全场景图像。
1

推荐阅读:在后台发送相应的获取码就可以获得!
关注“计算机视觉战队”公众号,回复文章获取码,即可获得全文链接。
[1] 人脸检测与识别的趋势和分析 【获取码】0723
[2] 人脸实践篇 | 基于Caffe的年龄&性别识别 【获取码】08
[3] 人脸识别 | 基于深度学习以人类为中心的图像理解 【获取码】24
[4] 人脸专集1 | 级联卷积神经网络用于人脸检测(文末福利)【获取码】03
[5] 人脸专集2 | 人脸关键点检测汇总(文末有相关文章链接)【获取码】23
[6] 人脸专集3 | 人脸关键点检测(下)—文末源码【获取码】10
[7] 人脸专集4 | 遮挡、光照等因素的人脸关键点检测【获取码】01
[8] 人脸专集5 | 最新的图像质量评价【获取码】1021
[9] 加入我们,一起学习深度学习(目标人脸检测识别)【获取码】0
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群,我们会第一时间在该些群里预告!
论文源码地址:
http://openaccess.thecvf.com/content_CVPR_2019/html/Qiao_Tell_Me_Where_I_Am_Object-Level_Scene_Context_Prediction_CVPR_2019_paper.html



