基于上下文信息分离的无监督运动目标检测(文末附有论文及源码下载)
【导读】今天我们主要分享基于上下文的技术用于目标检查。深层神经网络被训练用于利用来自除该区域(上下文)以外的任何其他地方的信息来预测区域内的光流,而另一个网络则试图使这种上下文尽可能少信息。结果模型是一个假设不需要显式正则化或超参数的调整。尽管新方法不需要任何监督,但它的性能要好于在大型注释数据集上预先训练过的几种方法。


从上图可以看出:即使是相对简单的对象,当在场景中移动时,也会导致图像中复杂的不连续变化。能够快速地从图像中检测出各种场景中独立运动的物体,对动物和自动车辆的生存都有很大的帮助。我们都希望赋予人工系统类似的能力,不需要预先条件或学习相似的背景。这一问题涉及到运动分割、前景/背景分离、视觉关注、视频对象分割等问题。
目前,我们非正式地使用“Object”或“Foreground”来表示图像域的(可能是多个)连通区域,根据某种标准我们称之为“背景”或“上下文”,以区别于它们周围的区域。
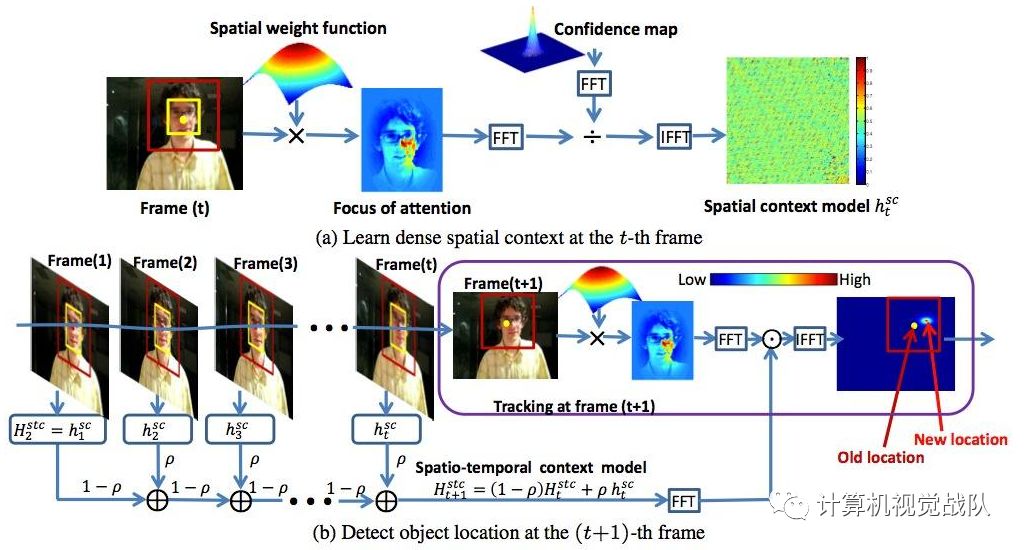
由于物体存在于场景中,而不是在图像中,因此,根据可测量图像相关的操作定义,从后者推断它们的方法是建立在操作定义的基础上的。我们称之为图像中的运动对象区域,其运动无法用其周围运动来解释。换句话说,背景的运动对前景的运动没有信息,反之亦然。
“信息分离”可以通过下面会定义的两者之间的信息减少率(IRR)来量化。这自然转化为一个与经典变分区域分割有密切联系的对抗性推理准则,但新方法不是学习一个区域的生成模型来解释该区域中的图像,而是产生一个模型,该模型试图使用来自除该区域之外的任何地方的测量来尽可能少地解释它。

在基于生成模型的分割中,人们总是可以用一个简单的模型,即图像本身来解释图像。为了避免这种情况,我们必须施加模型复杂性界限、瓶颈或正则化。
新模型无法获得简单的解决方案,因为它被迫在不看区域的情况下预测一个区域,新模型学到的是一个上下文对抗性模型,不需要显式的正则化,前景假设和背景假设竞争来解释数据,不需要预训练或(超)参数选择。
在这个意义上,新方法涉及对抗性学习和自我监督,结果是一种完全无监督的方法,与最近的许多方法不同,这些方法被称为无监督的,但仍然需要在大量标记数据集上进行有监督的预训练。尽管完全缺乏监督,新方法甚至与那些使用监督预训练的方法相比,表现得更有竞争力。

新方法

我们称“移动对象”或“前景”为图像的任何区域,其运动无法从上下文中解释。“图像区域”Ω是图像域的紧致多连通子集,离散类似的为格子框架D。“上下文”或“背景”是图像域Ωc=D\Ω中前景的补充。给定被测量的图像I and/or 其流向下一(或先前)图像u的光流,前景和背景是不确定的,因此被视为随机变量。一个随机变量U1来自于U2,如果它们的相互信息I(u1;u2)是零,即它们的联合分布等于分布P(u1;u2)=P(u1)P(u2)。
损失函数
我们现在把前景的定义变成一个标准来推断它:
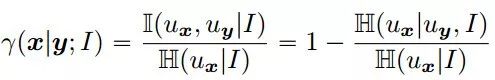
其中H表示熵。当这两个变量是独立的时候,它是零,但是规范化阻止了空集。定义的对象是最小化以下损失函数的区域:
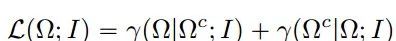
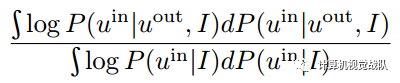
以上是IRR比率,测量从背景到前台的信息传输。当背景流的知识足以预测前景时,这是最小的。为了便于计算,必须对潜在的概率模型进行严格而普遍的假设,即:
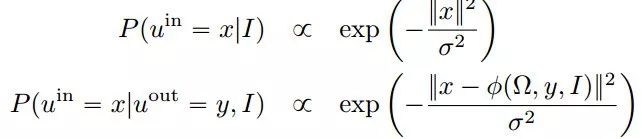
这里假设:
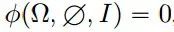
因为给定一个图像,对流的最可能的猜测是零。有了这些假设,以上比率公式可以简化为:
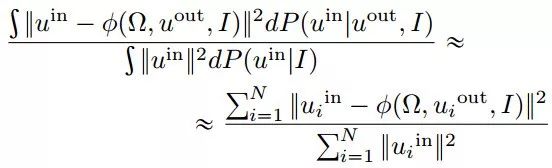
最后要最小化的损失可以近似为:
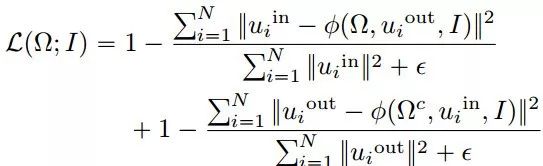
函数类别
根据年龄的特点,选择φ和χ作为深度卷积神经网络的参数函数类,如下图所示:
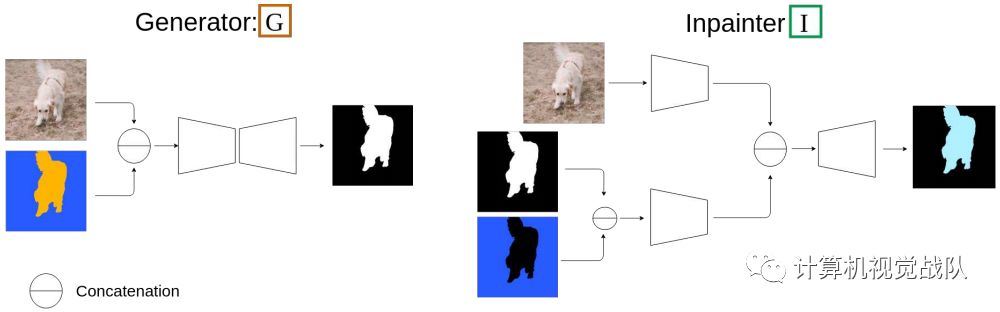
在训练过程中,新方法包含两个模块。一个是发生器(G),它通过观察图像和相关的光流来产生物体的掩膜;另一个模块是Inpainter(I),它试图将由相应的掩模遮住的光流进行回涂。两个模块都采用具有skip连接的编解码结构。然而Inpainter(I)配备了两个独立的编码分支。
我们用w表示参数,以及相应的函数φW1和χw2。因此,在丢弃常数后,negative loss可以写成参数的函数:
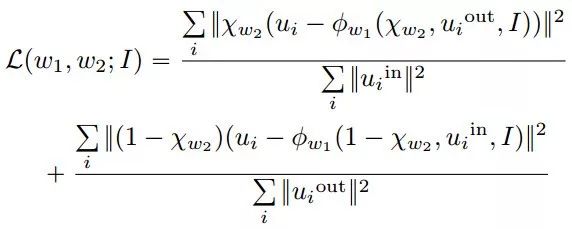
实验
将新方法与一组最先进的基于视频对象分割任务的基线进行比较,以评估检测的准确性。首先在一个controlled toy-example上进行实验,在这个例子中,新模型的假设是完全满足的。本实验的目的是了解所提出的方法在理想条件下的能力。
在第二组实验中,评估了所提出的模型在三个公开、广泛使用的数据集上的有效性:Densely Annotated VIdeo Segmentation (DAVIS)、Freiburg-Berkeley Motion Segmentation (FBMS59)和SegTrackV2。这些数据集提供了它们之间的高度的外观和分辨率差异,是任何运动目标分割方法的一个具有挑战性的基准。虽然Davis数据集每个场景总是有一个对象,但是FBMS和SegTrackV 2场景可以包含每个帧的多个对象。
最后证明新方法不仅优于无监督的方法,而且甚至超过了其他的监督算法,与新算法相比,在训练时能够获得大量的标记数据,并进行精确的人工分割。对于定量评价,使用了最常见的视频对象分割度量。
网络细节
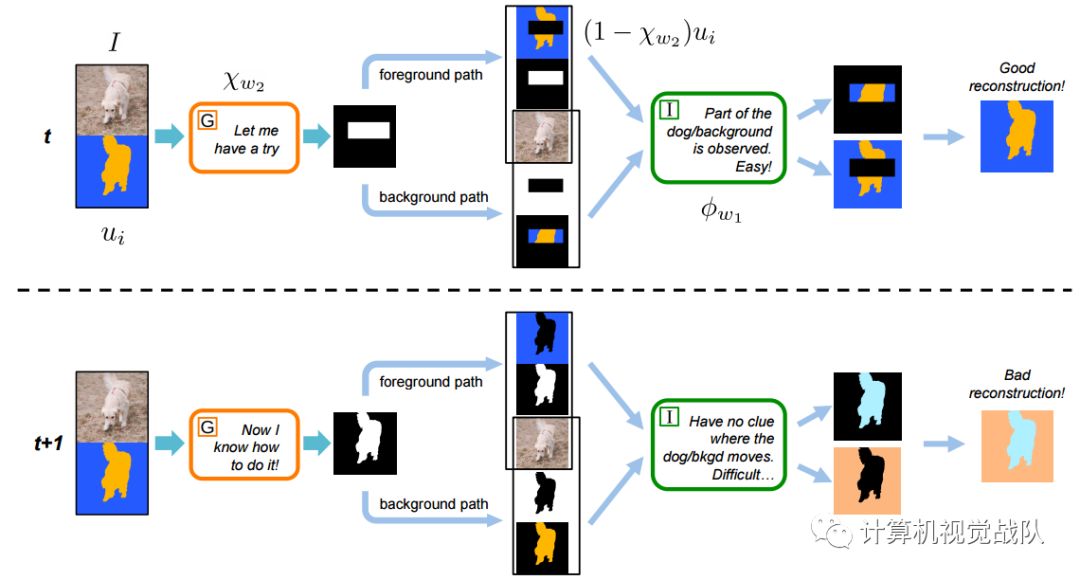
这两幅图说明了掩模发生器(G)的学习过程,这是在Inpainter(I)学会了如何精确地绘制掩模流之后。上面的图表显示了一个训练很差的掩码发生器,它不能精确地检测对象。由于检测精度不高,可以观察到部分物体的流动,并进行精确的重构。同时,Inpainter在互补掩模中部分地观察到背景的流动。因此,它可以准确地预测背景流中缺失的部分。相比之下,下面的图表显示了一个经过充分训练的掩码发生器,它可以精确地将目标和背景区分开来。在这种情况下,Inpainter只观察对象之外的流,并且没有任何信息来预测。
运动目标分割基准:将新方法与8种不同基线的运动目标分割任务进行了比较

运行时间分析


可视化结果
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!

论文地址
http://openaccess.thecvf.com/content_CVPR_2019/papers/Yang_Unsupervised_Moving_Object_Detection_via_Contextual_Information_Separation_CVPR_2019_paper.pdf
代码
http://rpg.ifi.uzh.ch/people_scaramuzza.html

