
简介: 计算机视觉研究大多都集中在不重叠的目标对象上,然而,目标对象却不足以描述丰富的视觉知识,于是,研究者就通过语言特征来获取更多的信息。通过图片与文字叙述相结合的多模态信息融合来获取一个场景图谱。
场景要旨的吸引人的想法的困难在于,关于“要旨”的内容尚无共识。 场景中某些对象应至少是要点的一部分。必须将对象之间的某些关系编码为要点。 即使将所有物体都相同,所要表达的含义却不同。
图表示学习无处不在:
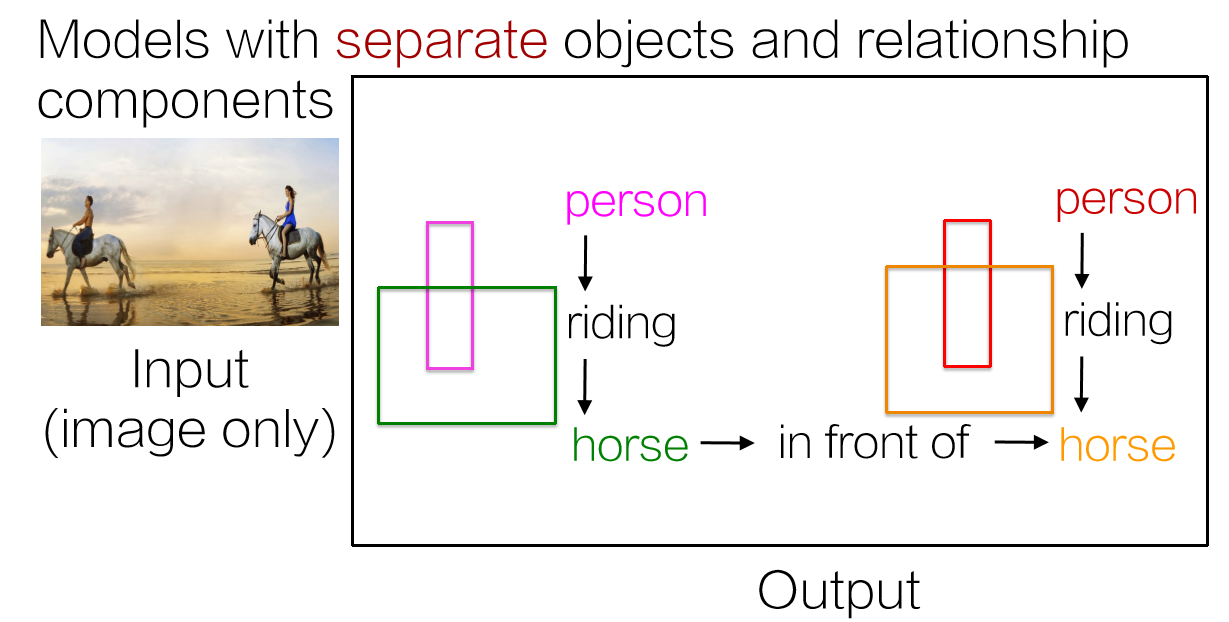
对具有独立对象和关系的特征进行学习,将获得一个场景图谱:
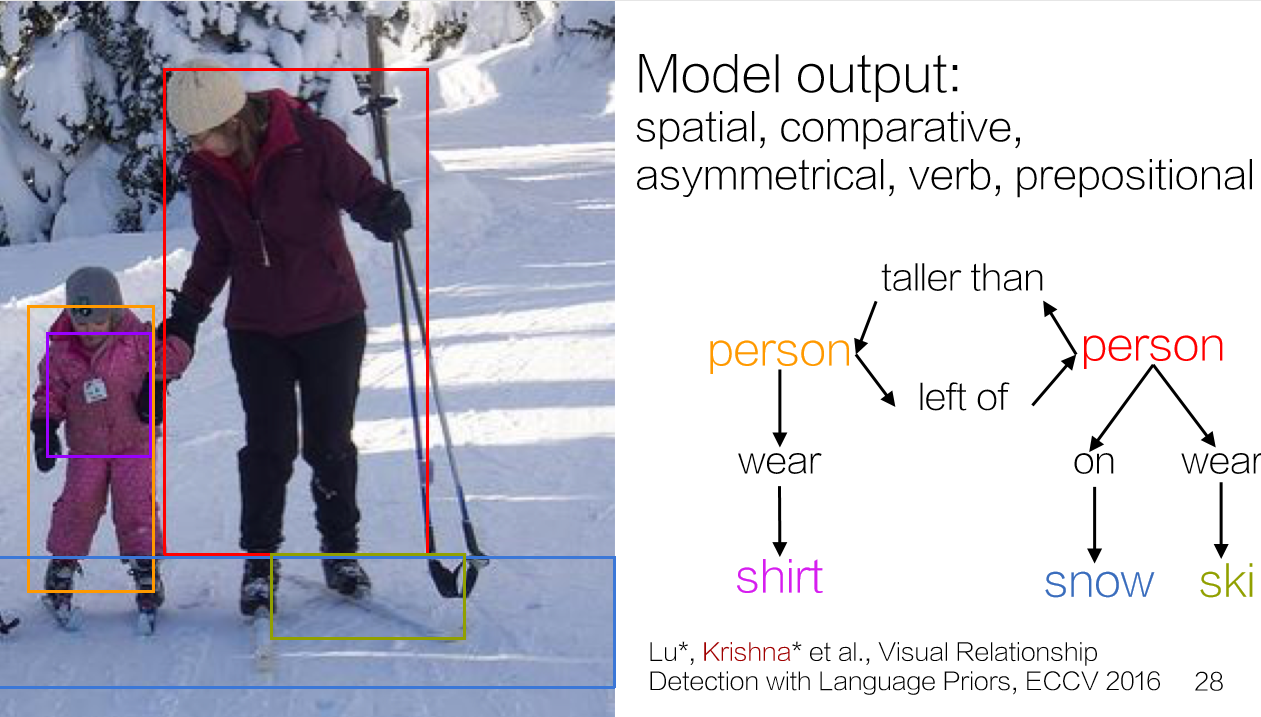
成为VIP会员查看完整内容



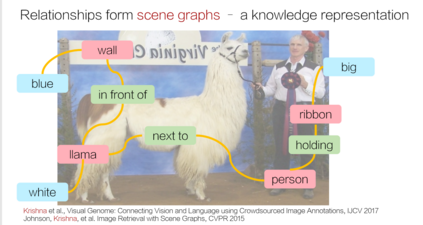
相关内容

Arxiv
7+阅读 · 2018年1月28日




相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2018年1月28日