本文介绍的是CVPR 2020上收录的论文《Cops-Ref: A new Dataset and Task on Compositional Referring Expression Comprehension》(已开源),文章第一作者是香港大学的陈振方同学,这项工作是陈振方同学在澳大利亚阿德莱德大学吴琦老师组访问时所完成。
![]()
论文链接:
https://arxiv.org/abs/2003.00403
数据以及代码链接:
https://github.com/zfchenUnique/Cops-Ref.git
目标物指代理解(referring expression comprehension)是vision-language领域的一个重要任务。给定一个自然语言的描述,目标指向理解期望准确地在一张图像中找到描述对应的区域。模型需要对文本和视觉领域来进行联合理解和推理。然而现在的一些公开数据集并不能很好地检验模型的理解和推理能力。其主要原因为:
1)现存数据集通常仅描述对象的一些简单的独特属性,没有复杂的逻辑推理关系;
2)图片中仅包含有限的干扰信息,仅包含一两个和目标区域同类别的区域。
为了解决这两个问题,我们提出了一个新的任务和数据集(Cops-Ref),来更好地检验模型的感知和推理能力。这个新的数据集有两个特点。
首先,我们设计了一个新颖的文本生成引擎。它能组合各种推理逻辑和丰富的视觉特征,来产生不同的组成复杂度的文本描述。
其次,我们提出了一种新的测试设置,在测试过程中添加语义相似的视觉图像进行干扰,以便更好地检验模型是否完全理解文本描述中完整的推理链。
![]()
图一:Cops-Ref数据集的一个例子。Cops-Ref需要模型从一组图像中找到一个和给定的组成文本描述语义对应的区域。这组图像不仅包含目标图像还包含一些具有不同程度干扰因素的图像。
跟现存数据集相比,Cops-Ref构建主要包含两部分:1) 具有复杂和不同组成程度的文本描述的生成;2)包含和目标区域语义相似的干扰图像的选取。
文本描述生成引擎:为了生成合适的文本描述,我们开发了一个文本描述生成引擎。它能产生语法正确、没有歧义和不同复杂程度的文本描述。
具体而言,给定一个待描述的区域,我们首先从一组提前定义好的逻辑形式中选取一个语言模板;然后,我们把目标物体所代表的节点作为根节点,向外拓展,从场景图(scene graph)获取一个特定的推理树。该推理树包含了模板所需的语义内容。最后,我们把推理树包含的语义内容填写到特定的模板中。
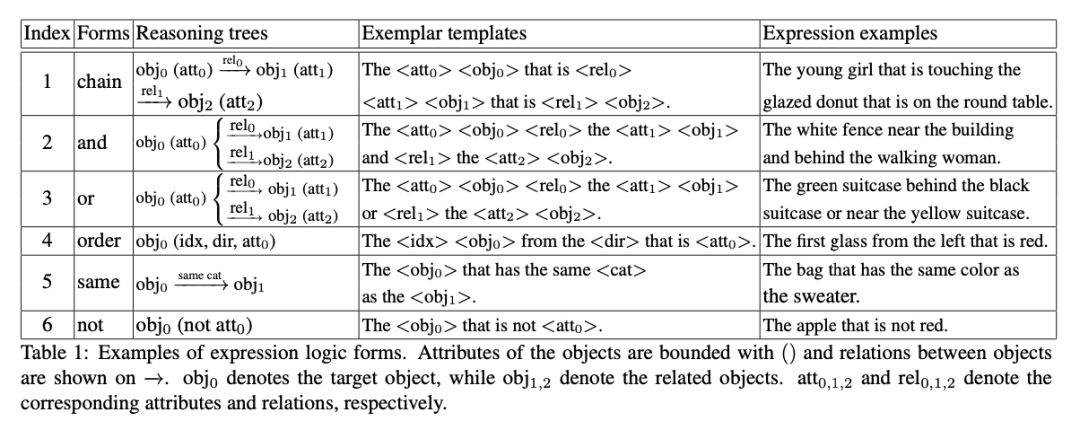
表一提供了所定义的六种逻辑形式,它们的推理树以前相对应的一个语言模板和语言生成例子。这些逻辑形式又可以进一步互相组合,形成更复杂的文本描述。
![]()
干扰图像的选取:干扰图像的引入保证了只有能够完整理解整个文本描述 和区分细小的视觉差异的模型,才能在Cops-Ref数据上取得好的效果。
1. 和目标区域不同类别的干扰图像;
2. 包含和目标区域相同类别区域的干扰图像;
3. 包含同样类别和属性区域的干扰图像;
4. 包含文本描述对应推理树所有的物体类别,但是物体之间存在不同关系的干扰图像。
这些干扰图像能够检验模型的不同方面的能力,如物体识别、属性鉴定和关系提取。图一列举了不同的干扰图像。
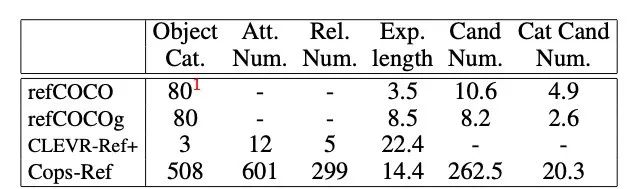
Cops-Ref数据集包含75,299张真实图片、148,712条文本描述和1,307,885个候选区域。这使得Cops-Ref成当前最大的目标物指代理解数据集。文本描述的平均长度为14.4个单词及词库的大小为1596。
我们进一步比较Cops-Ref和现有的Ref-COCO[5]和Ref-COCOg[3]。表二显示比较的结果。如表二所示,Cops-Ref具有更加广泛的物体类别、属性和相互关系。此外,Cops-Ref的文本描述 长度和候选区域数目也远大于refCOCO和refCOCOg等真实图像数据集。
![]()
表二:refCOCO、refCOCOg、CLEVR-Ref和Cops-Ref的统计 比较
![]()
![]()
![]()
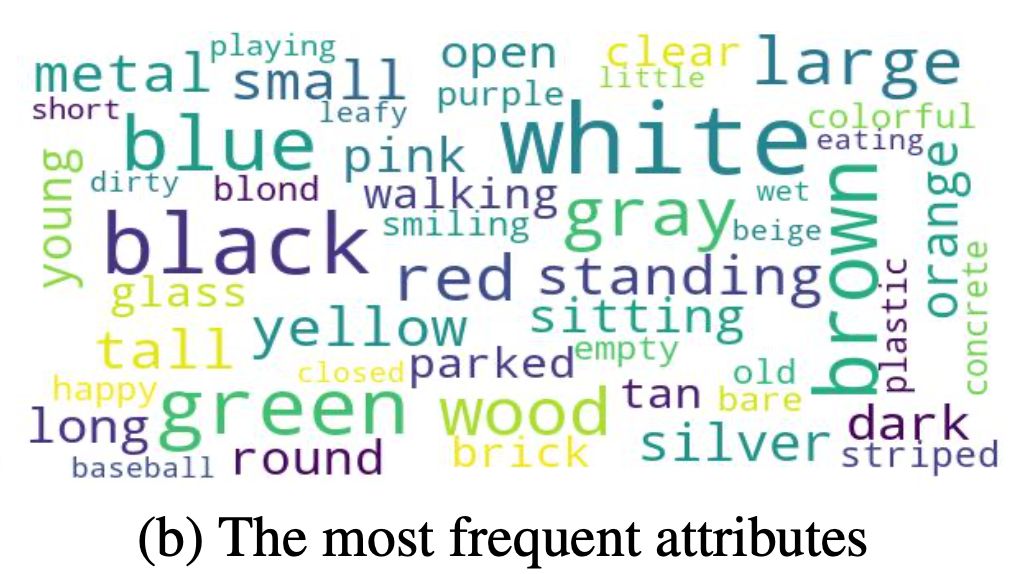
图2: Cops-Ref中最常出现的物体,属性以及关系
尽管Cops-Ref需要模型从一组图像中找到一个和给定的组成文本描述语义对应的区域,现存的Ref模型(referring expression comprehension)能通过比较每张图像包含区域和文本描述,选取匹配分数最高的区域来作为Cops-Ref任务的结果。
为了处理Cop-Ref任务,我们基于MattNet [1]提出了一种新的模块化hard-mining策略来提升模型的效果。MattNet是解决目标物指代理解的经典模型,它把文本描述分为三个模块,包括主语(sub)、位置(loc)和物体关系(rel)并对其分别建模,计算候选区域和每个模块的相似度。其中文本描述q和第j个候选区域的相似度定义为:
![]()
其中
![]() ,
,
![]() 为第md个模块的权重和
为第md个模块的权重和
![]() 为模块化的文本编码。
基于MattNet,我们根据模块化的文本特征之间的相似度来选取训练所需要的负样本文本描述和图像区域。每个文本和及其相对应的图像区域选取的概率为:
为模块化的文本编码。
基于MattNet,我们根据模块化的文本特征之间的相似度来选取训练所需要的负样本文本描述和图像区域。每个文本和及其相对应的图像区域选取的概率为:
![]()
其中
![]() 代表第m个文本描述的md模块的文本特征,
代表第m个文本描述的md模块的文本特征,
![]() 表示本文特征
表示本文特征
![]() 和
和
![]() 的cosine相似度,
的cosine相似度,
![]() 代表第n个文本及其相对应的图像候选区域的采样概率和
代表第n个文本及其相对应的图像候选区域的采样概率和
![]() 代表训练数据集中和第m个文本对应的图像区域对具有同样物体类别的文本描述数目。
然后我们定义一个新的模块化hard-ming损失函数为:
代表训练数据集中和第m个文本对应的图像区域对具有同样物体类别的文本描述数目。
然后我们定义一个新的模块化hard-ming损失函数为:
![]()
这个模块化损失函数和MattNet[1]的原本损失函数相结合,作为模型的新的损失函数。原本的损失函数在于训练区分同一图像中的干扰区域,而新的模块化的损失函数区分来自干扰图像的语义相似区域。
如表二所示,实验主要包括两部分,一是数据集bias的分析,而是现存模型在 Cops-Ref上的表现。
Bias 分析:我们挑选最简单的CNN-RNN 模型,Grounder[2]作为测试模型的基准线。通过详细的对比,我们发现Cops-Ref比现存的Ref-COCOg[3]具有更小的Bias。其对文本描述的单词顺序和关系更加敏感。句法结构在数据集的性能中扮演更关键的作用。
![]()
模型性能比较:通过比较几个现有模型的性能,我们有以下的发现:
1)GroundeR, MattNet和 CM-Att-Erase[4]模型性能逐渐提升,这与它们在Ref-COCOg上的表现是一致的;
2)当增加包含同类别的干扰图像时,模型的性能急速下降,这表明现存模型更多的是依赖物体和属性识别来分辨图像区域;
3)我们所提出的模块化hard-ming strategy 能够有效地提升模型识别干扰图像的能力。
我们提出了一个新的任务和数据集Cops-Ref。这个数据集具有两个不同的特性:
1) 具有复杂和不同组成程度和逻辑推理的文本描述;
为了更好处理这个新的任务,我们提出了一种新的hard-ming策略,它能有效地提高模型区分干扰图像的能力,在新的数据集上取得目前最好的结果。然而其性能仍有待未来工作的进一部分提升。
[1] Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L Berg. Mattnet: Modular attention network for referring expression comprehension. In CVPR, 2018.
[2] Anna Rohrbach, Marcus Rohrbach, Ronghang Hu, Trevor Darrell, and Bernt Schiele. Grounding of textual phrases in images by reconstruction. In ECCV, 2016.
[3] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation
and comprehension of unambiguous object descriptions. In CVPR, 2016.
[4] Xihui Liu, Zihao Wang, Jing Shao, Xiaogang Wang, andHongsheng Li. Improving referring expression grounding with cross-modal attention-guided erasing. InCVPR, 2019
[5] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions.In ECCV, 2016.
CVPR 2020 系列报道
相关报道:
论文集:
论文解读:
11. 室内设计师失业?针对语言描述的自动三维场景设计算法
![]()
![]()
![]() 点击“阅读原文” 查看 更多论文解读
点击“阅读原文” 查看 更多论文解读