【泡泡点云时空】利用超点图的大场景点云语义分割(CVPR2018-5)
泡泡点云时空,带你精读点云领域顶级会议文章
标题:Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs
作者:Loic Landrieu, Martin Simonovsky
来源:CVPR 2018
编译:赵传
审核:李敏乐
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

我们提出一种新的基于深度学习的框架以解决上百万点的大场景点云语义分割面临的挑战。我们证明了点云的组织可以有效地通过一种称为超点图(superpoint graph, SPG)的结构进行描述,SPG从扫描场景分割成的几何同质元素中得到。SPGs提供一种紧致且具有丰富的描述不同目标部分上下文关系的表达,并为一个图卷积神经网络所利用。我们的框架得到了目前室外及室内LiDAR扫描点云分割的最好结果(Semantic3D点云上提高了11.9%和8.8%,S3DIS数据集上提高了12.4%)。
现有方法存在的问题
目前大数据量三维点云分割存在的问题:
(1)将三维点云转换到二维格式会造成信息的损失并需要进行表面重建,而这是和语义分割具有相同难度的一个问题。
(2)点云的体素化表达效率较低并趋向于丢失小细节。
(3)专为三维点云设计的深度学习框架可以得到较好的结果,但是受到一次可处理的输入点云数的限制。
算法流程
本文提出一种将大场景三维点云用一系列相互联系的简单形状构成超点的表达方式,这种表达方式与影像分割中的超像素类似。如图1所示,这种结构可以由一种称为超点图(superpoint graph, SPG)的属性有向图结构描述。超点图的节点代表简单的结构,而富有边特征的边描述了它们的连接关系。

图1:本文方法的流程图。(a)是输入点云.(b)是几何分割的结果,为单个简单形状,也称为超点.(c)基于得到的超点,由具有丰富属性的超边连接相邻的超点形成的超点图(superpoints graph, SPG).(d)超点被转换为紧致的嵌入式,由图卷积处理以利用上下文信息,并分类得到语义标签.
主要贡献
SPG的优势
SPG的表达方式有以下几个显著的优点。(1)SPG将整个目标的部分作为一个整体,这更加容易辨别,而不是对单个点或者体素进行分类;(2)SPG可以详细描述相邻目标之间的关系,这对于上下文分类至关重要:车辆通常是在道路上,天花板由墙面包围,等;(3)SPG的大小由场景中的简单结构的数量决定,而不是场景中所有的点,这通常会要小几个量级。这使得我们可以对长距离的交互进行建模,而这在没有强假设的成对连接中是很难实现的。
本文的贡献在于:
(1)我们提出超点图(superpoint graph, SPG),一种由富有特征的表对三维点云中对象的部分进行上下文关系编码的新的点云表达方式;
(2)基于SPG这种表达方式,我们可以在不损失主要精细细节的情况下对大场景的点云运用深度学习进行处理。我们的结构包括用PointNet进行超点嵌入和用于上下文分割的图卷积。对于后者,我们提出一种新的,更加有效的条件边卷积以及一种在门循环单元(Gated Recurrent Units, GRU)中的新的输入门形式;
(3)我们在两个可公开获得的数据集(Semantic3D和S3DIS)上取得了目前最好的结果。特别地,我们在简化的Semantic3D测试数据集上的mIoU指标提高了11.9%,在Semantic3D整个测试数据集上提高了12.4%,在S3DIS数据集上提高了12.4%。
主要结果
表2和表3为在数据集Semantic3D和S3DIS上不同方法的精度统计结果
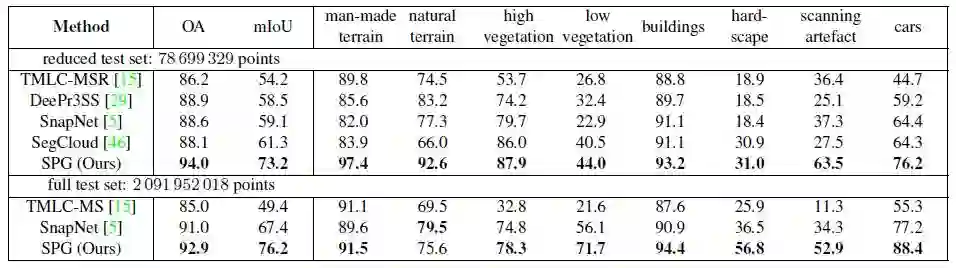
表2:Semantic3D数据集上的结果与其他方法的对比,OA代表整体精度,mIoU是每一类别未加权的平均IoU。

表3:S3DIS数据集上的结果与其他方法的对比
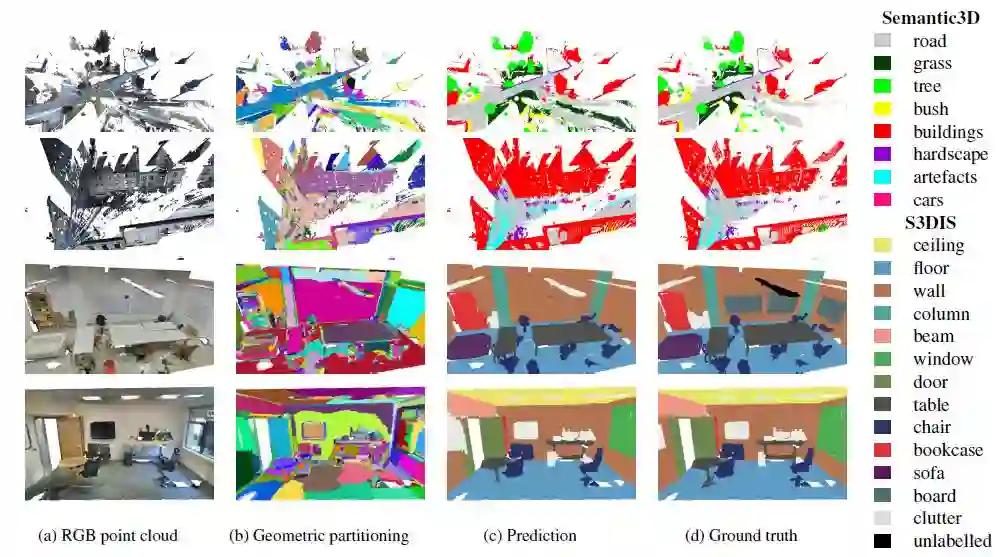
图3:在Semantic3D和S3DIS数据集中的部分结果,(b)中每种颜色代表一个分割块。

Abstract
We propose a novel deep learning-based framework to tackle the challenge of semantic segmentation of largescale point clouds of millions of points. We argue that the organization of 3D point clouds can be efficiently captured by a structure called superpoint graph (SPG), derived from a partition of the scanned scene into geometrically homogeneous elements. SPGs offer a compact yet rich representation of contextual relationships between object parts, which is then exploited by a graph convolutional network. Our framework sets a new state of the art for segmenting outdoor LiDAR scans (+11:9 and +8:8 mIoU points for both Semantic3D test sets), as well as indoor scans (+12:4 mIoU points for the S3DIS dataset).
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




