赛尔原创|数据到文本任务的近期相关工作介绍
作者:哈工大SCIR龚恒,陈双
在数据到文本的任务上,近期有三个数据集值得注意:E2E数据集[1]、WikiBio[2]数据集以及RotoWire[3]和SBNation[3]数据集。在SIGDIAL 2017上Heriot-Watt大学发表了一篇名为The E2E Dataset: New Challenges For End-to-End Generation[1]的论文,介绍其构建的面向餐馆描述领域的E2E数据集,每一条数据都对应多个参考文本。在2016年的EMNLP会议上,Facebook AI发表一篇名为Neural Text Generation from Structured Data with Application to the Biography Domain[2]的论文。这篇论文构建并发布了一个数据集WikiBio。在Data-to-Text领域,传统的数据集如WEATHERGOV和ROBOCUP的数据量较小,最大仅为几万条数据。WikiBio通过抽取维基百科的infobox和正文第一段话,自动化地构建了一个大型平行语料库,包含了超过70万条平行数据和超过40万的词表。在2017年的EMNLP会议上,Harvard NLP发表了一篇名为Challenges in Data-to-Document Generation[3]的论文,提出了RotoWire和SBNation数据集,前者收集的是专业人士撰写的NBA赛事报道,而后者收集的是粉丝撰写的赛事简要。与上述数据集不同的是,该数据集中的文本平均长度在337以上,显著长于上述数据集。以下主要对在这三个数据集上目前已发表的部分工作进行简要的总结。
一、数据集介绍
1. E2E数据集
下载地址:http://www.macs.hw.ac.uk/InteractionLab/E2E/#register
数据大小:如表1
表1 E2E数据集数据大小

数据介绍:
输入:餐馆信息的表示
输出:对餐馆的自然语言描述

图1 E2E数据集数据介绍
2. WikiBio数据集
下载地址:https://github.com/DavidGrangier/wikipedia-biography-dataset
数据大小:如表2
表2 WikiBio数据集数据集大小

数据介绍:
输入:维基百科的infobox
输出:传记的第一句话
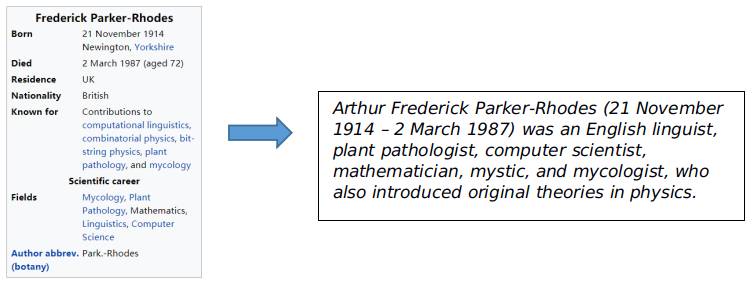
图2 WikiBio数据集数据介绍
3. RotoWire和SBNation数据集
下载地址:https://github.com/harvardnlp/boxscore-data
数据大小:
表3 RotoWire数据集数据大小

表4 SBNation数据集数据大小

数据介绍:
输入:一场NBA比赛的数据
输出:一段对比赛情况的描述
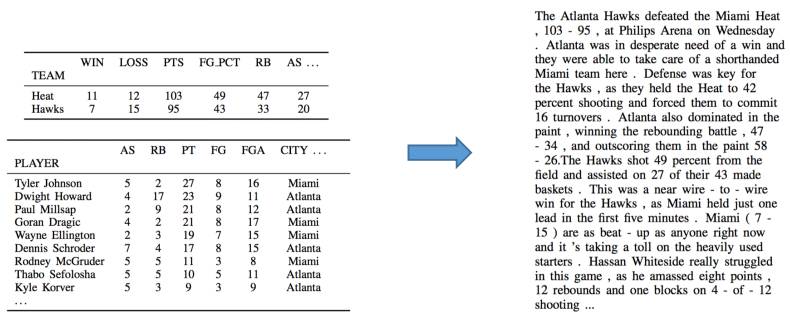
图3 RotoWire和SBNation数据集数据介绍
二、主要方法总结
1. E2E数据集
基线模型TGen[4]在引入Attention机制的序列到序列模型的基础上,在测试阶段进行beam search的时候加入了Reranker机制以选择与餐馆信息更为一致的生成的内容。首先,餐馆信息按照顺序送入encoder,每一条信息用动作、类型、值进行表示。例如对于输入的餐馆信息name=X-name, eattype=restaurant,送入encoder的序列是inform、name、X-name、inform、eattype、restaurant。Encoder部分采用LSTM,用最后一步的输出初始化Decoder部分。Decoder部分使用LSTM并融入Attention机制,生成对于餐馆信息的介绍。在测试的时候,作者使用一个RNN对于beam中生成的每一条结果针对训练集中出现过的所有餐馆信息类型进行多个二分类,判断生成的结果中包含了哪些信息。然后通过计算与输入的餐馆信息对应表示的编辑距离来对beam中生成的每条结果进行惩罚。
2. Wikibio数据集
Facebook AI的论文[2]采用了条件神经网络语言模型建模这一任务。具体来讲,主要是以表格信息为条件,进行文本生成。其中,表格信息以局部条件(local conditioning),和全局条件(global conditioning)加入到条件神经网络模型中。局部条件主要描述之前生成的词与infobox之间的关系,具体通过表示词在表中所出现的域(field)、和域中的起始位置和终止位置来进行建模。而全局条件则希望对表格的整体信息进行表示,通过表格中所有出现的域和词来刻画这个人的一些特性,例如这则传记是关于一位科学家还是艺术家。同时为了处理词表过大和低频词问题,这篇论文设计了一种拷贝动作(copy action)来使模型具备拷贝表中出现过的词的能力。
在2018年的AAAI会议中,有几篇论文在此数据集上对模型作出了进一步的探索和改进。其中Lei Sha 等人提出的工作[5]对文本生成过程中内容所出现的次序进行了建模。他们主要的研究动机是表格中的数据域本身就包含一种启发式的暗示和对文本生成的约束。如在传记领域,国籍经常在职业之前被提到。具体在模型层面,他们通过引入一个链接矩阵来建模传记文本当中一个域出现在另一域之前的概率。利用链接矩阵,他们进一步提出了一种link-based attention来直接对不同域之间的关系建模。最后在解码的时候,结合linked-based attention与seq2seq模型中正常的注意力机制(这里称作content-based attention)构成一种混合注意力机制(hybrid attention),并据此来计算此刻生成词的概率分布。类似于Facebook AI的这篇工作[2],此篇工作同样引入了一种拷贝机制,不同的是这里他们使用的是CopyNet[6]。
此外,在AAAI 2018中,Tianyu Liu等所提出的工作[7]对表格的结构化表示进行了探索。由于表格与非结构化文本相比是有结构信息的,比如表格中有域名(field name)、域值(field value)的概念。为了将域名的信息融入到表格的表示当中,目前有多种做法,如 Mei等人的工作[8]将表格中的记录表示成固定长度的one-hot向量,并利用循环神经网络对输入表格进行编码;Lei Sha等人的工作[5]则单独设计了两个针对域名和域值编码矩阵,最后将域名和域值的表示向量连接起来送入循环神经网络中进行编码;Tianyu Liu的这篇工作希望设计一种更有效的结构化表示方法,他们的论文借鉴了Facebook AI论文中表格表示的思想,但是在循环神经网路中进行建模。具体在模型方面,他们使用具有域门机制(field-gating)的编码器来使域名信息可以直接影响LSTM的cell state。同时,他们还引入了一种对偶注意力机制来融合表格中的内容信息和域信息。
3. RotoWire数据集和SBNation数据集
Harvard NLP[3]的论文在两个数据集上提供了六个基线模型。基础的模型是一个引入attention机制的encoder-decoder模型。作者采用了两种不同的Copy方式。其中Conditiona Copy和Joint Copy不同的地方在于前者计算生成和复制的概率的时候,引入了判断某个词来自生成模型或来自复制模型的概率作为条件。在Joint Copy的基础上,还加入了Reconstruction Loss和TVD(Total Variation distance)。前者通过decoder的隐含层还原输入的表格中的信息,并且可以通过后者对reconstruction loss进行惩罚。作者同时还针对这个数据集,提出了一套模版作为其中的一个基线。
三、实验结果简要总结
1. E2E数据集
在这一数据集上,目前主要采用自动化评价方法,包括BLEU[9],NIST[10],ROUGE_L[11],METEOR[12],CIDEr[13]。表5是基线模型在开发集上的实验结果。
表5 E2E目前已发表工作的实验结果汇总(开发集)

表6是基线模型在测试集上的实验结果。
表6 E2E目前已发表工作的实验结果汇总(测试集)

2. Wikibio数据集
在这一数据集上,目前主要采用自动化评价的方法,具体使用机器翻译任务和文本摘要任务上的一些指标,如BLEU[9],NIST[10] ,ROUGE[11] 等。同时以上论文也通过举例子和可视化的方法来对实验结果进行定性分析。表7是部分目前已发表论文的实验结果汇总。
表7 Wikibio目前已发表工作的实验结果汇总(*代表论文中没有报相应指标的结果)
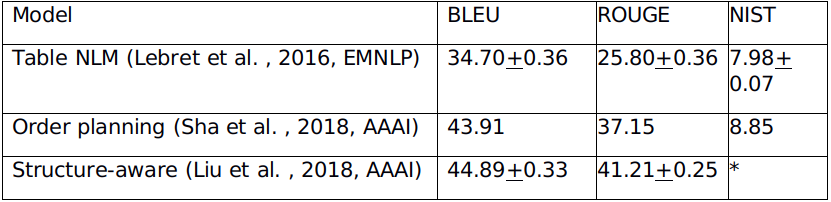
3. RotoWire数据集
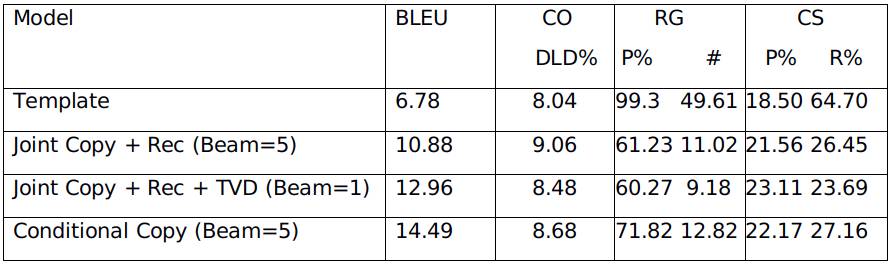
在这一数据集上,作者采用BLEU[9]作为自动化评价指标,并且提出了三个抽取式的评价指标分别是内容选择指标CS(评价模型选择重要信息的能力)、关系生成指标RG(评价模型生成正确信息的能力)和内容顺序指标CO(评价模型对于控制表格信息表达顺序的能力)。表8是多个基线模型在测试集上的实验结果。
表8 RotoWire基线模型自动化评价结果
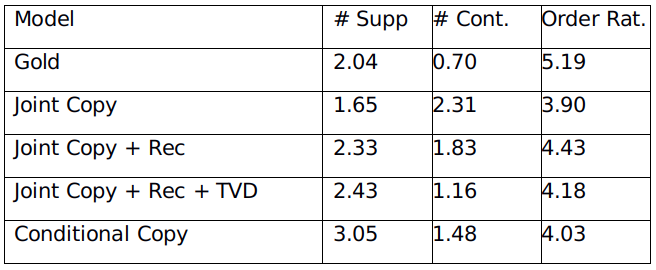
作者还提供了人工评价的结果(如表9所示),# Supp代表生成的每个句子中有多少条信息和表格中的信息一致,# Cont表示生成的每个句子中有多少条信息和表格中的信息有冲突。Order Rat.代表用户对生成内容中来自表格的信息的表述顺序的自然度打分,分数范围为1-7。
表9 RotoWire基线模型人工评价结果
四、主要参考文献
[1].Novikova, J., Dušek, O., & Rieser, V. (2017). The E2E Dataset: New Challenges For End-to-End Generation. arXiv preprint arXiv:1706.09254.
[2].Lebret, R., Grangier, D., & Auli, M. (2016). Neural text generation from structured data with application to the biography domain. arXiv preprint arXiv:1603.07771.
[3]. Wiseman, S., Shieber, S. M., & Rush, A. M. (2017). Challenges in data-to-document generation. arXiv preprint arXiv:1707.08052.
[4]. Dušek, O., & Jurčíček, F. (2016). Sequence-to-sequence generation for spoken dialogue via deep syntax trees and strings. arXiv preprint arXiv:1606.05491.
[5].Sha, L., Mou, L., Liu, T., Poupart, P., Li, S., Chang, B., & Sui, Z. (2017). Order-planning neural text generation from structured data. arXiv preprint arXiv:1709.00155.
[6].Gu, J., Lu, Z., Li, H., & Li, V. O. (2016). Incorporating copying mechanism in sequence-to-sequence learning. arXiv preprint arXiv:1603.06393.
[7].Liu, T., Wang, K., Sha, L., Chang, B., & Sui, Z. (2017). Table-to-text Generation by Structure-aware Seq2seq Learning. arXiv preprint arXiv:1711.09724.
[8].Mei, H., Bansal, M., & Walter, M. R. (2015). What to talk about and how? selective generation using lstms with coarse-to-fine alignment. arXiv preprint arXiv:1509.00838.
[9].Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics (pp. 311-318). Association for Computational Linguistics.
[10].Doddington, G. (2002, March). Automatic evaluation of machine translation quality using n-gram co-occurrence statistics. In Proceedings of the second international conference on Human Language Technology Research (pp. 138-145). Morgan Kaufmann Publishers Inc..
[11].Lin, C. Y. (2004, July). Rouge: A package for automatic evaluation of summaries. In Text summarization branches out: Proceedings of the ACL-04 workshop (Vol. 8).
[12]. Lavie, A., & Agarwal, A. (2007, June). METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments. In Proceedings of the Second Workshop on Statistical Machine Translation (pp. 228-231). Association for Computational Linguistics.
[13]. Vedantam, R., Lawrence Zitnick, C., & Parikh, D. (2015). Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4566-4575).
本期责任编辑: 张伟男
本期编辑: 吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




