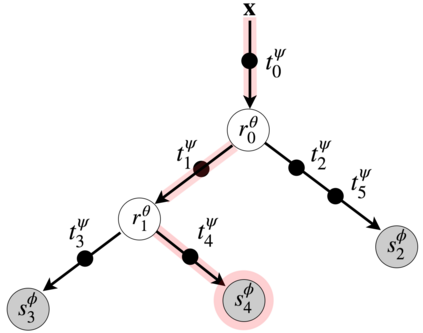
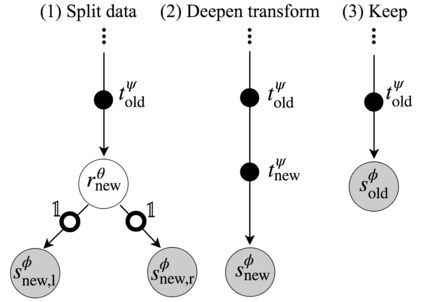
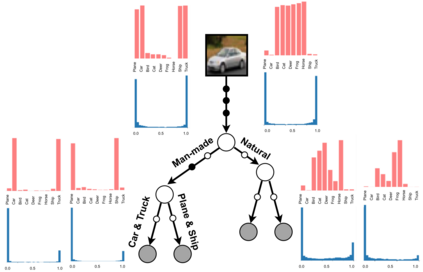
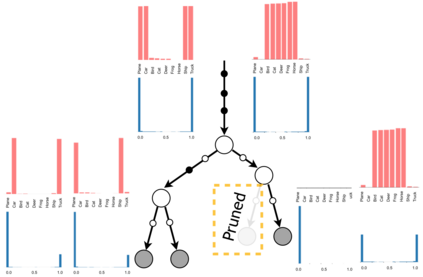
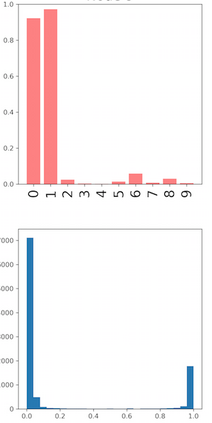
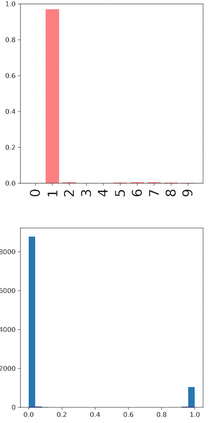
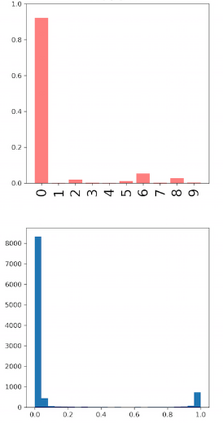
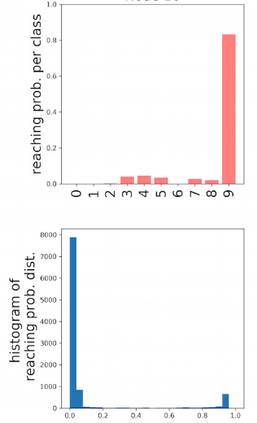
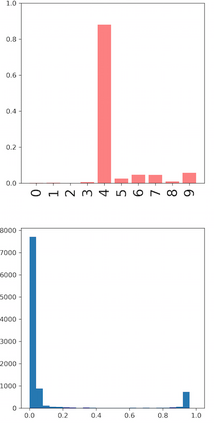
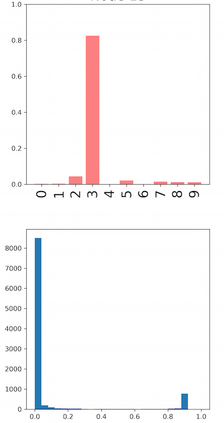
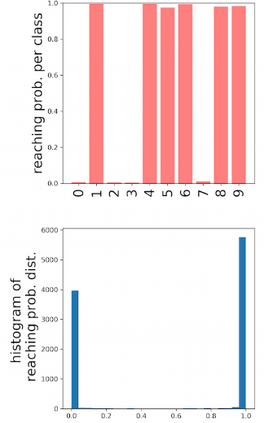
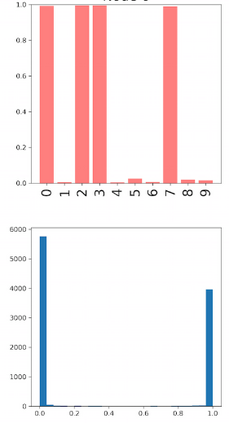
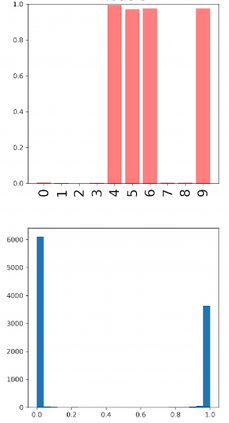
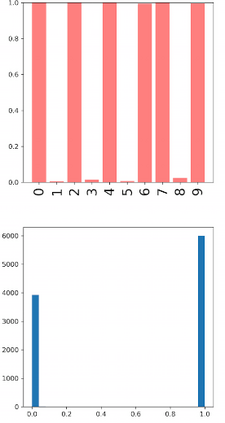
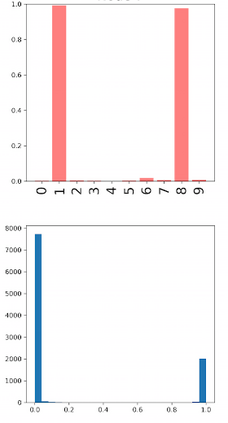
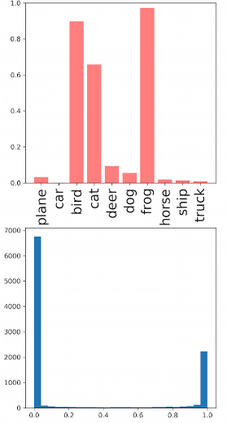
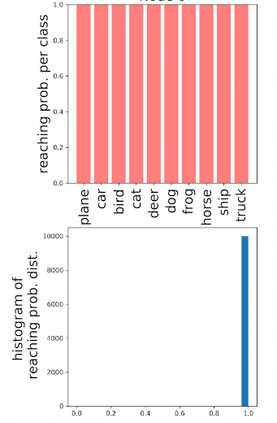
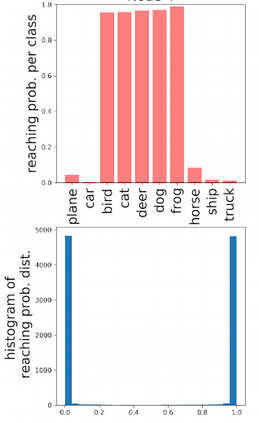
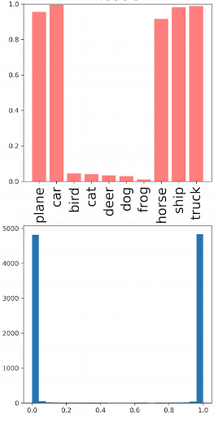
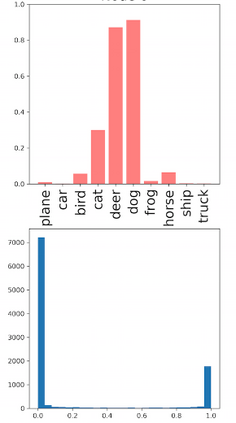
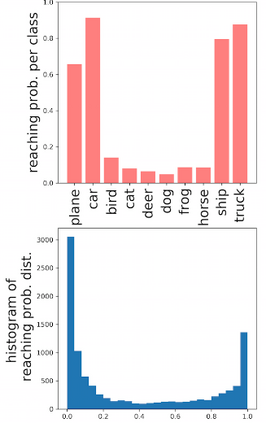
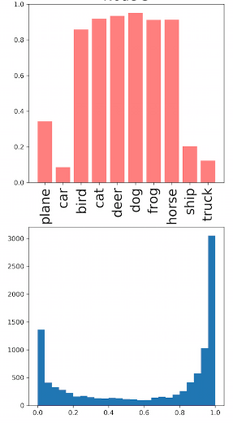
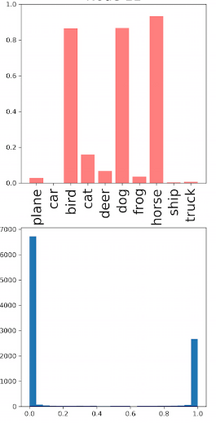
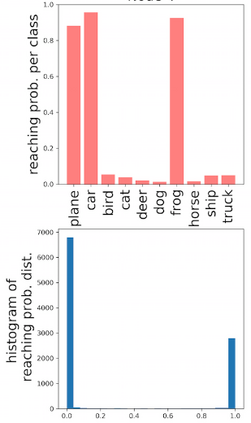
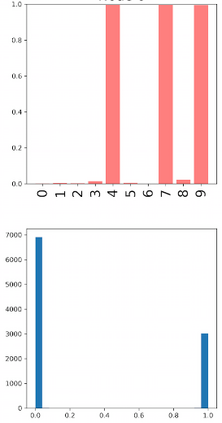
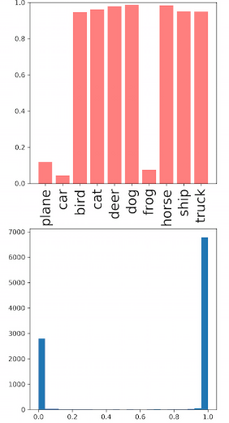
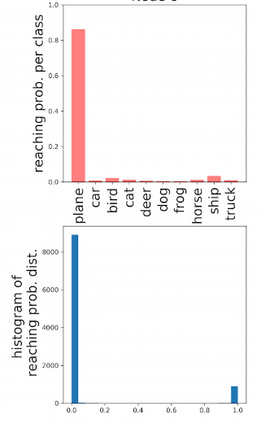
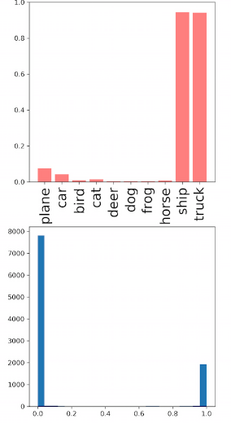
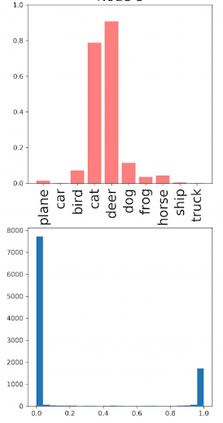
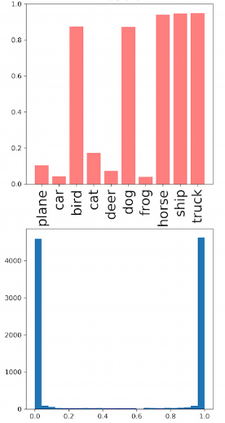
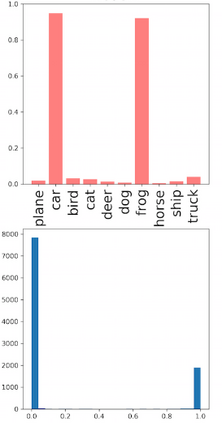
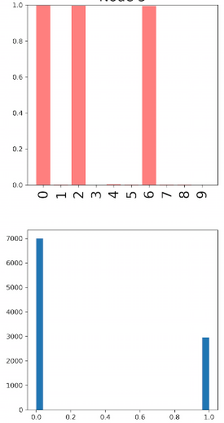
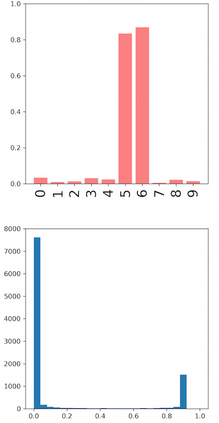
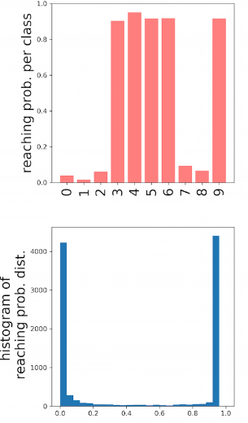
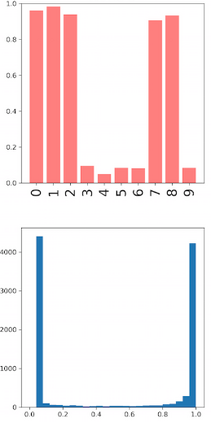
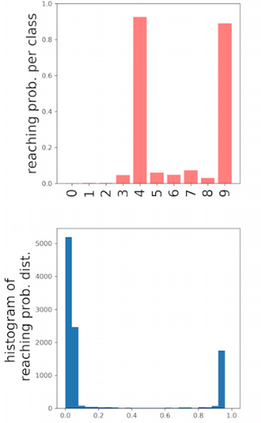
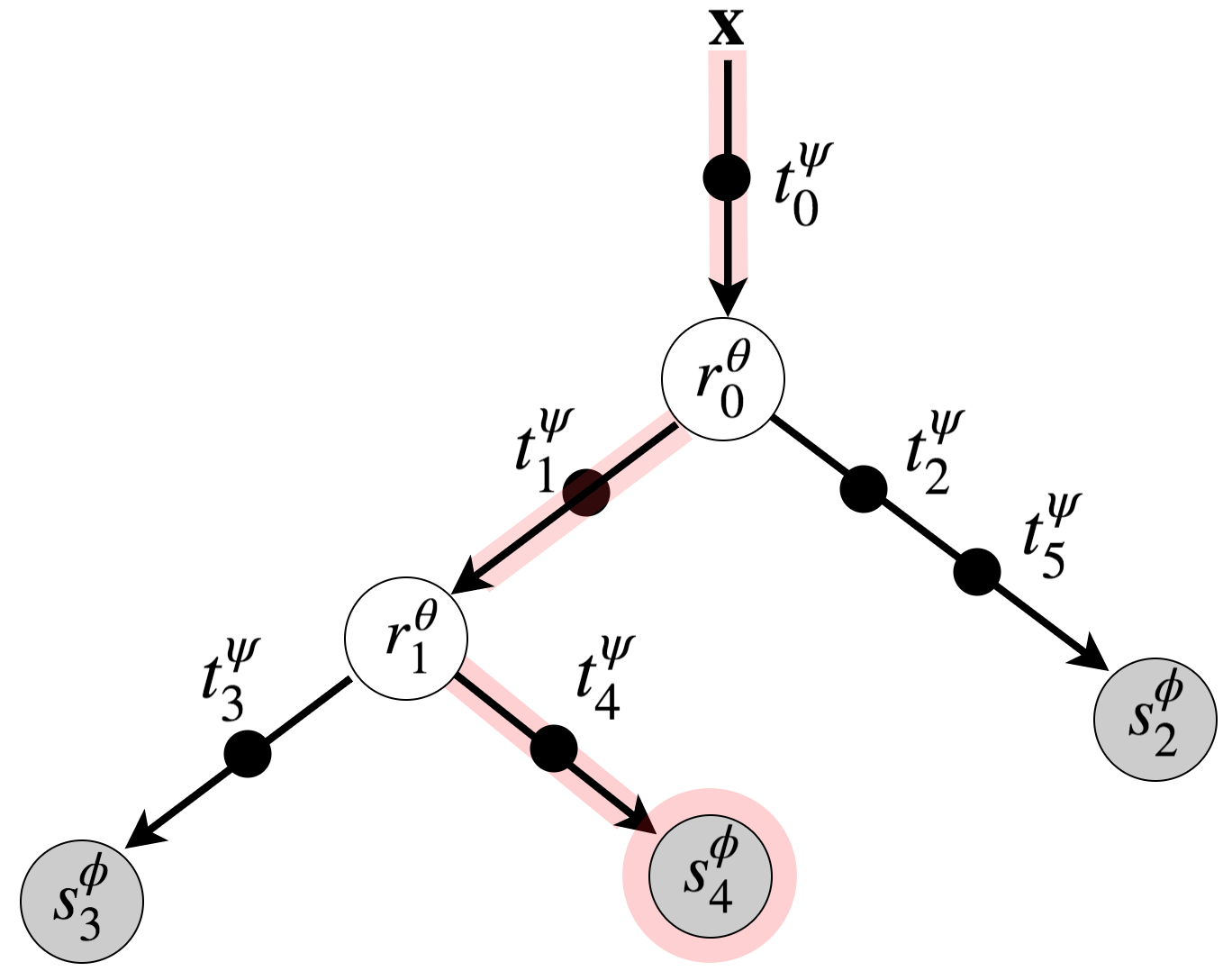
Deep neural networks and decision trees operate on largely separate paradigms; typically, the former performs representation learning with pre-specified architectures, while the latter is characterised by learning hierarchies over pre-specified features with data-driven architectures. We unite the two via adaptive neural trees (ANTs), a model that incorporates representation learning into edges, routing functions and leaf nodes of a decision tree, along with a backpropagation-based training algorithm that adaptively grows the architecture from primitive modules (e.g., convolutional layers). ANTs allow increased interpretability via hierarchical clustering, e.g., learning meaningful class associations, such as separating natural vs. man-made objects. We demonstrate this on classification and regression tasks, achieving over 99% and 90% accuracy on the MNIST and CIFAR-10 datasets, and outperforming standard neural networks, random forests and gradient boosted trees on the SARCOS dataset. Furthermore, ANT optimisation naturally adapts the architecture to the size and complexity of the training data.
翻译:深神经网络和决定树基本上以不同的范式运作;通常,前者采用预先指定的结构进行代表学习,而后者则以通过数据驱动的建筑对预先指定的特征学习等级结构为特征。我们通过适应性神经树(ANTs)将两者结合起来,这个模型将代表学习纳入决策树的边缘、路由功能和叶节,以及基于后向分析的培训算法,从原始模块(例如,共生层)中适应性地生长建筑。 ANTs允许通过等级组合增加解释性,例如学习有意义的阶级联系,例如将自然物体与人为物体区分开来。我们在分类和回归任务上展示了这一点,在MNIST和CIFAR-10数据集方面实现了99%和90%的精确度,在SACOS数据集上超过了标准的神经网络、随机森林和梯度增强的树木。此外,ANT的优化自然使结构适应培训数据的规模和复杂性。